ตอนที่ 13: Data Annotation การสอน AI ให้รู้จักโลกผ่าน Bounding Box และ Masking

1. 🎯 ตอนที่ 13: Data Annotation การสอน AI ให้รู้จักโลก
สวัสดีครับน้องๆ วิศวกรสาย Vision และนักพัฒนา AI ทุกท่าน! กาแฟอุ่นๆ พร้อมแล้วใช่ไหมครับ มาลุยกันต่อเลย!
ในตอนที่แล้ว เราคุยกันว่า “ข้อมูล (Data)” คือน้ำมันชั้นดีที่ขับเคลื่อนเครื่องยนต์ Deep Learning แต่ปัญหาคือ… ถ้าน้องโยนรูปถ่ายชิ้นงาน 10,000 รูปเข้าไปในโฟลเดอร์เฉยๆ AI มันจะไม่ตรัสรู้ขึ้นมาเองนะครับว่า “รอยร้าว” อยู่ตรงไหน หรือ “สุนัข” หน้าตาเป็นอย่างไร!
ในโลกของ Machine Learning การจะได้มาซึ่งความฉลาด เราต้องมีกระบวนการ “ชี้เป้า” หรือบอกใบ้เฉลยให้ AI รู้ก่อน ซึ่งเราเรียกกระบวนการนี้ว่า Data Annotation หรือการทำ Labeling ครับ วันนี้พี่จะพาน้องๆ ไปสวมวิญญาณคุณครูอนุบาล สอนให้ AI รู้จักการตีกรอบ (Bounding Box) และการระบายสี (Masking) พร้อมแนะนำเครื่องมือคู่กายวิศวกรที่ขาดไม่ได้ในการทำงานจริงครับ!
2. 📖 เปิดฉาก (The Hook)
ในวงการเรามักจะมีคำกล่าวติดตลกว่า “AI ย่อมาจาก Absent Indian” (หมายถึงเบื้องหลังความฉลาดของ AI คือหยาดเหงื่อแรงงานคนที่มานั่งคลิกเมาส์ตีกรอบรูปทีละรูปนั่นเอง ฮา!)
น้องๆ รู้ไหมครับว่า การหาฉลาก (Labels) หรือการตีกรอบภาพ เป็นส่วนที่ยากที่สุดและใช้ต้นทุนสูงที่สุด (Hardest and most costly part) ในการทำโปรเจกต์ Machine Learning เลยทีเดียว! ลองคิดดูว่าถ้าเราต้องสร้างระบบ AI ให้รถยนต์ไร้คนขับ เราต้องจ้างคนมานั่งตีกรอบรถยนต์ คนข้ามถนน ป้ายจราจร เป็นล้านๆ เฟรม!
แต่ถึงมันจะเหนื่อยและน่าเบื่อแค่ไหน มันก็เป็นขั้นตอนชี้เป็นชี้ตายครับ เพราะถ้าเราสอน (Label) ผิด โมเดลก็จะจำผิดๆ ไปใช้งาน (Garbage in, garbage out) เรามาดูกันดีกว่าว่าการทำ Data Annotation ที่ถูกต้อง เขาทำกันอย่างไรครับ!
3. 🧠 แก่นวิชา (Core Concepts)
การสอน AI ให้มองเห็นในงาน Computer Vision หลักๆ จะมี 2 ท่ามาตรฐาน (ขึ้นอยู่กับว่าเราใช้สถาปัตยกรรมโมเดลแบบไหน) ดังนี้ครับ:
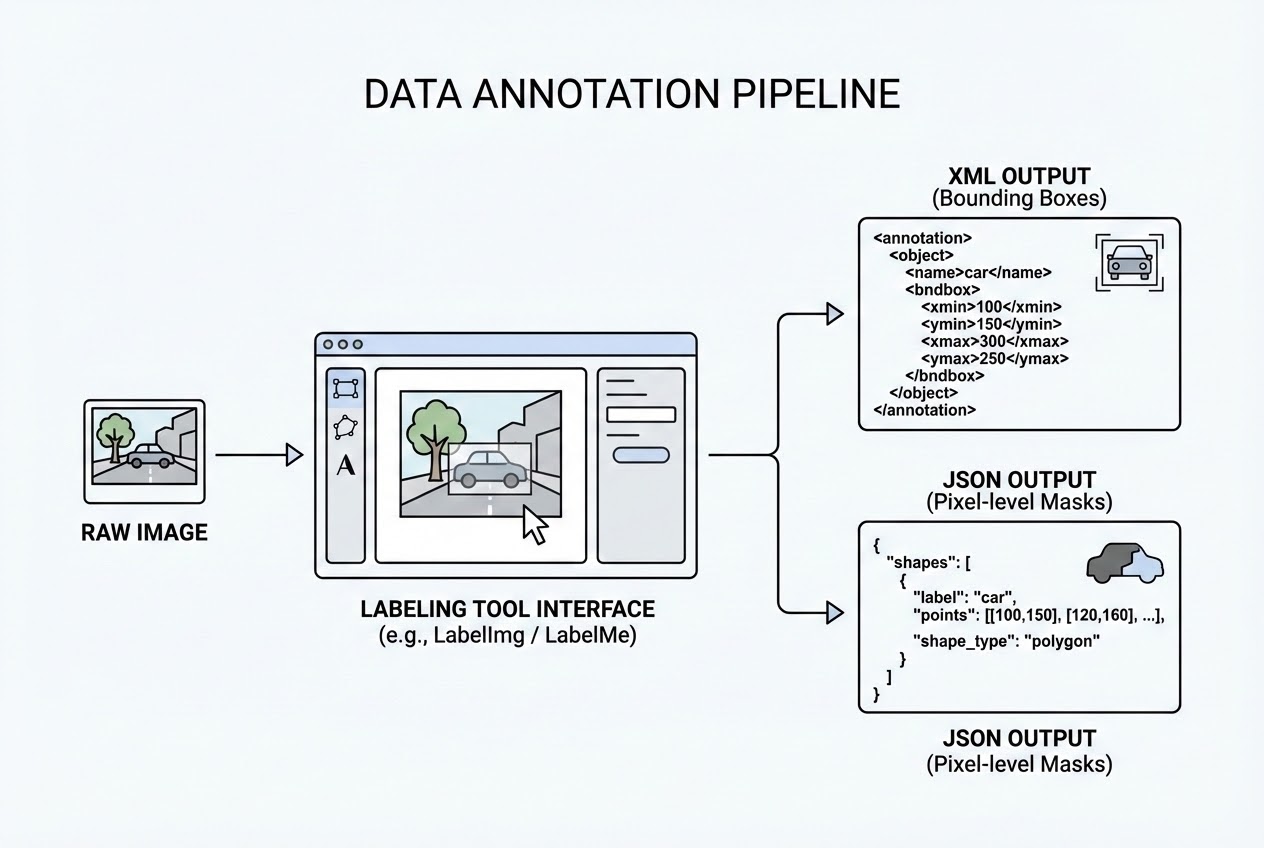
- 1. การวาดกรอบสี่เหลี่ยม (Bounding Box Annotation):
- ใช้สำหรับงาน: Object Detection (เช่น YOLO, Faster R-CNN)
