เจาะลึก Recursion (ฟังก์ชันเรียกตัวเอง): เวทมนตร์แห่งการแก้ปัญหาในระดับ Advanced Design

1. 🎯 ชื่อบทความ (Title): เจาะลึก Recursion (ฟังก์ชันเรียกตัวเอง): เวทมนตร์แห่งการแก้ปัญหาในระดับ Advanced Design
2. 👋 เกริ่นนำ (Introduction)
สวัสดีครับเพื่อนๆ นักพัฒนาและน้องๆ วิศวกรทุกคน! หากเราเขียนโปรแกรมมาได้สักพัก เราคงคุ้นเคยกับการวนลูป for หรือ while เพื่อทำงานซ้ำๆ ใช่ไหมครับ? แต่เมื่อระบบ Automation หรือแอปพลิเคชันของเราเริ่มซับซ้อนขึ้น เช่น การต้องค้นหาไฟล์ในโฟลเดอร์ที่ซ้อนกันลึกๆ (Directory tree) หรือการวิเคราะห์โครงสร้างข้อมูลแบบเครือข่าย การใช้ลูปธรรมดาอาจจะทำให้โค้ดยาวและดูยุ่งเหยิงมาก
ในโลกของวิทยาการคอมพิวเตอร์และ Advanced Design มีเทคนิคหนึ่งที่ทรงพลังมากเรียกว่า Recursion (การเรียกตัวเอง) ครับ ลองนึกภาพเหมือนเราส่องกระจกที่สะท้อนภาพตัวเองซ้อนกันลึกลงไปเรื่อยๆ (เหมือนหนังเรื่อง Inception!) แม้หลายคนจะมองว่า Recursion เป็นเรื่องที่เข้าใจยากและอาจทำให้โปรแกรมช้า แต่ความจริงแล้วมันคือเครื่องมือที่ช่วยลดความซับซ้อนของปัญหาใหญ่ (Divide and Conquer) ให้กลายเป็นปัญหาย่อยที่แก้ได้ง่ายนิดเดียว วันนี้พี่วิสิทธิ์จะพาไปดูเบื้องหลังการทำงานและวิธีใช้ Recursion อย่างโปรกันครับ!
3. 📖 เนื้อหาหลัก (Core Concept)
ในระดับโครงสร้าง (Architecture) แหล่งข้อมูลได้อธิบายแนวคิดของ Recursion และบทบาทของมันในงาน Advanced Design ไว้ดังนี้ครับ:
- Recursion คืออะไร? มันคือเทคนิคการเขียนโปรแกรมที่ “ฟังก์ชันทำการเรียกใช้งานตัวมันเอง (Calls itself)” เพื่อแก้ปัญหาเดิมแต่ในสเกลที่เล็กลง (Subproblems)
- องค์ประกอบสำคัญ (Golden Rules): ฟังก์ชัน Recursive ทุกตัวจะต้องมี 2 ส่วนเสมอ หากขาดไปโปรแกรมจะพังทันที:
- Base Case (เงื่อนไขหยุด / กรณีฐาน): คือเงื่อนไขที่ปัญหาถูกย่อยจนเล็กที่สุดและสามารถหาคำตอบได้ทันทีโดยไม่ต้องเรียกตัวเองซ้ำอีก ทำหน้าที่เป็นเบรกเบรกเกอร์ไม่ให้ลูปรันไปเรื่อยๆ
- Recursive Step (การเรียกตัวเอง): การนำปัญหามาแบ่งให้เล็กลง และส่งปัญหาที่เล็กลงนั้นเข้าไปในฟังก์ชันตัวเองอีกครั้ง
