ตอนที่ 15: วิธีเลือกใช้ Data Structure ให้เหมาะสมกับงาน (Cheat Sheet ฉบับ Senior)

1. 🎯 ตอนที่ 15: วิธีเลือกใช้ Data Structure ให้เหมาะสมกับงาน (บทสรุป Phase 1)
2. 📖 เปิดฉาก (The Hook)
ยินดีด้วยครับน้องๆ! เราเดินทางมาถึงบทสรุปของ Phase 1 กันแล้ว ตลอด 14 ตอนที่ผ่านมา เราได้ติดอาวุธระดับตำนานกันไปมากมาย ตั้งแต่ Array, Linked List, Stack, Queue, Hash Table ยัน Trees และ Graphs
แต่รู้ไหมครับว่า คำถามที่ปราบเซียนที่สุดในการสัมภาษณ์งานบริษัท FAANG หรือแม้แต่การออกแบบระบบสเกลใหญ่ในชีวิตจริง ไม่ใช่คำถามที่ว่า “เขียนโค้ด BST เป็นไหม?” แต่เป็นคำถามที่ว่า “โจทย์แบบนี้ คุณจะเลือกใช้ Data Structure ตัวไหน เพราะอะไร?”
ในคัมภีร์ The Algorithm Design Manual ของศาสตราจารย์ Steven Skiena ได้กล่าวประโยคทองไว้ว่า “In practice, it is more important to avoid using a bad data structure than to identify the single best option available.” (ในทางปฏิบัติ การหลีกเลี่ยง Data Structure ที่แย่ สำคัญกว่าการพยายามเค้นหาตัวที่ดีที่สุดเพียงตัวเดียว) วันนี้พี่เลยจะมาสรุป Guideline และ Cheat Sheet ให้พวกเราแคปหน้าจอเก็บไว้ใช้ตัดสินใจเลือกอาวุธให้ถูกกับงานกันครับ!
3. 🧠 แก่นวิชา (Core Concepts)
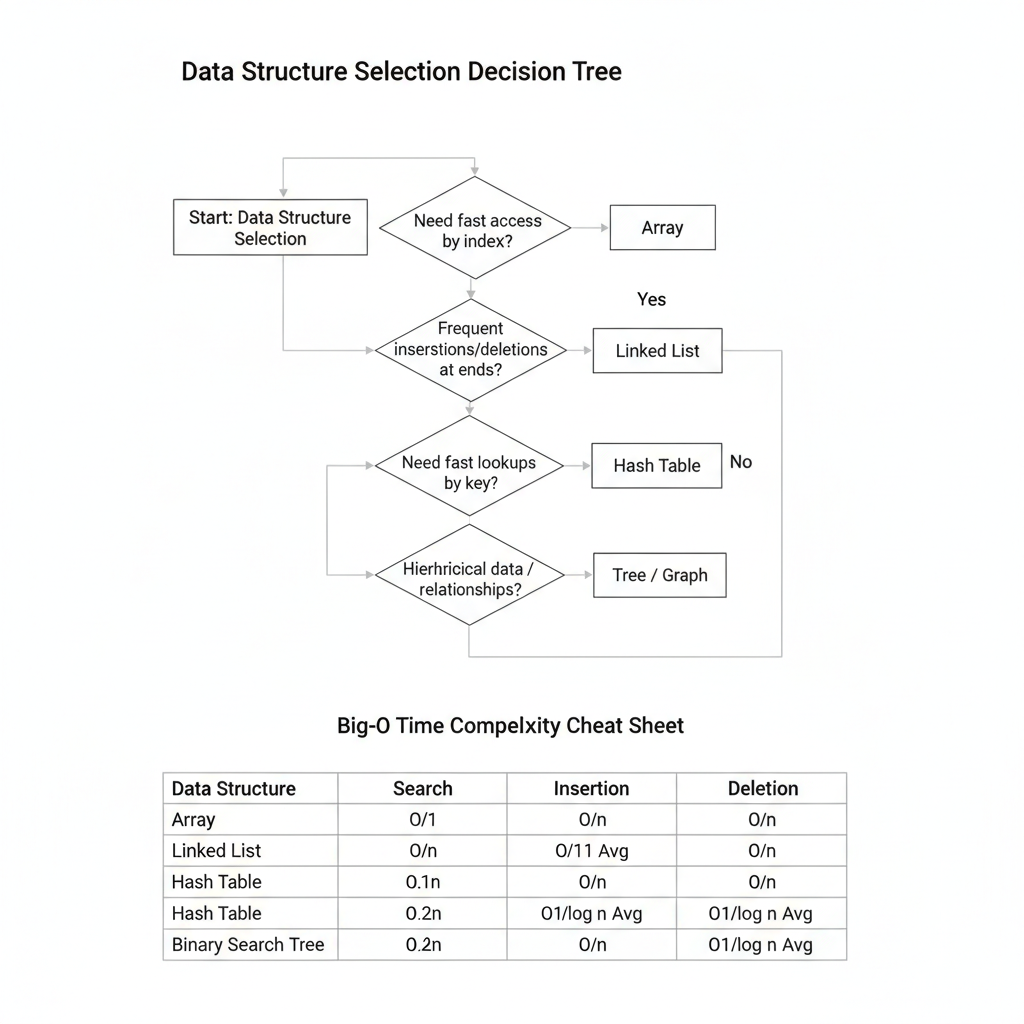
ก่อนจะเขียนโค้ดบรรทัดแรก Senior Engineer จะต้องตั้งคำถาม 3 ข้อนี้กับตัวเองเสมอ (Checklist for Selection):
- รู้ปริมาณข้อมูลล่วงหน้าไหม? (Static vs. Dynamic):
- ถ้ารู้ขนาดแน่นอนและไม่ค่อยเปลี่ยน -> ไปหา Array เพราะมันจอง Memory รวดเดียวจบ ทำงานเข้าขากับ CPU Cache สุดๆ
- ถ้าข้อมูลยืดหดได้ตลอดเวลา -> ไปหา Linked List หรือโครงสร้างแบบ Node-based
- เน้นค้นหา (Read-heavy) หรือ เน้นแก้ไข (Write-heavy)?:
- ถ้าระบบต้องค้นหาข้อมูลบ่อยมาก -> ข้าม Linked List ไปเลย แล้วหันไปพึ่ง Hash Table $O(1)$ หรือ Balanced Tree $O(\log n)$
- ถ้าระบบเน้นแทรกข้อมูลหรือลบข้อมูลรัวๆ ตรงหัวหรือท้าย -> Linked List, Stack, Queue คือคำตอบ
- ลำดับของข้อมูล (Ordering) สำคัญไหม?:
- ถ้าต้องการแค่เช็คว่า “มี/ไม่มี” โดยไม่สนลำดับ -> Hash Table คือราชา
