ตอนที่ 2: วิวัฒนาการจาก Image Processing สู่ Deep Learning เมื่อ AI เลิกท่องจำแล้วหัดคิดเอง
1. 🎯 ตอนที่ 2: วิวัฒนาการจาก Image Processing สู่ Deep Learning
สวัสดีครับน้องๆ วิศวกรและนักพัฒนา AI ทุกท่าน! กาแฟพร้อมแล้วใช่ไหมครับ วันนี้เรามาลุยกันต่อในซีรีส์การสร้างดวงตาจักรกล ในตอนที่แล้วเราได้ทำความรู้จักกับความแตกต่างระหว่าง Computer Vision และ Machine Vision กันไปแล้ว
แต่ก่อนที่เราจะมีระบบ AI ที่ฉลาดล้ำ ตรวจจับรอยร้าวหรือแยกแยะชิ้นงานได้อย่างแม่นยำในปัจจุบัน น้องๆ ทราบไหมครับว่าในยุคก่อนหน้านี้ วิศวกรรุ่นพี่ต้องปวดหัวแค่ไหนกับการเขียนโค้ดเพื่อหาวัตถุสักชิ้นในภาพ? วันนี้พี่จะพาไปนั่งไทม์แมชชีนย้อนดูวิวัฒนาการจากยุค Traditional Computer Vision สู่ยุคทองของ Deep Learning และไขข้อข้องใจว่า ทำไมเทคโนโลยีนี้ถึงกลายเป็น “จุดเปลี่ยน” ที่ทำให้วงการอุตสาหกรรมพลิกโฉมไปตลอดกาลครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องกำลังเขียนโปรแกรมตรวจจับ “น็อตที่ขึ้นสนิม” บนสายพาน ในยุคดั้งเดิม น้องอาจจะต้องเขียนโค้ด Rule-based แบบเป๊ะๆ เช่น “ถ้าเจอพิกเซลสีน้ำตาลแดง (Color) และมีรูปทรงวงกลม (Shape) ให้ถือว่าเป็นสนิม”
ในห้องแล็บที่แสงคงที่ โค้ดของน้องจะทำงานได้สมบูรณ์แบบมากครับ แต่พอเอาไปลงหน้างานจริงในโรงงาน… แสงแดดส่องเข้ามาเปลี่ยนสีพิกเซล ชิ้นงานวางเอียงทับกัน (Occlusion) หรือมีคราบน้ำมันเปื้อน โค้ดของน้องจะพังทลายลงทันที!
วิศวกรในยุคก่อนต้องใช้เวลาหลายเดือนในการปรับจูนพารามิเตอร์เพื่อรับมือกับสภาพแวดล้อมที่เปลี่ยนไป ซึ่งเราเรียกวิธีการสกัดจุดเด่นด้วยฝีมือมนุษย์นี้ว่า Hand-crafted features จนกระทั่งวันหนึ่ง พระเอกขี่ม้าขาวที่ชื่อว่า Deep Learning ก็ปรากฏตัวขึ้น และบอกกับเราว่า “หยุดเขียนกฎเกณฑ์พวกนั้นซะ ส่งรูปมาให้ฉันเยอะๆ แล้วฉันจะเรียนรู้กฎพวกนั้นด้วยตัวเอง!”
