ไขความลับดวงตาจักรกล: Image Classification คืออะไร? สั่งสอน AI ให้แยกแยะภาพฉบับจับมือทำ
1. 🎯 ตอนที่ 8: Image Classification คืออะไร? สั่งสอน AI ให้แยกแยะภาพ
สวัสดีครับน้องๆ วิศวกรสาย Automation และนักพัฒนา AI ทุกคน! ชงกาแฟแก้วโปรดแล้วมานั่งล้อมวงกันตรงนี้ครับ
ในตอนที่ผ่านๆ มา เราได้เรียนรู้คำศัพท์พื้นฐานและทำความรู้จักกับฮาร์ดแวร์กันไปแล้ว วันนี้พี่จะพาน้องๆ เข้าสู่แก่นแท้และเป็นจุดเริ่มต้นของงาน Computer Vision เกือบทุกประเภท นั่นก็คือ Image Classification (การจำแนกประเภทภาพ) ครับ
น้องๆ อาจจะเคยเห็นระบบที่สามารถบอกได้ว่ารูปนี้คือ “หมา” หรือ “แมว” หรือในโรงงานที่กล้องสามารถคัดแยก “สินค้าปกติ” ออกจาก “สินค้ามีตำหนิ” ได้โดยอัตโนมัติ เทคโนโลยีเหล่านี้ทำงานอย่างไร? ทำไมมันถึงแยกแยะของที่มีรูปร่างหลากหลายได้? วันนี้เราจะมาผ่าตัดสมองของ AI เพื่อดูว่ามันมองเห็นและตัดสินใจแยกประเภทภาพได้อย่างไรครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการถึงปัญหาคลาสสิกในโรงงานผลิตชิ้นส่วนอิเล็กทรอนิกส์ดูนะครับ น้องมีสายพานที่วิ่งด้วยความเร็วสูงมาก และมีพนักงาน QC (Quality Control) คอยนั่งจ้องชิ้นงานเพื่อแยก “งานดี (Pass)” กับ “งานเสีย (Defect)” ออกจากกัน ในชั่วโมงแรกพนักงานอาจจะแยกได้แม่นยำเป๊ะๆ แต่พอผ่านไปสัก 4 ชั่วโมง อาการตาล้าเริ่มมา งานเสียหลุดรอดไปถึงมือลูกค้า (Defect Leakage) จนโดนเคลม!
เพื่อแก้ปัญหานี้ เราจึงอยากเอากล้องและ AI มาทำหน้าที่แทน แต่มันไม่ง่ายเลยครับ เพราะเวลามนุษย์มองเห็นรูป “สุนัข” สมองเราจะประมวลผลทันทีว่ามันมีหู มีจมูก มีขน แต่สำหรับคอมพิวเตอร์ สิ่งที่มันเห็นคือ “ตารางตัวเลขขนาดยักษ์ (Matrix of Pixels)” ที่เต็มไปด้วยตัวเลข 0 ถึง 255 ช่องว่างระหว่างความเข้าใจของมนุษย์กับตัวเลขของคอมพิวเตอร์นี้ เราเรียกว่า “Semantic Gap” ครับ
การจะทำให้ AI ข้ามกำแพง Semantic Gap นี้ไปได้ เราจึงต้องใช้ศาสตร์ของ Image Classification เพื่อให้มันตีความตัวเลขเหล่านั้นออกมาเป็น “หมวดหมู่ (Class)” ที่เราต้องการให้ได้นั่นเองครับ!
