ตอนที่ 3: Deep Learning ทำงานอย่างไรในมุมมองของภาพ? เจาะลึกวิธีที่ AI มองเห็นพิกเซล
1. 🎯 ตอนที่ 3: ไขความลับดวงตาจักรกล คอมพิวเตอร์เข้าใจภาพได้อย่างไร?
สวัสดีครับน้องๆ วิศวกรสาย Vision และนักพัฒนาทุกท่าน! กาแฟแก้วโปรดพร้อมแล้วใช่ไหมครับ ในตอนที่แล้วเราคุยกันถึงการเปลี่ยนผ่านจากยุคของการเขียนโค้ดแบบ Rule-based ทั่วไป มาสู่ยุคของ Deep Learning ที่ AI สามารถเรียนรู้ฟีเจอร์ต่างๆ ได้ด้วยตัวเอง
แต่คำถามที่พี่มักจะโดนเด็กจบใหม่หรือคนนอกวงการถามบ่อยที่สุดคือ “พี่ครับ… แล้วคอมพิวเตอร์มันมองเห็นรูปหมา รูปแมว หรือรอยร้าวบนชิ้นงานได้ยังไง ในเมื่อมันไม่มีตาแบบมนุษย์?”
นั่นแหละครับคือหัวใจสำคัญของวันนี้! ในฐานะวิศวกร AI เราต้องปรับวิธีคิดของเราให้ตรงกับคอมพิวเตอร์เสียก่อน วันนี้พี่จะพาน้องๆ ไปเจาะแก่นรากฐานของ Artificial Neural Network (ANN) และทำความเข้าใจว่า AI มันอ่าน “พิกเซล (Pixels)” อย่างไรให้กลายเป็นความเข้าใจแบบมนุษย์ครับ ลุยกันเลย!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการดูนะครับ เวลาน้องมองรูปถ่ายของ “สุนัข” สมองของน้องประมวลผลทันทีว่านี่คือสิ่งมีชีวิต มีหู มีจมูก มีขน… แต่สำหรับคอมพิวเตอร์ล่ะ? มันไม่ได้มีความซาบซึ้งอะไรกับความน่ารักของสุนัขเลยครับ!