- หลักการ: เราจะใช้เมาส์ลากกรอบสี่เหลี่ยมครอบวัตถุเป้าหมายให้พอดีที่สุด ในมุมมองของคอมพิวเตอร์ มันจะจำค่าตัวเลข 4 ค่า คือ พิกัดแนวนอนและแนวตั้งของจุดศูนย์กลางวัตถุ (x, y) รวมถึงความสูงและความกว้างของกรอบ (h, w)
- เครื่องมือยอดฮิต: LabelImg เป็นแอปพลิเคชัน Open Source ที่ติดตั้งและใช้งานง่ายมาก หรือถ้าเป็นภาพถ่ายทางอากาศที่วัตถุเอียงไปมา ก็อาจจะใช้ RoLableImg สำหรับตีกรอบแบบหมุนองศาได้ (Rotated box)
- 2. การระบายสีแยกส่วน (Pixel-level Masking / Polygon Annotation):
- ใช้สำหรับงาน: Semantic Segmentation หรือ Instance Segmentation (เช่น Mask R-CNN หรือ U-Net)
- หลักการ: งานประเภทนี้ต้องการความละเอียดระดับพิกเซล การตีกรอบสี่เหลี่ยมหยาบๆ ไม่ตอบโจทย์ เราจึงต้องใช้เมาส์คลิกจุดต่อจุด (Polygon) เพื่อวาดเส้นรอบขอบเขตของวัตถุให้แนบสนิท เพื่อระบุอย่างชัดเจนว่าพิกเซลไหนในภาพที่เป็นของวัตถุชิ้นนั้นๆ
- เครื่องมือยอดฮิต: LabelMe ซึ่งพัฒนาโดย MIT, VGG Image Annotator, OpenLabeler หรือ ImgLab
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เวลาที่เราลากกรอบ Bounding Box ในโปรแกรมอย่าง LabelImg เสร็จแล้ว โปรแกรมจะไม่ได้เซฟรูปใหม่ให้เรานะครับ แต่มันจะสร้าง “ไฟล์ข้อความ” ออกมาคู่กับไฟล์รูปภาพ มักจะใช้ฟอร์แมตมาตรฐานอย่าง VOC2007 (XML) ลองมาแอบดูไส้ในของไฟล์ XML ที่สอนให้ AI รู้จัก “จิงโจ้ (Kangaroo)” กันครับ:
<!-- ตัวอย่างไฟล์ 00001.xml ที่ได้จากโปรแกรม LabelImg -->
<annotation>
<folder>Kangaroo</folder>
<filename>00001.jpg</filename>
<size>
<width>450</width> <!-- ความกว้างรูปภาพต้นฉบับ -->
<height>319</height> <!-- ความสูงรูปภาพต้นฉบับ -->
<depth>3</depth> <!-- จำนวนแชนเนลสี (RGB) -->
</size>
<object>
<name>kangaroo</name> <!-- 📌 นี่ไง! ป้ายกำกับ (Label) ที่เราตั้งไว้ -->
<bndbox>
<!-- 📌 พิกัดของ Bounding Box (พิกเซลมุมซ้ายบน และ ขวาล่าง) -->
<xmin>233</xmin>
<ymin>89</ymin>
<xmax>386</xmax>
<ymax>262</ymax>
</bndbox>
</object>