3. 🧠 แก่นวิชา (Core Concepts)
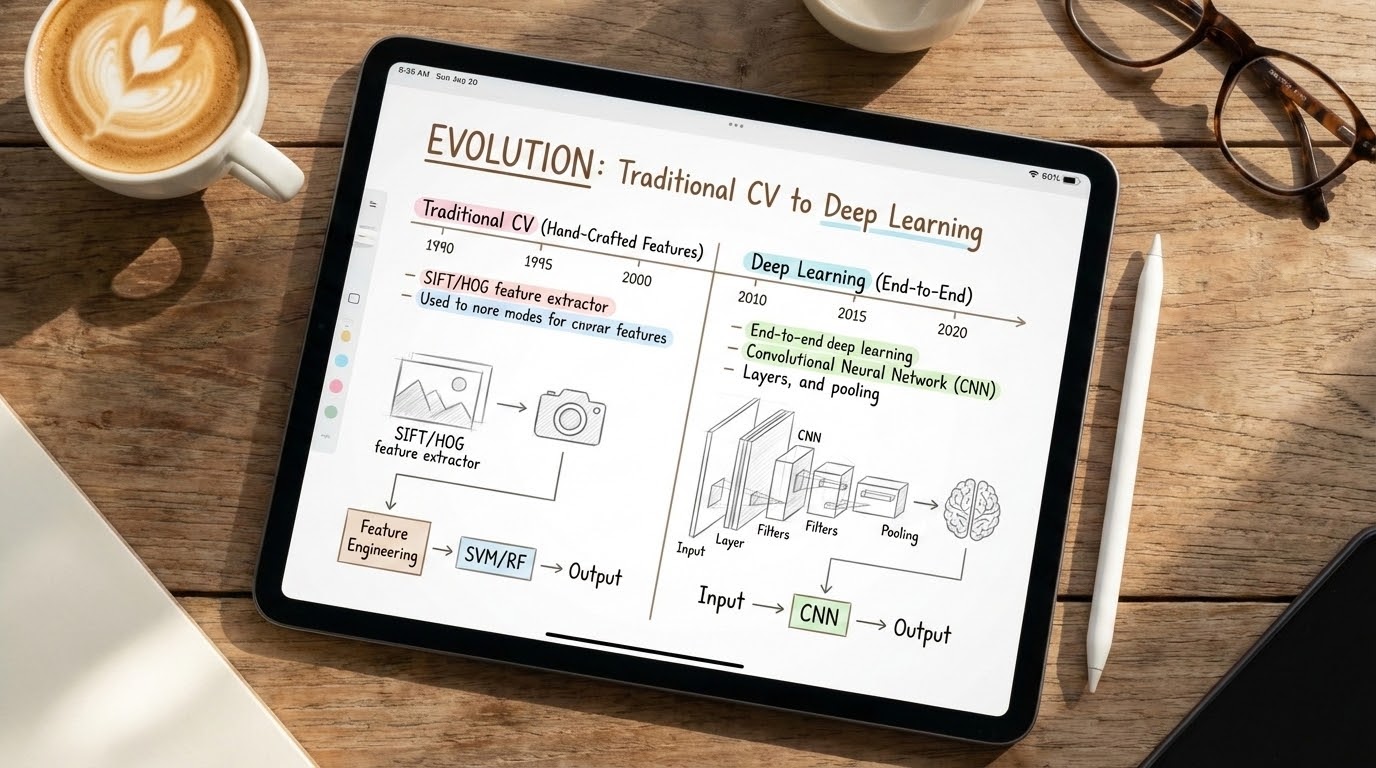
เพื่อให้เห็นภาพชัดเจน เรามาเจาะลึกความแตกต่างระหว่าง 2 ยุคนี้กันครับ:
- ยุคแห่งงานฝีมือ (Traditional Computer Vision): ในอดีต การตรวจจับวัตถุต้องพึ่งพาการสกัดคุณลักษณะที่ออกแบบโดยมนุษย์ (Hand-crafted features) ผสมผสานกับอัลกอริทึม Machine Learning แบบดั้งเดิม เช่น การใช้ Histogram of Oriented Gradients (HOG) หรือ Haar features จับคู่กับตัวแยกประเภทอย่าง Support Vector Machines (SVMs), วิศวกรต้องเป็นผู้เชี่ยวชาญในการออกแบบ Image Descriptor เพื่อวัดค่าสี พื้นผิว (Texture) และรูปทรงของวัตถุ ข้อจำกัดที่ใหญ่ที่สุดคือ วิธีการเหล่านี้ไม่สามารถรับมือกับสถานการณ์ที่ซับซ้อนได้ เช่น ขนาดวัตถุที่เปลี่ยนไป (Scale variations), การถูกบดบัง (Occlusions), และฉากหลังที่วุ่นวาย (Cluttered backgrounds)
- จุดเปลี่ยนครั้งยิ่งใหญ่ (The Deep Learning Revolution): การปฏิวัติวงการเกิดขึ้นในปี 2012 เมื่อโมเดลโครงข่ายประสาทเทียมชื่อว่า AlexNet สามารถเอาชนะการแข่งขันจำแนกภาพ ImageNet (ILSVRC) โดยทำคะแนนทิ้งห่างเทคนิคแบบดั้งเดิมอย่างขาดลอย,,, อัลกอริทึมนี้ไม่ได้พึ่งพา Hand-crafted features อีกต่อไป แต่ใช้ Convolutional Neural Networks (CNNs) ในการเรียนรู้และสกัดคุณลักษณะจากพิกเซลของภาพโดยตรง,
- ทำไม Deep Learning ถึงแม่นยำแบบก้าวกระโดด?:
- Hierarchical Feature Learning: CNNs มีความสามารถในการเรียนรู้คุณลักษณะแบบลำดับชั้น โดยเลเยอร์แรกๆ จะมองหาคุณลักษณะระดับล่าง (Low-level features) เช่น เส้นตรงและขอบ (Edges) ส่วนเลเยอร์ที่ลึกขึ้นจะนำเส้นเหล่านั้นมาประกอบกันเป็นรูปร่างที่ซับซ้อน หรือคุณลักษณะเชิงความหมาย (High-level semantic features) เช่น ชิ้นส่วนของใบหน้ามนุษย์หรือชิ้นส่วนของวัตถุ,,