- เบื้องหลังการทำงาน (The Call Stack): สิ่งที่เกิดขึ้นจริงๆ ใน Memory คือ ทุกครั้งที่ฟังก์ชันเรียกตัวเอง ภาษา Python จะสร้าง “Stack Frame” ใหม่ขึ้นมาซ้อนทับกัน (Push) เพื่อเก็บตัวแปรโลคัลและพารามิเตอร์ของรอบนั้นๆ แยกกันอย่างชัดเจน และเมื่อถึง Base case มันก็จะทำการคืนค่า (Pop) ทยอยกลับขึ้นมาตามลำดับ
- บทบาทใน Advanced Design:
- Divide and Conquer: ใช้แยกปัญหาใหญ่ เช่น การเรียงลำดับข้อมูลแบบ Mergesort หรือ Quicksort
- Backtracking (การลองผิดลองถูก): ใช้เขียนระบบ AI ง่ายๆ เพื่อหาทางออกจากเขาวงกต (Maze) หรือแก้ปริศนาซูโดกุ โดยการลองเดินไปทีละก้าว หากเจอทางตันก็ “ย้อนกลับ (Backtrack)” ไปลองทางอื่น
- Dynamic Programming & Memoization: การใช้ Recursion เดี่ยวๆ อาจกินเวลา (เช่น หาค่าฟีโบนัชชี) แต่เมื่อทำงานร่วมกับแคช (Cache) เพื่อจำผลลัพธ์ที่เคยคำนวณไปแล้ว จะเปลี่ยนอัลกอริทึมที่ช้ามากๆ ให้เร็วระดับแสงได้ทันที
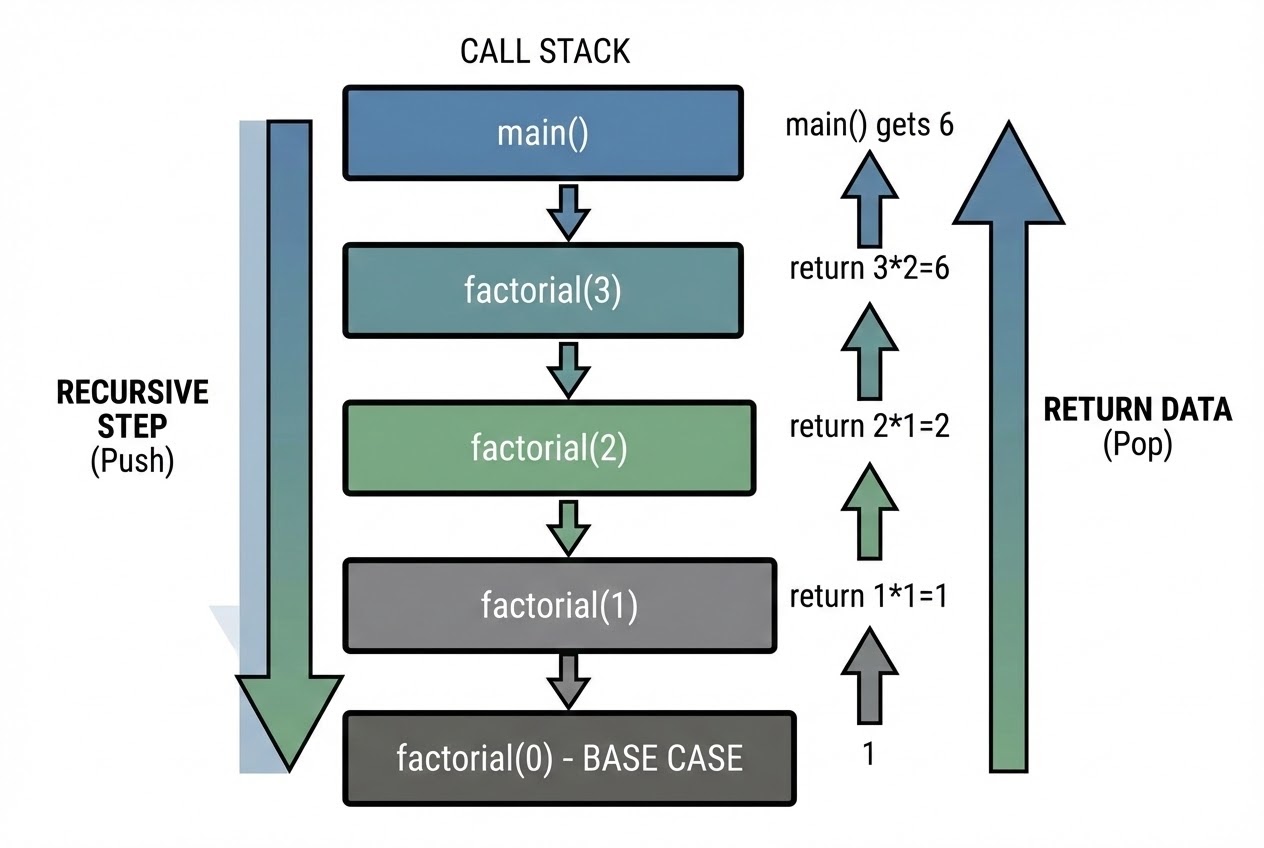
4. 💻 ตัวอย่างโค้ด (Code Example)
ลองมาดูความแตกต่างระหว่างการใช้ Recursion แบบธรรมดา (ที่ช้า) กับแบบ Advanced Design ที่ผนวกเอาเทคนิค Memoization (การจำผลลัพธ์) เข้ามาช่วยคำนวณอนุกรมตัวเลขฟีโบนัชชี (Fibonacci) เพื่อควบคุมระบบคาดการณ์ในอุตสาหกรรมกันครับ:
import time
from functools import lru_cache
# ❌ แบบที่ 1: Recursion ทั่วไป (ช้าและกินทรัพยากรมากถ้า n ใหญ่)
# เพราะมันจะคำนวณค่าเดิมซ้ำๆ (Overlapping subproblems)
def fib_basic(n):
if n == 0 or n == 1: # Base Case: หยุดเมื่อ n เป็น 0 หรือ 1
return n
else: # Recursive Step: เรียกตัวเอง
return fib_basic(n - 1) + fib_basic(n - 2)
# ✅ แบบที่ 2: Advanced Design (ใช้ Recursion + Memoization)
# @lru_cache จะทำหน้าที่เป็น Cache อัตโนมัติ ช่วยจำค่าที่เคยคำนวณแล้ว
@lru_cache(maxsize=None)
def fib_optimized(n):
"""คำนวณ Fibonacci อย่างรวดเร็วด้วยการจดจำ (Memoization)"""
if n == 0 or n == 1: # Base Case
return n
# หากเคยคำนวณ fib_optimized(n) แล้ว มันจะดึงจาก Cache มาตอบทันที
return fib_optimized(n - 1) + fib_optimized(n - 2)
# --- ทดสอบประสิทธิภาพ ---
n_value = 35 # ลองที่ค่าสูงๆ
start_time = time.time()
print(f"Basic Result: {fib_basic(n_value)}")
print(f"Basic Time: {time.time() - start_time:.4f} วินาที\n")