</annotation>คอมเมนต์สไตล์วิศวกรรุ่นพี่: เวลาน้องๆ เขียนโค้ด Python เพื่อเทรนโมเดล น้องก็แค่เขียนสคริปต์ไปดึงคำว่า kangaroo และพิกัด <xmin>, <ymin>, <xmax>, <ymax> เหล่านี้ โยนเข้าไปเป็น “เฉลย (Ground Truth)” ให้กับ Loss Function ของ Neural Network ครับ!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
สำหรับวิศวกรที่ต้องคุมโปรเจกต์ AI สเกลใหญ่ พี่มีเกร็ดความรู้เล็กๆ มาเตือนใจครับ:
- Crowdsourcing คือทางออกของโปรเจกต์ยักษ์: ถ้าน้องมีรูปภาพหลักแสนหรือล้านรูปให้ต้อง Label น้องไม่มีทางทำเองไหวแน่ๆ ครับ! ในวงการจึงนิยมใช้แพลตฟอร์มระดมสมองคนหมู่มากอย่าง Amazon Mechanical Turk หรือใช้บริการซอฟต์แวร์เชิงพาณิชย์อย่าง LabelBox และ Supervisely เข้ามาช่วยกระจายงาน
- ควบคุมคุณภาพให้ดี: ข้อควรระวังของการจ้างคนนอกทำ (Crowdsourcing) คือคุณภาพครับ การเตรียมเอกสารคู่มือ (Guidelines) ชี้แจงให้ชัดเจนว่า “รอยร้าวแบบไหนถึงจะให้ตีกล่อง” และการทำระบบสุ่มตรวจคุณภาพ (Quality Control) เป็นเรื่องที่วิศวกรต้องลงแรงจัดการอย่างหนัก ไม่อย่างนั้นโมเดลของน้องจะพังเพราะ Label ขยะแน่นอน!
- Format Transformation: หน้างานจริง เครื่องมือแต่ละตัวมักจะเซฟไฟล์คนละนามสกุล (เช่น LabelImg ได้ XML, ส่วน LabelMe ได้ JSON) บางครั้งเราต้องเขียนสคริปต์ Python เล็กๆ เพื่อแปลงไฟล์เหล่านี้ให้กลายเป็นมาตรฐานกลางอย่าง MS COCO format ก่อนนำไปป้อนให้โมเดลครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว กระบวนการ Data Annotation คือจิ๊กซอว์ชิ้นที่สำคัญที่สุดที่ทำหน้าที่เชื่อมโยงระหว่าง “โลกความจริง” และ “สมองของ AI” เข้าด้วยกัน ไม่ว่าจะเป็นการตีกรอบ Bounding Box สำหรับงาน Object Detection หรือการจุด Polygon/Masking สำหรับงาน Segmentation ความแม่นยำของโมเดลล้วนขึ้นอยู่กับความประณีตในการทำ Label ของเราทั้งสิ้นครับ
ตอนนี้พวกเรามีทั้งทฤษฎี มีเครื่องมือ มีข้อมูลที่พร้อมใช้งานแล้ว! ในบทความตอนต่อไป พี่จะพาน้องๆ ก้าวเข้าสู่ลานประลองของจริง เราจะมาทำความรู้จักกับสถาปัตยกรรมระดับตำนานที่ชื่อว่า YOLO (You Only Look Once) ดูกันว่าทำไมมันถึงกลายเป็นราชาแห่งการตรวจจับวัตถุแบบ Real-time ครองใจวิศวกรทั่วโลก! เตรียมตัวให้พร้อมนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p