สิ่งที่คอมพิวเตอร์เห็นคือ “ตารางตัวเลขขนาดยักษ์ (Matrix of Numbers)” เท่านั้น! ช่องว่างความเข้าใจระหว่าง “ตารางตัวเลข” ที่คอมพิวเตอร์เห็น กับ “ความหมายของภาพ” ที่มนุษย์เข้าใจ ในวงการเราเรียกมันว่า “Semantic Gap” ครับ การจะทำให้ AI ข้ามกำแพงความเข้าใจนี้ไปได้ เราจึงต้องใช้ศาสตร์ที่จำลองการทำงานของสมองมนุษย์เข้ามาช่วย นั่นก็คือ Deep Learning นั่นเอง
3. 🧠 แก่นวิชา (Core Concepts)
เพื่อให้เห็นภาพชัดเจนที่สุด เรามาแยกชิ้นส่วนกระบวนการมองเห็นของ AI กันทีละสเต็ปตามตำราวิศวกรรมเลยครับ:
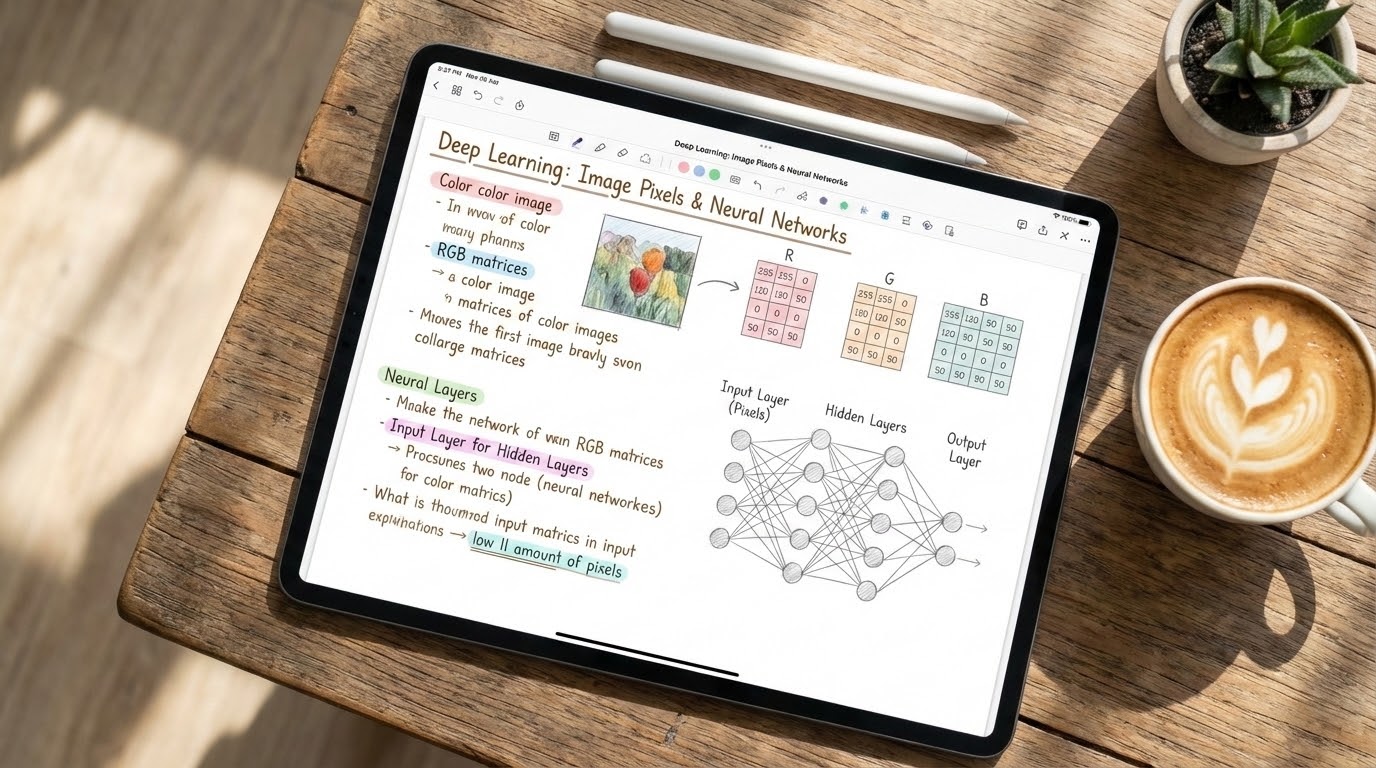
- 1. จากภาพวาด สู่ตารางตัวเลข (Pixels & Matrices):
ภาพดิจิทัลทุกภาพประกอบขึ้นจากจุดสี่เหลี่ยมเล็กๆ ที่เรียกว่า “พิกเซล (Pixel)”
- ภาพขาวดำ (Grayscale): คอมพิวเตอร์จะมองเป็นตาราง 2 มิติ (2D Matrix) ที่มีค่าตัวเลขตั้งแต่ 0 (สีดำมืดสนิท) ไล่ไปจนถึง 255 (สีขาวสว่างจ้า)
- ภาพสี (Color/RGB): คอมพิวเตอร์จะมองเป็นตาราง 3 มิติ (3D Matrix) ที่มีความลึก (Depth) เท่ากับ 3 แชนเนล ได้แก่ สีแดง (Red), สีเขียว (Green), และสีน้ำเงิน (Blue) วางซ้อนทับกัน ตัวเลขแต่ละช่องก็คือระดับความเข้มของสีนั้นๆ ครับ
- 2. โครงข่ายประสาทเทียม (Artificial Neural Network - ANN):
