ตอนที่ 14: ปัญหา Data Bias เมื่อ AI ลำเอียง สอนดวงตาจักรกลให้ตาบอดโดยไม่รู้ตัว

1. 🎯 ตอนที่ 14: ปัญหา Data Bias เมื่อ AI ลำเอียง สอนดวงตาจักรกลให้ตาบอดโดยไม่รู้ตัว
สวัสดีครับน้องๆ วิศวกรสาย Vision และนักพัฒนา AI ทุกท่าน! หยิบแก้วกาแฟแล้วมานั่งคุยกันต่อเลยครับ
หลายตอนที่ผ่านมา พี่พาน้องๆ ไปลุยเรื่องการออกแบบสถาปัตยกรรมโครงข่าย Convolutional Neural Network (CNN) และการทำ Data Annotation ตีกรอบ Bounding Box กันมาแล้ว แต่น้องๆ รู้ไหมครับว่า ต่อให้เราเซ็ตค่า Learning Rate ได้เป๊ะ หรือตั้ง Epoch ได้พอดีแค่ไหน โมเดลของเราก็อาจจะกลายเป็น “AI จอมลำเอียง” ได้แบบไม่รู้ตัว!
วันนี้พี่จะพาน้องๆ ไปเจาะลึกด้านมืดของการทำ AI นั่นคือปัญหา Data Bias หรือความลำเอียงของข้อมูลครับ เราจะมาดูกันว่าการป้อน “หนังสือเรียนที่บิดเบี้ยว” ให้ AI อ่าน มันจะส่งผลกระทบระดับหายนะต่อการนำไปใช้งานจริง (Deployment) ได้อย่างไรบ้าง!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการถึงปัญหาหน้างานจริงในโรงงานดูนะครับ สมมติว่าน้องได้รับมอบหมายให้ทำโปรเจกต์ AI ตรวจจับรอยขีดข่วนบน “ชิ้นงานแผ่นโลหะ” น้องจึงเดินไปเก็บภาพชิ้นงานเหล็กสีเงิน (Silver) ในไลน์ผลิตมา 10,000 รูป แล้วเอามาเทรนโมเดลจนได้ความแม่นยำ 99% โมเดลไม่มีอาการ Overfitting เลยในห้องแล็บ น้องยืดอกภูมิใจมาก!