- End-to-End Learning: โมเดล Deep Learning รวมกระบวนการสกัดคุณลักษณะ (Feature Extraction) และการแยกประเภท (Classification) ไว้ในโครงข่ายเดียวกัน ทำให้เราสามารถฝึกสอนโมเดลรวดเดียวตั้งแต่ต้นจนจบ (End-to-End) ได้,,
- ขุมพลังที่พร้อมพรั่ง: ความสำเร็จนี้ถูกขับเคลื่อนด้วยข้อมูลขนาดมหาศาล (Massive Datasets) และพลังการประมวลผลที่สูงขึ้นจากการ์ดจอ (GPUs) รวมถึงการปรับปรุงอัลกอริทึมเช่น ฟังก์ชันกระตุ้น (Activation functions) อย่าง ReLU,,,
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
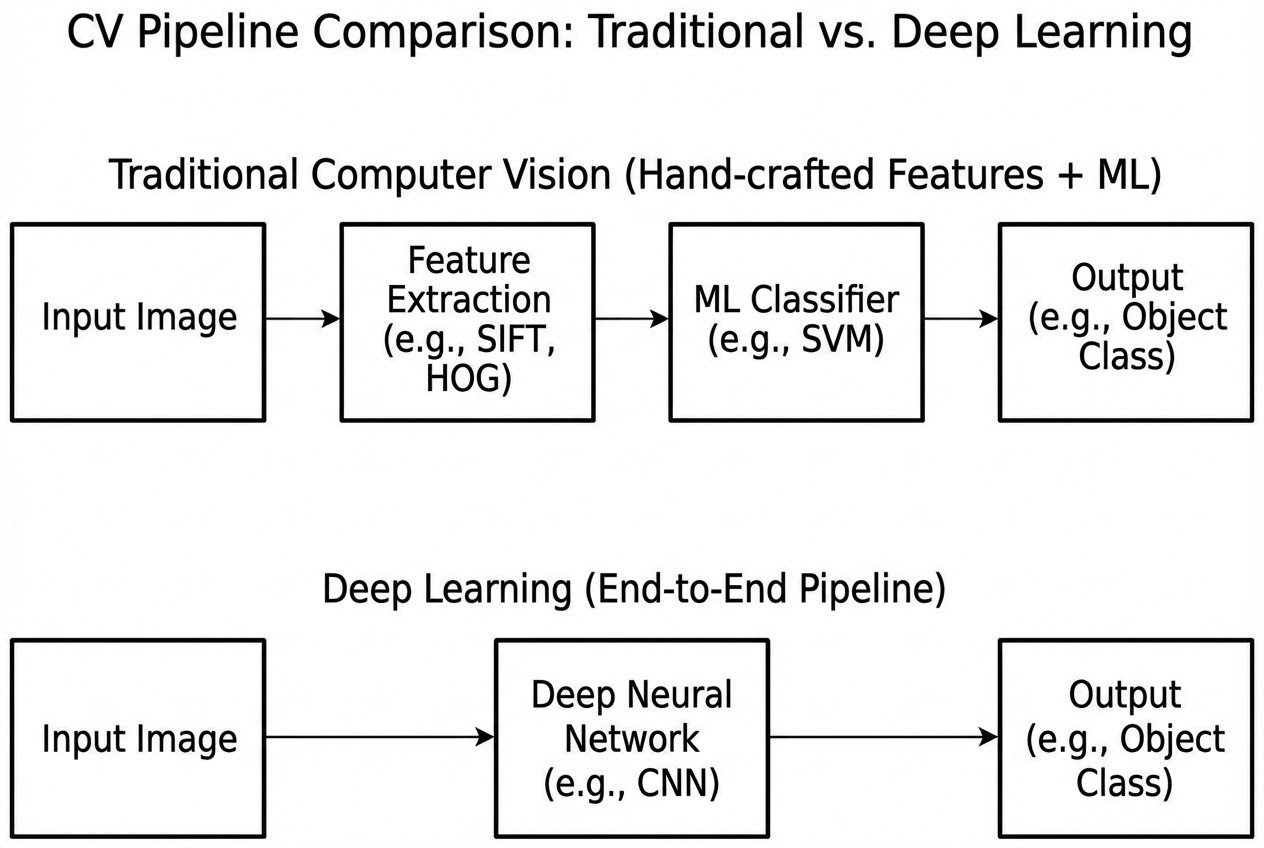
ลองมาดูความแตกต่างระหว่างยุคเก่าและยุคใหม่ผ่านโค้ดกันครับ:
(1) ยุค Traditional CV: เราต้องใช้ไลบรารีสกัดฟีเจอร์อย่าง HOG แล้วเอาไปเข้า SVM
import cv2
from skimage.feature import hog
from sklearn.svm import SVC
# 1. ดึงภาพเข้ามาและแปลงเป็น Grayscale เพื่อลดภาระคำนวณ
image = cv2.imread('defect.jpg', 0)
# 2. มนุษย์ต้องสั่งสกัด Hand-crafted features ด้วย HOG
# (ต้องจูนพารามิเตอร์ pixels_per_cell, cells_per_block เอาเอง)
features, hog_image = hog(image, orientations=9, pixels_per_cell=(8, 8),
cells_per_block=(2, 2), visualize=True)
# 3. เอาฟีเจอร์ที่ได้ไปให้ Machine Learning (SVM) เรียนรู้
svm_classifier = SVC(kernel='linear')
# svm_classifier.fit(features_train, labels_train) (2) ยุค Deep Learning (CNNs): เราโยนรูปดิบๆ เข้าโครงข่ายให้มันหาฟีเจอร์เองเลย!