start_time = time.time()
print(f"Optimized Result: {fib_optimized(n_value)}")
print(f"Optimized Time: {time.time() - start_time:.6f} วินาที")คำอธิบาย: ในแบบที่ 1 (ไม่ต้องรันด้วยตัวเองถ้า n เกิน 40 นะครับ เครื่องอาจจะค้างได้!) โค้ดจะแตกกิ่งก้านการทำงานเป็น $O(2^n)$ แต่ในแบบที่ 2 เราเพิ่ม Decorator @lru_cache เข้าไป ทำให้ Python จดจำคำตอบที่เคยหาได้แล้ว ความเร็วจะพุ่งขึ้นมาเป็น $O(n)$ หรือทำงานเสร็จในพริบตาเลยล่ะครับ!
5. 🛡️ ข้อควรระวัง / Best Practices
ในการนำ Recursion ไปใช้ในระดับ Production พี่ขอเน้นย้ำจุดที่มักทำให้เกิดบั๊กร้ายแรงครับ:
- ระวัง Infinite Recursion (ลูปมรณะ): ถ้าคุณลืมเขียน Base Case หรือตั้งเงื่อนไขผิดจนมันลงไปไม่ถึง Base Case ฟังก์ชันจะเรียกตัวเองไปเรื่อยๆ จนเต็มหน่วยความจำ (Stack Overflow) และ Python จะสั่งพังโปรแกรมทันทีด้วยข้อผิดพลาด
RecursionError: maximum recursion depth exceeded - Cost of Abstraction (ต้นทุนด้านประสิทธิภาพ): การใช้ Recursion มีค่าใช้จ่ายทาง Memory และเวลา (Overhead) มากกว่าการใช้ Loop
whileหรือforเล็กน้อย เนื่องจากต้องจองพื้นที่ Stack Frame ทุกครั้งที่เรียก หากปัญหาไม่ได้มีความเป็น Tree Structure หรืองานสเกลเล็กๆ การใช้ลูปธรรมดาอาจประหยัดทรัพยากรมากกว่า - เปลี่ยน Recursion เป็น Iteration หากจำเป็น: ทุกอัลกอริทึมที่เป็น Recursion สามารถถูกแปลงร่างให้เป็นโค้ดแบบ Loop (Iteration) ได้โดยการใช้ Data Structure ประเภท Stack มาจัดการด้วยตัวเอง (Custom Stack) ซึ่งจะช่วยแก้ปัญหาข้อจำกัดความลึกของ Python ได้หากต้องคำนวณข้อมูลมหาศาล
6. 🏁 สรุป (Conclusion & CTA)
ในบริบทของ Advanced Design แล้ว Recursion ไม่ได้เกิดมาเพื่อทำงานให้เร็วที่สุดครับ แต่มันเกิดมาเพื่อให้โค้ดของเรา “อ่านง่าย สง่างาม และสะท้อนทฤษฎีทางคณิตศาสตร์” ได้อย่างตรงไปตรงมา โดยเฉพาะเมื่อเจอกับโครงสร้างข้อมูลที่มีลักษณะแตกกิ่งก้าน (Recursive data structures) การใช้ฟังก์ชันเรียกตัวเองร่วมกับเทคนิคการทำ Memoization จะเปลี่ยนโค้ดที่ซับซ้อนให้กลายเป็นงานศิลปะทางวิศวกรรมซอฟต์แวร์ได้อย่างแท้จริง
ต้องการที่ปรึกษาและพัฒนาระบบ Automation หรือ Data Handling ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p