3. 🧠 แก่นวิชา (Core Concepts)
จากเอกสารตำรา Deep Learning ระดับโลก พี่ขอสกัดคอนเซปต์ของ Image Classification ให้น้องๆ เข้าใจง่ายๆ ดังนี้ครับ:
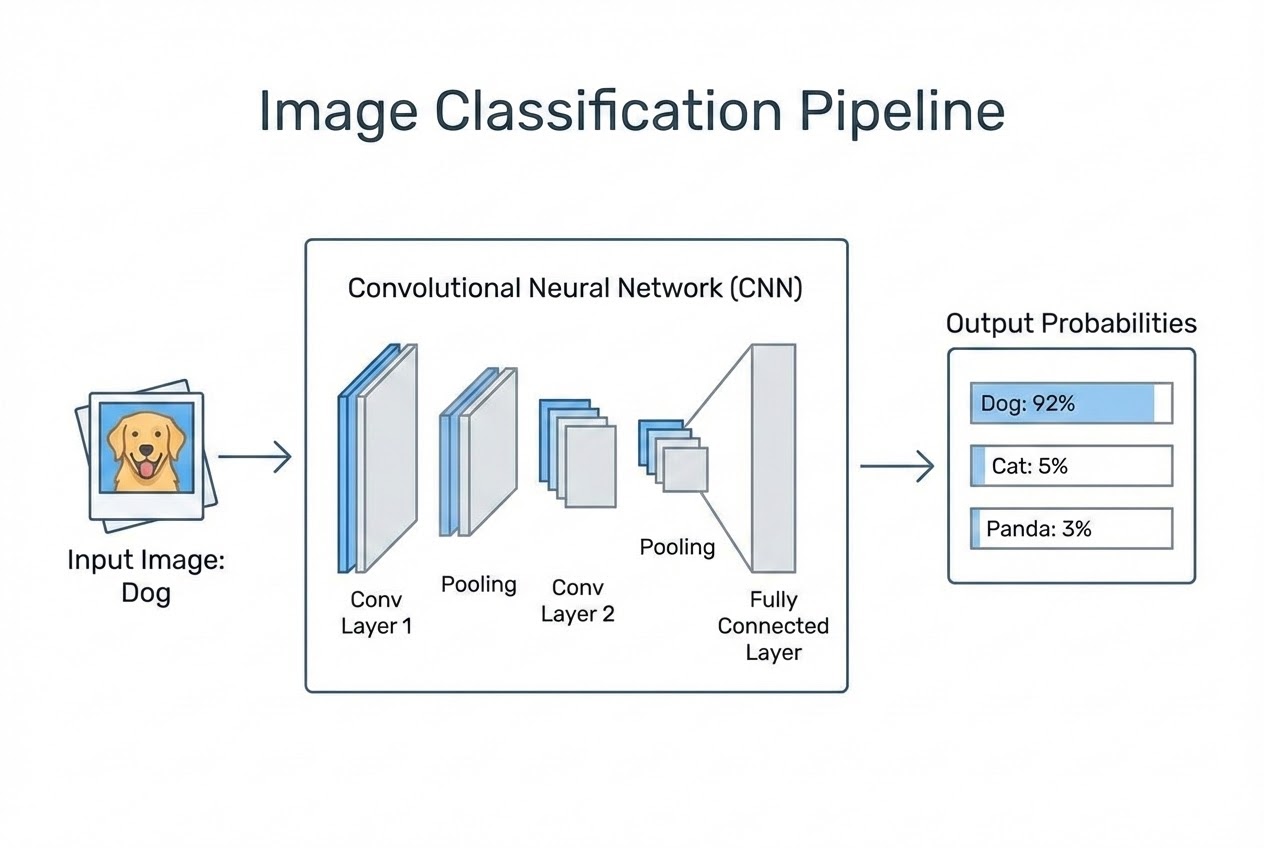
- 1. Image Classification คืออะไร? ตามนิยามแล้ว มันคืองานที่ดึงเอาภาพเข้ามาวิเคราะห์ แล้วระบบจะตอบกลับมาเป็น “ป้ายกำกับ (Label)” จากชุดหมวดหมู่ที่เรากำหนดไว้ล่วงหน้า (Predefined set of categories) ตัวอย่างเช่น ถ้าเรากำหนดให้ระบบรู้จักแค่ {หมา, แมว, แพนด้า} เมื่อเราป้อนรูปหมาเข้าไป ระบบจะต้องพ่นผลลัพธ์พร้อมความน่าจะเป็นออกมา เช่น (หมา: 95%, แมว: 4%, แพนด้า: 1%) เป็นต้น
- 2. กระบวนการคิดของ AI (The Pipeline): ในการทำงานจริง AI จะไม่ได้ท่องจำรูปครับ แต่มันจะทำงานผ่านโครงข่ายประสาทเทียมแบบคอนโวลูชัน หรือ Convolutional Neural Network (CNN) ซึ่งมีหน้าที่ทำ Feature Extraction (สกัดจุดเด่น) โดยชั้นแรกๆ ของเครือข่ายจะมองหาเส้นตรง เส้นโค้ง หรือมุม (Low-level features) พอผ่านชั้นลึกๆ เข้าไป มันจะเอาเส้นเหล่านั้นมาประกอบร่างเป็นรูปทรง เช่น ล้อรถยนต์ หรือ หูของแมว (High-level semantic features) แล้วส่งข้อมูลนี้ให้ Classifier ตัดสินใจในด่านสุดท้าย