- แต่ถ้าต้องการหา “ค่าน้อยสุด/มากสุด” หรือต้องการเรียงลำดับตลอดเวลา -> Binary Search Tree (BST) หรือ Heap (Priority Queue) จะเหมาะสมกว่า
📊 Cheat Sheet: ตารางพลังรบ Data Structures พื้นฐาน (อ้างอิง Time Complexity แบบ Average/Worst Case ที่เจอบ่อยสุด)
| Data Structure | Search (ค้นหา) | Insert (เพิ่ม) | Delete (ลบ) | จุดเด่น (Pros) | จุดอ่อน (Cons) | Use Case ที่เหมาะสม |
|---|---|---|---|---|---|---|
| Array | $O(N)$ / $O(1)$(Index) | $O(N)$ | $O(N)$ | อ่านข้อมูลผ่าน Index ไวแสง | แทรก/ลบช้า ต้องขยับข้อมูล | ข้อมูลขนาดคงที่, เน้นเข้าถึงด้วย Index |
| Linked List | $O(N)$ | $O(1)$* | $O(1)$* | ยืดหดขนาดได้อิสระ ไม่เปลืองที่ | ค้นหาช้า ต้องวิ่งหาทีละโหนด | ระบบที่แทรก/ลบบ่อยๆ ตรงหัวหรือท้าย |
| Hash Table | $O(1)$ | $O(1)$ | $O(1)$ | ค้นหา/เพิ่ม/ลบ ไวที่สุดในโลก | ข้อมูลไม่เรียงลำดับ, กิน Memory | ระบบ Caching, DNS, หาของซ้ำ |
| BST (Balanced) | $O(\log N)$ | $O(\log N)$ | $O(\log N)$ | ค้นหาไวปานกลาง ข้อมูลเรียงเสมอ | โค้ดซับซ้อน, ต้องคอยจัดสมดุลต้นไม้ | ระบบที่ต้องการ Range Query, หา Min/Max |
(หมายเหตุ: การ Insert/Delete ใน Linked List เป็น $O(1)$ ต่อเมื่อเรารู้ตำแหน่ง Pointer ของโหนดนั้นแล้วเท่านั้น)
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในภาษา Python เรามีความโชคดีตรงที่ตัวภาษาได้เตรียม Data Structures พื้นฐานที่ผ่านการปรับจูนประสิทธิภาพมาให้พร้อมใช้งานแล้ว การเลือกใช้ให้ถูกเครื่องมือคือสิ่งที่เราต้องทำครับ:
# 1. ต้องการ Array ที่เรียงข้อมูลแล้วค้นหาแบบ O(log N) -> ใช้ list + module 'bisect'
import bisect
scores =
# แทรกค่า 25 เข้าไปโดยยังคงรักษาการเรียงลำดับไว้ (O(N) time but efficient in Python)
bisect.insort(scores, 25)
# 2. ต้องการ Queue หรือ Linked List ที่เพิ่ม/ลดหัวท้ายไวระดับ O(1) -> ใช้ 'collections.deque'
from collections import deque
queue = deque(["Alice", "Bob", "Charlie"])
queue.append("Diana") # เข้าคิวท้ายแถว O(1)
queue.popleft() # ออกจากหัวคิว O(1) (ถ้าใช้ list ธรรมดาจะกลายเป็น O(N)!)