แต่พอถึงวันอังคาร ไลน์ผลิตเปลี่ยนไปรัน “ชิ้นงานทองแดง (Copper)” ที่มีสีอมแดง… สิ่งที่เกิดขึ้นคือ โมเดล AI ของน้องพังทลายครับ! มันมองเห็นพื้นผิวสีแดงเป็นรอยตำหนิไปซะหมด หรือไม่ก็มองข้ามรอยร้าวของจริงไปเลย
นี่แหละครับคือตัวอย่างคลาสสิกของการใช้ Nonrepresentative Training Data หรือชุดข้อมูลที่ไม่เป็นตัวแทนของโลกความจริง AI ไม่มีสามัญสำนึกครับ มันไม่รู้ว่าโลหะเปลี่ยนสีได้ มันรู้แค่ว่า “ถ้าไม่ใช่สีเงินแบบที่เคยเรียนมา ถือว่าผิดปกติ!” ความน่ากลัวนี้ในวงการเราเรียกว่าหลักการ Garbage-in, Garbage-out (GIGO) ครับ
3. 🧠 แก่นวิชา (Core Concepts)
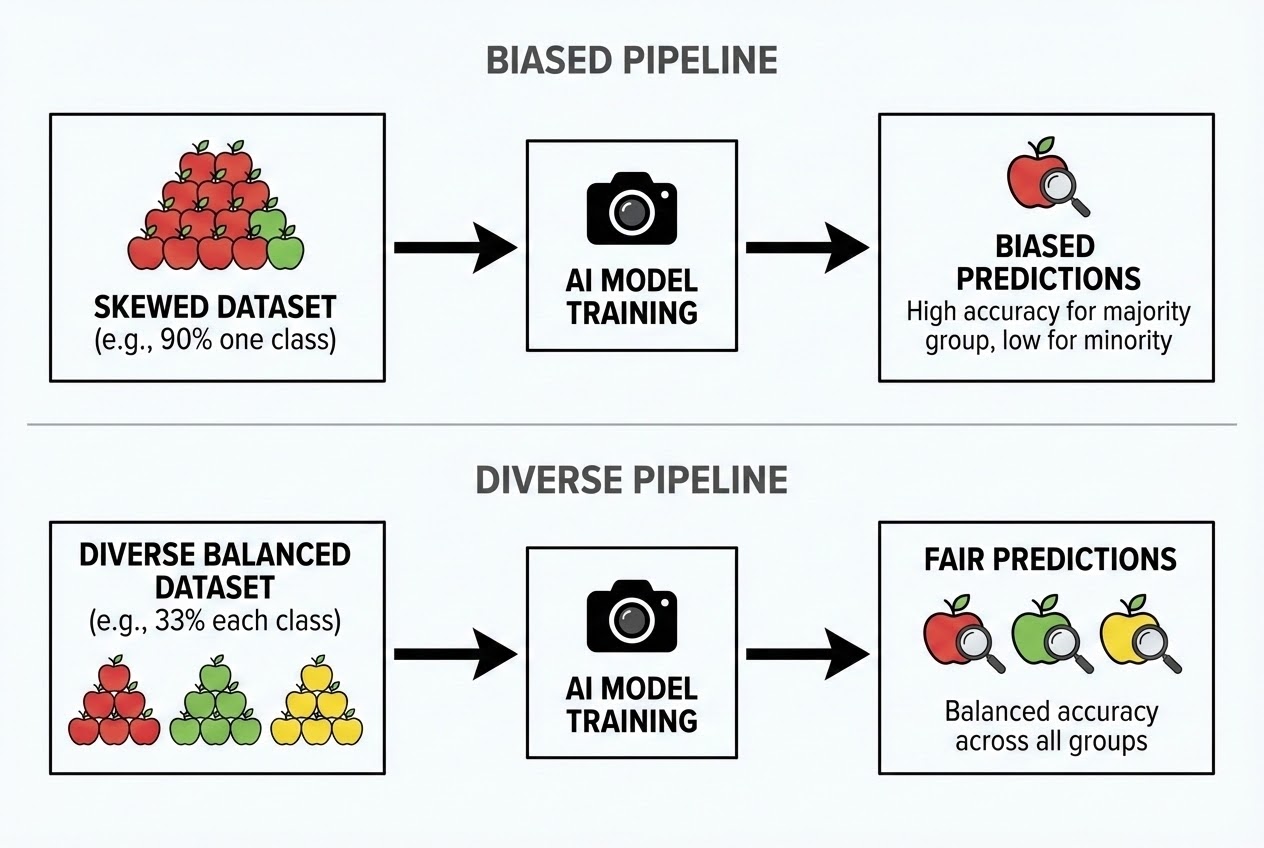
ปัญหาความลำเอียงของข้อมูล (Bias) ในงาน Machine Learning แบ่งออกเป็นหลายประเภทตามตำราระดับโลก ซึ่งวิศวกรทุกคนต้องพึงระวังในทุกขั้นตอนของ Pipeline ครับ:
- 1. Representation Bias (ความลำเอียงจากการเป็นตัวแทน): เกิดขึ้นเมื่อ Dataset ที่เราสุ่มมา ไม่ครอบคลุมความหลากหลายในโลกความเป็นจริง เช่น ถ้าน้องสอนรถยนต์ไร้คนขับให้รู้จักคนเดินถนน โดยใช้แค่ภาพคนวัยทำงาน… พอรถไปเจอ “เด็กทารกกำลังคลาน” หรือ “คนนั่งรถเข็นวีลแชร์” รถอาจจะไม่เบรกเพราะโมเดลไม่เคยเห็นสิ่งนี้มาก่อน ซึ่งนำไปสู่อุบัติเหตุร้ายแรงได้ครับ!