- 3. Use Cases ในชีวิตประจำวันและอุตสาหกรรม:
- คัดแยกผลิตภัณฑ์ (Product Sorting): ถ่ายภาพสินค้าบนสายพานเพื่อแยกประเภท หรือตรวจจับว่ามีสินค้าชนิดไหนบกพร่อง (Defect classification)
- การแพทย์ (Medical Imaging): วิเคราะห์ภาพถ่ายเอกซเรย์ (X-ray) หรือภาพสแกนสมอง เพื่อแยกแยะว่าเซลล์ที่เห็นคือ “เนื้องอก (Tumor)” หรือ “เซลล์ปกติ”
- การจัดการคลังภาพ (Image Retrieval & Categorization): คัดแยกและจัดหมวดหมู่รูปภาพนับล้านในเซิร์ฟเวอร์ เช่น Google Photos ที่สามารถแยกรูปสัตว์เลี้ยง สถานที่ หรือบุคคลได้อัตโนมัติ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้เห็นภาพชัดเจนที่สุด พี่จะพาน้องๆ ไปดูวิธีการเขียนโค้ด Python โดยใช้ TensorFlow / Keras ในการโหลดโมเดลระดับโลกอย่าง VGG16 (ที่ผ่านการเทรนมาแล้วจากภาพนับล้านรูปใน ImageNet) มาทำ Image Classification เพื่อทายรูปสุนัขกันครับ! โค้ดสั้นและทรงพลังมาก:
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
from tensorflow.keras.preprocessing.image import load_img, img_to_array
import numpy as np
# 1. โหลดโมเดล VGG16 ที่พรีเทรนน้ำหนัก (Weights) มาจาก ImageNet
print("กำลังโหลดโมเดล VGG16...")