# 3. ต้องการ Hash Table ค้นหาไวแสง O(1) และไม่ต้องสนลำดับ -> ใช้ 'dict' หรือ 'set'
users = {"us1": "John", "us2": "Jane"}
if "us1" in users: # ค้นหาแบบ O(1)
print("Found John!")
# 4. ต้องการ Priority Queue (Heap) ดึงค่าน้อยสุดออกเสมอ -> ใช้ module 'heapq'
import heapq
tasks =
heapq.heapify(tasks) # จัดโครงสร้างเป็น Min-Heap แบบ O(N)
next_task = heapq.heappop(tasks) # ดึงเลข 1 ออกมาแบบ O(log N)5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ข้อควรระวังสุดท้ายที่ Senior Dev ขอย้ำเตือน คือเรื่องของ Space-Time Tradeoff (ได้อย่างเสียอย่าง) ครับ:
- หากน้องๆ เลือกใช้ Hash Table เพื่อหวังความเร็วระดับ $O(1)$ น้องต้องยอมรับว่าระบบจะ “เสีย Memory มากขึ้น” เพราะ Hash Table จำเป็นต้องมีพื้นที่ว่างเผื่อไว้ (ลด Load Factor) เพื่อป้องกันการชนกัน (Hash Collisions)
- หากน้องๆ เลือกใช้ Linked List หรือ Trees น้องต้องยอมเสีย “Pointer Overhead” (Memory ที่ใช้เก็บลายแทง) ในทุกๆ โหนด
- ในขณะที่ Array แม้จะทำงานบางอย่างช้า แต่ในระดับฮาร์ดแวร์แล้ว การที่ข้อมูลอยู่เรียง “ติดกัน (Contiguous)” ทำให้ CPU สามารถอ่านข้อมูลขึ้นมาประมวลผลรวดเดียวได้ (Cache Locality) ซึ่งในทางปฏิบัติ การรัน Array ธรรมดาในบางสถานการณ์อาจเร็วกว่า Linked List ด้วยซ้ำ!
ดังนั้น จำไว้เสมอว่า “ไม่มี Data Structure ไหนที่เป็น Silver Bullet (กระสุนเงินที่ฆ่าได้ทุกปัญหา)” ครับ
6. 🏁 บทสรุป (To be continued…)
จบกันไปแล้วครับสำหรับ Phase 1 ของซีรีส์ DSA หวังว่า Cheat Sheet และ Guideline ในบทนี้จะช่วยเคลียร์ใจให้น้องๆ สามารถวิเคราะห์ปัญหาและหยิบเครื่องมือมาใช้งานได้อย่างแม่นยำเหมือนจับวางนะฮะ!
ใน Phase 2 พี่จะพาน้องๆ ก้าวเข้าสู่โลกของ “Advanced Algorithm Design Techniques” ไม่ว่าจะเป็น Greedy Algorithms, Dynamic Programming, และ Backtracking ซึ่งเป็นวิชาขั้นสูงที่ใช้ในการสร้าง AI และแก้ปัญหาระดับโลก ไปพักผ่อนทบทวนวิชากันให้เต็มที่ แล้วกลับมาลุยกันต่อครับ!
ต้องการที่ปรึกษาด้านการออกแบบ System Architecture และพัฒนาระบบซอฟต์แวร์สเกลใหญ่ให้กับองค์กรของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและพัฒนาซอฟต์แวร์แบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p