- 2. Historical / Human Bias (ความลำเอียงจากอคติมนุษย์ในอดีต): บางครั้งโลกความจริงมันมีความไม่เท่าเทียมซ่อนอยู่ แล้ว AI ก็ดันไปเรียนรู้รูปแบบนั้นมาเต็มๆ เช่น Dataset ชื่อ CelebA ที่รวบรวมภาพใบหน้าคนดังมาให้ AI เรียนรู้ ภาพส่วนใหญ่ดันเป็นคนผิวขาวและดูวัยรุ่น พอเอาโมเดลนี้ไปใช้ตรวจจับใบหน้าคนสูงอายุหรือคนผิวสี AI ก็จะทำงานผิดพลาดทันทีครับ
- 3. Aggregation Bias (ความลำเอียงจากการเหมารวม): เกิดขึ้นเมื่อเราพยายามสร้างโมเดลเดียวเพื่อใช้งานกับประชากรทุกกลุ่ม (Subgroups) ที่มีลักษณะต่างกันโดยสิ้นเชิง ในทางการแพทย์ หากเราให้ AI วินิจฉัยโรคโดยไม่แยกเพศหรือเชื้อชาติ (ซึ่งส่งผลต่อลักษณะของโรค) โมเดลจะทำงานได้แย่มากในกลุ่มประชากรส่วนน้อยครับ เราควรต้องแยกโมเดล หรือเพิ่มฟีเจอร์ให้ AI เข้าใจความต่างนี้
- 4. Evaluation Bias (ความลำเอียงในการวัดผล): นี่คือกับดักที่วิศวกรตกบ่อยที่สุด! คือการที่ Dataset สำหรับทดสอบ (Test Set) ของน้อง ก็ดันมีความลำเอียงเหมือนกับ Training Set ทำให้น้องเห็นตัวเลข Accuracy 99% แล้วหลงระเริง แต่พอเอาไปลงหน้างานจริง (Deployment Bias) โมเดลกลับพังไม่เป็นท่าครับ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
การป้องกัน Data Bias เริ่มต้นได้ง่ายๆ ด้วยการเขียนโค้ดเช็ก “การกระจายตัวของข้อมูล (Data Distribution)” ก่อนเริ่มเทรนครับ! นี่คือโค้ด Python เบื้องต้นด้วย Pandas และ Matplotlib ที่วิศวกรใช้เช็กความสมดุลของคลาสหน้างาน:
import pandas as pd
import matplotlib.pyplot as plt
# 1. จำลองการโหลดข้อมูล Metadata ของภาพชิ้นงานในโรงงาน
# ข้อมูลประกอบด้วย "ประเภทชิ้นงาน (วัสดุ)" และ "สถานะ (งานดี/งานเสีย)"
data = {'Material': ['Silver']*8000 + ['Copper']*1500 + ['Gold']*500,
'Defect_Status': ['Pass']*7000 + ['Fail']*3000}
df = pd.DataFrame(data)
# 2. เช็ก Representation Bias (ความลำเอียงของประเภทวัสดุ)
material_counts = df['Material'].value_counts()
print("--- สัดส่วนภาพชิ้นงานตามวัสดุ ---")
print(material_counts)
# 3. วาดกราฟแท่ง (Bar Chart) เพื่อให้เห็นภาพความลำเอียงชัดๆ
plt.figure(figsize=(8, 5))
material_counts.plot(kind='bar', color=['silver', 'chocolate', 'gold'])
plt.title('Representation Bias Check: Material Distribution')
plt.ylabel('Number of Images')
plt.show()คอมเมนต์อธิบายสไตล์คุยกัน: จากโค้ดนี้น้องจะเห็นเลยว่า ภาพชิ้นงาน Silver ล่อไป 8,000 รูป แต่ Gold มีแค่ 500 รูป! นี่คือสัญญาณเตือนภัย (Red Flag) ของ Representation Bias ถ้าน้องฝืนกดเทรนโมเดลไป AI ของน้องจะเก่งแค่กับงานโลหะสีเงิน แต่จะกลายเป็นคนตาบอดทันทีเมื่อเจองานโลหะสีทองครับ!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
พี่มีกรณีศึกษา (Case Studies) ระดับโลกที่หน้าแหกเพราะ Data Bias มาเตือนสติครับ:
- เลข 7 ของชาวอเมริกัน (The MNIST Bias): น้องๆ รู้ไหมครับว่าชุดข้อมูลภาพตัวเลขระดับตำนานอย่าง MNIST ก็มีความลำเอียง! ภาพตัวเลขเขียนด้วยมือเหล่านี้ถูกเก็บมาจากพนักงานสำนักงานสำมะโนประชากรและนักเรียนมัธยมในสหรัฐอเมริกา ผลก็คือ AI มันคุ้นชินกับ “สไตล์การเขียนแบบอเมริกัน” พอเจอคนยุโรปที่ชอบเขียนเลข 7 โดยมี “ขีดแนวนอนตรงกลาง (Crossbar)” เข้าไป AI ในยุคแรกๆ ถึงกับงงและทายผิดกระจุยกระจายครับ!