model = VGG16(weights='imagenet')
# 2. โหลดรูปภาพที่เราต้องการทดสอบ (เช่น รูปน้องหมา) และปรับขนาดเป็น 224x224 พิกเซล
# (เพราะ VGG16 ถูกออกแบบมาให้รับภาพขนาดเท่านี้ครับ)
image = load_img('dog.jpg', target_size=(224, 224))
# 3. แปลงรูปภาพให้กลายเป็น Tensor (ตารางตัวเลข) สำหรับป้อนให้ AI
image_array = img_to_array(image)
image_array = np.expand_dims(image_array, axis=0) # เพิ่มมิติ Batch เข้าไป
image_array = preprocess_input(image_array) # ปรับสเกลพิกเซลตามสูตรของ VGG16
# 4. ร่ายมนต์สั่งให้ AI ทายผล (Prediction)
predictions = model.predict(image_array)
# 5. แปลงผลลัพธ์ที่เป็นตัวเลขความน่าจะเป็น กลับมาเป็นชื่อคลาสภาษาอังกฤษ
labels = decode_predictions(predictions, top=3) # เอา 3 อันดับแรกที่มั่นใจที่สุด
print("ผลลัพธ์การแยกแยะประเภทภาพ (Image Classification):")
for (id, label, prob) in labels:
print(f"- {label}: ความมั่นใจ {prob * 100:.2f}%")คอมเมนต์อธิบายสไตล์คุยกัน: เห็นไหมครับน้องๆ! ด้วยพลังของ Deep Learning Framework ยุคใหม่ เราไม่ต้องมานั่งเขียน if-else เช็กพิกเซลทีละจุดอีกต่อไป แค่โหลดโมเดล สกัดฟีเจอร์ แล้วสั่ง predict() เราก็จะได้ชื่อคลาสออกมาเลยอย่างแม่นยำครับ!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในฐานะคนที่เคยเจ็บปวดกับโปรเจกต์ AI หน้างานจริงมาก่อน พี่มีเคล็ดลับและข้อควรระวังมาเตือนน้องๆ ครับ:
- ระวังกับดัก Overfitting (เรียนเก่งแต่ท่องจำ): ถ้าน้องมีรูป “สุนัขหน้าตรง” แบบเดียวให้ AI เรียนรู้ 10,000 รูป โมเดลจะเกิดอาการ Overfitting คือทายถูก 100% ในห้องแล็บ แต่พอไปเจอรูป “สุนัขตะแคงหน้า” ในโลกจริง AI จะทายผิดทันที! วิธีแก้คือการทำ Data Augmentation หรือการเอาภาพเดิมมา บิด, หมุน, พลิกซ้ายขวา, เติม Noise เพื่อบังคับให้ AI สกัดฟีเจอร์ที่เป็นแก่นแท้จริงๆ ไม่ใช่แค่การท่องจำครับ
- Classification ไม่ใช่ Detection นะ! แยกให้ออก:
ปัญหาโลกแตกของมือใหม่คือสับสนระหว่าง 2 คำนี้ครับ!
- Image Classification: จะบอกแค่ว่า “ในรูปนี้มีหมา” (ตอบเป็น Label)
- Object Detection: จะบอกว่า “ในรูปนี้มีหมา และมันอยู่ตรงพิกัด X, Y นี้!” (ตอบเป็น Label พร้อมลากกรอบ Bounding Box) ถ้าน้องอยากให้หุ่นยนต์หยิบของบนสายพาน แค่ Classification ไม่พอนะครับ น้องต้องใช้ Object Detection ด้วย!
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Image Classification คือการสอนให้คอมพิวเตอร์แปลงข้อมูล “พิกเซลดิบๆ” ให้กลายเป็น “ความหมาย (Semantic)” ในรูปแบบของคลาสหรือหมวดหมู่ครับ โดยมี Convolutional Neural Network (CNN) เป็นพระเอกหลักในการสกัดฟีเจอร์และตัดสินใจ ซึ่งเทคนิคนี้ถูกนำไปต่อยอดใช้ในระบบคัดแยกสินค้าในโรงงานและการแพทย์อย่างแพร่หลาย
แต่ถ้าน้องๆ สังเกตดู โมเดล Classification แบบดั้งเดิมจะทายผลได้ดีก็ต่อเมื่อมี “วัตถุหลักเพียงชิ้นเดียว” ตรงกลางภาพเท่านั้น! ถ้าในภาพมีทั้งหมา แมว และรถยนต์ปนกันอยู่ล่ะ AI จะจัดการอย่างไร?
ในตอนต่อไป พี่จะพาน้องๆ ก้าวข้ามขีดจำกัดนี้ไปสู่โลกของ Object Detection เราจะมาเรียนรู้เทคนิคการตีกรอบ Bounding Box เพื่อค้นหาวัตถุหลายๆ ชิ้นในภาพเดียวกัน เตรียมตัวให้พร้อม แล้วพบกันครับ!
ต้องการที่ปรึกษาด้านการพัฒนาระบบ AI Camera หรือ Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p