เมื่อเราได้ตัวเลขพิกเซลมาแล้ว เราจะป้อนมันเข้าไปในระบบที่เลียนแบบสมองมนุษย์ ซึ่งประกอบด้วยเซลล์ประสาทเทียม (Neurons) เรียงต่อกันเป็นชั้นๆ (Layers) ได้แก่:
- Input Layer: จุดรับข้อมูล (รับค่าตัวเลขพิกเซลจากภาพเข้ามา)
- Hidden Layers: ชั้นซ่อนเร้นที่ทำหน้าที่ “คิดและวิเคราะห์” (ยิ่งมีหลายชั้น เรายิ่งเรียกว่า Deep Learning)
- Output Layer: ชั้นแสดงผลลัพธ์ (เช่น ทายว่านี่คือ สุนัข 95% หรือ แมว 5%)
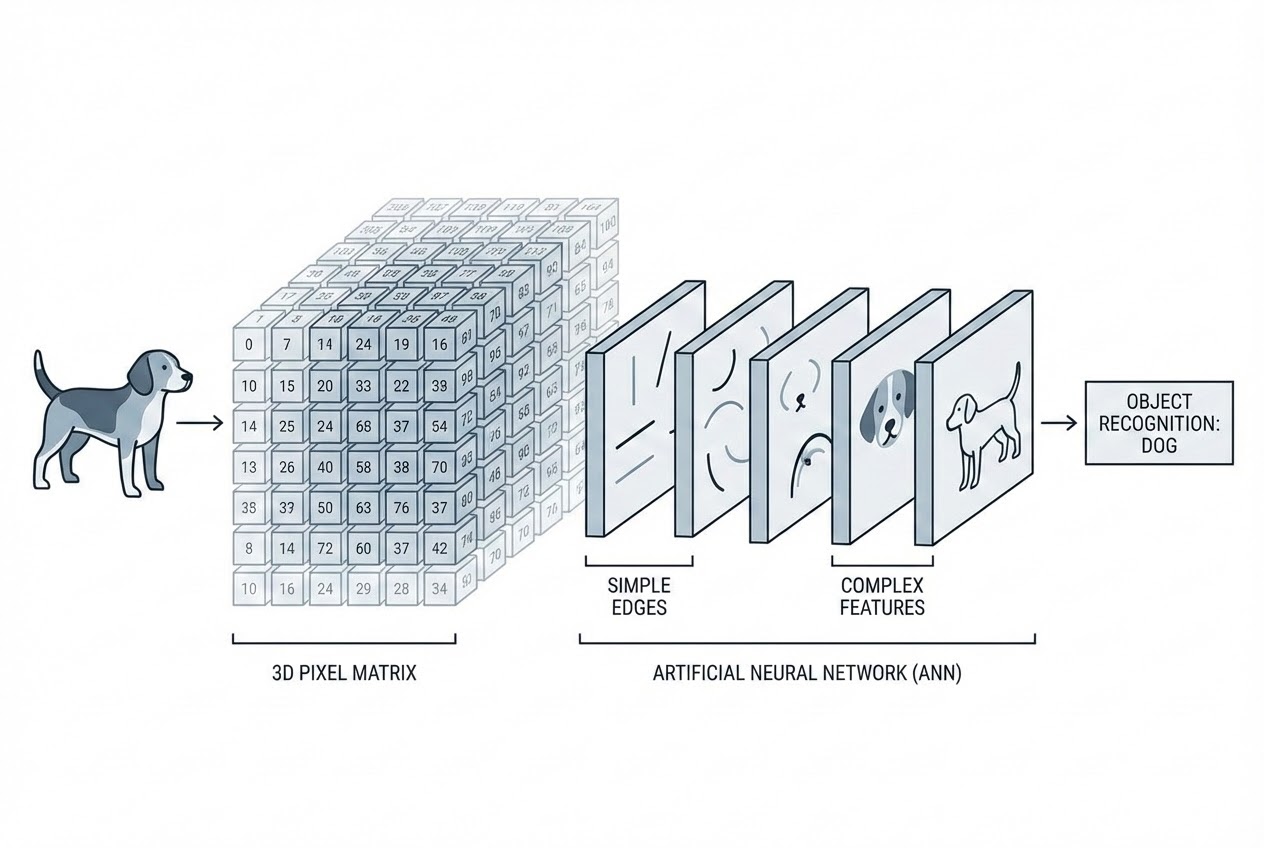
- 3. การเรียนรู้แบบลำดับชั้น (Hierarchical Feature Learning):
นี่คือเวทมนตร์ของจริงครับ! AI ไม่ได้มองภาพปุ๊บแล้วรู้ปั๊บ แต่เซลล์ประสาทใน Hidden Layers จะทำงานกันเป็นทีมแบบโรงงานประกอบชิ้นส่วน:
- ชั้นแรกๆ (Early Layers): จะมองหาจุดเด่นพื้นฐาน (Low-level features) เช่น เส้นตรง, เส้นโค้ง, ขอบภาพ (Edges) หรือจุดที่สีตัดกัน
- ชั้นกลางๆ (Intermediate Layers): จะเอาเส้นเหล่านั้นมาประกอบร่างเป็น รูปทรง (Shapes) เช่น วงกลม, สี่เหลี่ยม, หรือมุม (Corners)
- ชั้นลึกๆ (Deeper Layers): จะเอารูปทรงมาประกอบเป็น ฟีเจอร์ระดับสูง (High-level semantic features) เช่น ล้อรถยนต์, ดวงตาของสุนัข, หรือรอยร้าวบนโลหะ!