from tensorflow.keras import layers, models
# 1. สร้างโครงข่าย Convolutional Neural Network (CNNs) แบบ End-to-End,
model = models.Sequential()
# 2. เลเยอร์แรกๆ จะสกัดฟีเจอร์พื้นฐาน เช่น เส้นตรง ขอบ (Low-level features),
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(layers.MaxPooling2D((2, 2)))
# 3. เลเยอร์ลึกๆ จะประกอบร่างเป็นฟีเจอร์ที่ซับซ้อนขึ้น (High-level features),
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 4. ส่วนสำหรับตัดสินใจ (Classifier)
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(2, activation='softmax')) # สมมติว่าแยก 2 คลาส: งานดี / งานเสีย
# ไม่ต้องจูน HOG เองแล้ว แค่สั่ง model.fit() แล้วไปจิบกาแฟได้เลย!5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
พี่มีเกร็ดความรู้เล็กๆ จากงานวิจัยและการทำโปรเจกต์จริงมาแชร์ครับ:
- กำจัด Semantic Gap: ปัญหาใหญ่ของระบบยุคเก่าคือช่องว่างระหว่างสิ่งที่คอมพิวเตอร์เห็น (ตัวเลขพิกเซลดิบๆ) กับสิ่งที่มนุษย์เข้าใจ (ความหมายของภาพ) ซึ่งเรียกว่า Semantic Gap การที่ CNNs สามารถสร้างคุณลักษณะนามธรรมในระดับสูงได้ (Abstract high-level features) ทำให้มันทลายข้อจำกัดนี้และเลียนแบบการรับรู้ของมนุษย์ได้สำเร็จ,
- อย่าทิ้งวิชาเก่า (Hybrid Approach): ถึงแม้ Deep Learning จะเป็นพระเอก แต่บางครั้งการทำ Image Preprocessing ก่อนป้อนเข้าโมเดล เช่น การแปลงสีภาพเป็น Grayscale หรือการจัดการ Noise พื้นฐาน ก็ยังช่วยลดความซับซ้อนในการคำนวณและทำให้โมเดลทำงานได้เร็วขึ้นมากครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว การเปลี่ยนผ่านจากเทคนิค Traditional Computer Vision มาสู่ Deep Learning เปรียบเสมือนการเปลี่ยนจากการ “เขียนคู่มือบอกหุ่นยนต์ให้มองหาอะไรทีละขั้นตอน” มาเป็นการ “สอนให้หุ่นยนต์รู้จักคิดและสกัดจุดเด่นด้วยตัวเองจากประสบการณ์”
ด้วยสถาปัตยกรรมอย่าง Convolutional Neural Networks (CNNs) ประกอบกับพลังการประมวลผลที่ล้ำหน้า ทำให้ความแม่นยำของระบบพุ่งทะยานจนก้าวข้ามขีดจำกัดเดิมๆ ไปอย่างสิ้นเชิง ในบทความตอนต่อไป พี่จะพาน้องๆ ไปผ่าตัดสมองของ CNNs ดูกันทีละชั้นเลยว่า ภายในโครงข่ายประสาทเทียมนี้ มันมองเห็นโลกได้อย่างไร รอติดตามนะครับ!
ต้องการที่ปรึกษาด้านการพัฒนาระบบ AI Camera หรือ Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p