- เมื่อ AI เปลี่ยนคนผิวสีเป็นคนผิวขาว (The PULSE Algorithm): เคยมีงานวิจัยชื่อ PULSE ที่ทำ Face Super-resolution (เสกภาพเบลอให้คมชัด) อัลกอริทึมนี้ถูกเทรนด้วยภาพคนดังที่ส่วนใหญ่เป็นคนผิวขาว ความพังคือ เมื่อนักวิจัยลองป้อนภาพเบลอๆ ของบารัค โอบามา (Barack Obama) เข้าไป โมเดลกลับเสกภาพใบหน้าที่คมชัดออกมาเป็น “ชายผิวขาว” ซะอย่างนั้น! นี่คือผลลัพธ์ที่น่ากลัวมากของ Historical / Representation Bias ครับ
- วิธีแก้เกมหน้างาน (Pro-Tips): เวลาประเมินโมเดล อย่าดูแค่ค่า Accuracy รวมทั้งก้อน! พี่แนะนำให้ตัดแบ่งกลุ่มข้อมูล (Subgroups) เช่น คลาสชิ้นงานสีเงิน, ชิ้นงานสีทอง แล้ววัดความแม่นยำแยกกัน (Disaggregated evaluation) และถ้าข้อมูลไม่พอจริงๆ ให้ใช้เทคนิค Data Augmentation (เช่น เติม Noise, ปรับแสงสี) เพื่อเพิ่มความหลากหลายให้กับกลุ่มประชากรส่วนน้อยครับ!
6. 🏁 บทสรุป (To be continued…)
สรุปสั้นๆ ให้ขึ้นใจเลยนะครับ “AI ไม่ได้ฉลาดด้วยตัวมันเอง แต่มันฉลาดเท่าที่ข้อมูลของเรามี” ปัญหา Data Bias ไม่ใช่แค่ประเด็นทางสังคม แต่เป็นความล้มเหลวทางวิศวกรรม (Engineering Failure) อย่างร้ายแรง การป้อนชุดข้อมูลที่ไม่ครอบคลุม จะทำให้เราได้ดวงตาจักรกลที่เต็มไปด้วยอคติและมีจุดบอดซ่อนอยู่มากมายครับ
เมื่อเราได้เรียนรู้วิธีคลีนข้อมูลและหลีกเลี่ยง Bias กันไปแล้ว ในบทความตอนต่อไป พี่จะพาน้องๆ ไปพบกับสุดยอดกระบวนการสอน AI ที่ทำให้มันเก่งขึ้นได้จริงๆ นั่นคือกลไกของ Gradient Descent และ Backpropagation ซึ่งเป็นหัวใจสำคัญทางคณิตศาสตร์ที่ทำให้สมองกลรู้จักปรับตัวและเรียนรู้จากความผิดพลาด เตรียมเปิดสมองซีกซ้ายรอรับคณิตศาสตร์สนุกๆ กันได้เลยครับ!
ต้องการที่ปรึกษาด้านการพัฒนาระบบ AI Camera หรือ Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p