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
พี่จะโชว์ให้ดูครับว่า ในมุมมองของภาษา Python (ผ่านไลบรารี OpenCV และ NumPy) คอมพิวเตอร์มันเห็นภาพ 1 ภาพ เป็นแค่ตัวเลขจริงๆ ไม่ได้โม้!
import cv2
import numpy as np
# 1. โหลดภาพสีปกติเข้ามาในระบบ
image = cv2.imread('dog.jpg')
# 2. ลองเช็กรูปร่าง (Shape) ของภาพดู
print("Image Shape:", image.shape)
# ผลลัพธ์อาจจะเป็น: (700, 700, 3)
# ความหมาย: ภาพสูง 700 พิกเซล, กว้าง 700 พิกเซล, และมี 3 แชนเนลสี (RGB)
# 3. แปลงเป็นภาพขาวดำ (Grayscale) เพื่อให้ดูง่ายขึ้น
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 4. ลองแอบดูตัวเลขพิกเซล 5x5 มุมซ้ายบนของภาพ
print("Pixel Matrix (5x5):\n", gray_image[0:5, 0:5])
# ผลลัพธ์ที่คอมพิวเตอร์เห็นคือตัวเลขความสว่าง (0-255) ล้วนๆ!
# [
#
#
#
# ]คอมเมนต์: เห็นไหมครับว่า สุดท้ายแล้วหน้าที่ของ Neural Network ก็คือการเอาตารางตัวเลขพวกนี้ ไปคูณกับค่าน้ำหนัก (Weights) ผ่านสมการคณิตศาสตร์ เพื่อทายผลลัพธ์ออกมานั่นเองครับ
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในมุมมองของคนทำ AI หน้างานจริง พี่มีศาสตร์ลับอยากจะกระซิบเตือนครับ:
- ระวังกับดักของการ Flattening (การทุบภาพให้แบน): ถ้าน้องใช้โครงข่ายประสาทเทียมแบบดั้งเดิมที่เรียกว่า Multi-Layer Perceptron (MLP) หรือ Fully Connected Network เพียวๆ น้องจะต้องเอาตารางภาพ 2 มิติ (เช่น 28x28 พิกเซล) มา “ทุบให้แบน (Flatten)” กลายเป็นเส้นก๋วยเตี๋ยวยาวๆ (เวกเตอร์ 1 มิติขนาด 784 พิกเซล) ก่อนป้อนเข้า Input Layer
- ผลเสียคืออะไร? การทำแบบนั้นทำให้เรา “สูญเสียข้อมูลเชิงพื้นที่ (Spatial Information)” ไปครับ! คอมพิวเตอร์จะไม่รู้เลยว่าพิกเซลที่อยู่ติดกันบนล่างมันมีความสัมพันธ์กัน ทำให้ MLP มักจะทำงานกับภาพได้ห่วยแตกมากหากวัตถุขยับตำแหน่งไปจากเดิม (Translation Invariance) หรือถ้าภาพมีขนาดใหญ่ (เช่น 1000x1000 พิกเซล) จำนวนพารามิเตอร์จะพุ่งทะลุพันล้านตัวจนคอมค้างไปเลย!
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว การที่ AI สามารถ “มองเห็น” ได้นั้น เริ่มต้นจากการที่มันรับข้อมูลภาพในรูปแบบของ ตารางตัวเลขพิกเซล (Matrix) จากนั้นจึงส่งผ่านเข้าไปใน Artificial Neural Network ที่ทำหน้าที่สกัดจุดเด่น (Feature Extraction) แบบเป็นลำดับชั้น จากเส้นขอบพื้นฐาน สู่รูปทรงที่ซับซ้อน จนสามารถตัดสินใจระบุวัตถุได้ในที่สุดครับ
แต่จากข้อควรระวังในส่วน Pro-Tips ที่พี่บอกไป ว่า Neural Network แบบดั้งเดิม (MLP) เอามาจัดการกับภาพใหญ่ๆ ไม่ค่อยรอด… วงการ AI จึงต้องให้กำเนิดสถาปัตยกรรมระดับเทพตัวใหม่ที่ออกแบบมาเพื่อการมองเห็นโดยเฉพาะ!
ในบทความตอนต่อไป พี่จะพาน้องๆ ไปทำความรู้จักกับพระเอกตัวจริงของวงการ Computer Vision นั่นคือ “Convolutional Neural Network (CNN)” ครับ มันจะแก้ปัญหาพิกเซลมหาศาลนี้ได้อย่างไร? รอติดตามความสนุกได้เลย!
ต้องการที่ปรึกษาด้านการพัฒนาระบบ AI Camera หรือ Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p