เมื่อ Hash เกิดการชนกัน (Hash Collisions) และวิธีรับมือไม่ให้ระบบพัง

1. 🎯 ตอนที่ 8: เมื่อรถไฟชนกันใน Hash Table (Hash Collisions) และวิชาหลบหลีกขั้นเทพ
2. 📖 เปิดฉาก (The Hook)
จากตอนที่แล้วที่เราได้เห็นเวทมนตร์ระดับ $O(1)$ ของ Hash Table ที่ดึงข้อมูลได้ไวแสง แต่ในโลกความเป็นจริง หากน้องๆ ไปสัมภาษณ์งานบริษัท FAANG คำถามปราบเซียนที่กรรมการมักจะถามต่อทันทีคือ “แล้วถ้า Hash Function มันคำนวณออกมาได้ Index ช่องเดียวกันล่ะ คุณจะแก้ปัญหานี้ยังไง?”
ในทางคณิตศาสตร์มีกฎที่เรียกว่า “Pigeonhole Principle” (หลักรังนกพิราบ) ที่บอกไว้ว่า ถ้าเรามีนกพิราบ 10 ตัว แต่มีรังแค่ 9 รัง ยังไงซะก็ต้องมีนกอย่างน้อย 2 ตัวที่ต้องอยู่รังเดียวกัน! ในโลกของ Hash Table ก็เช่นกันครับ เมื่อข้อมูลเรามีจำนวนมหาศาล แต่ขนาดของ Array (ล็อกเกอร์) มีจำกัด โอกาสที่คีย์สองตัวจะถูกแปลงสภาพออกมาเป็น Index เดียวกันจึงเป็นเรื่องที่หลีกเลี่ยงไม่ได้ เราเรียกเหตุการณ์รถไฟชนกันนี้ว่า Hash Collision ซึ่งถ้าเราไม่รู้วิธีรับมือ เวทมนตร์ $O(1)$ ของเราอาจจะกลายร่างเป็นโค้ดเต่าคลานระดับ $O(N)$ หรือทำระบบพังเอาได้ง่ายๆ เลยครับ!
3. 🧠 แก่นวิชา (Core Concepts)
คัมภีร์ Data Structures ระดับโลกได้ระบุวิธีมาตรฐานในการแก้ปัญหา (Collision Resolution Techniques) ไว้ 2 ท่าไม้ตายหลักๆ ดังนี้ครับ:
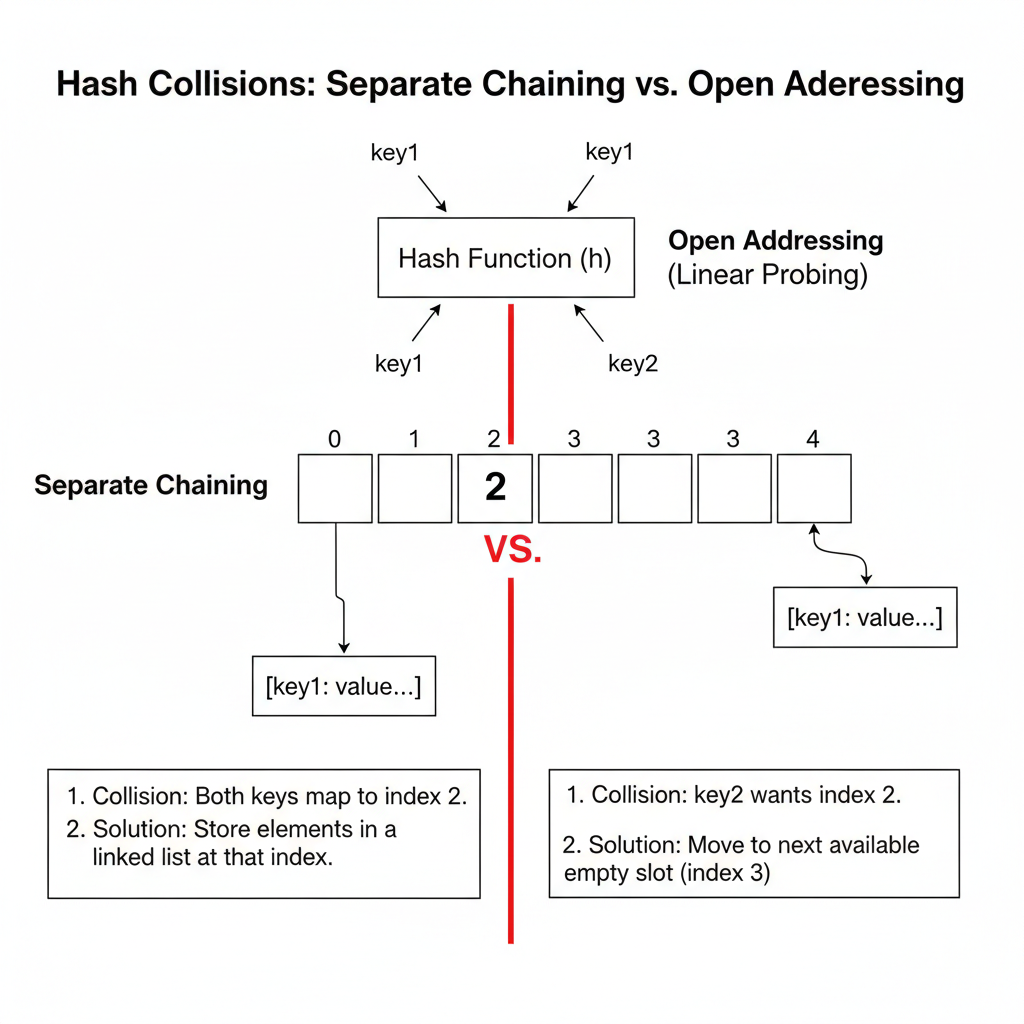
1. Separate Chaining (ต่อคิวเป็นสายโซ่)
- หลักการ: เป็นการคอมโบกันระหว่าง Array และ Linked List ครับ แทนที่ Array แต่ละช่องจะเก็บข้อมูลได้แค่ชิ้นเดียว เราจะให้มันทำหน้าที่เป็น “หัวแถว” ของ Linked List แทน
- เปรียบเทียบ: เหมือนล็อกเกอร์หมายเลข 8 มีคนใช้ไปแล้ว พอมีคนใหม่ที่ได้หมายเลข 8 เดินมาถึง เราก็แค่บอกว่า “อ๋อ ไม่เป็นไรครับ ยืนต่อแถว (Linked List) จากคนแรกตรงนี้ได้เลย!”
- ข้อดี/ข้อเสีย: เขียนโค้ดง่ายมาก และ Hash Table ไม่จำเป็นต้องจองพื้นที่ขนาดยักษ์ไว้ล่วงหน้า แต่ข้อควรระวังคือ ถ้าคนมาต่อคิวที่ช่องใดช่องหนึ่งยาวเกินไป การค้นหาข้อมูลในช่องนั้นจะถูกลดความเร็วลงจาก $O(1)$ เป็น $O(N)$ ทันที (เพราะต้องไล่เช็คทีละคิว)
2. Open Addressing (เดินหาช่องว่างเอาดาบหน้า)
- หลักการ: ท่านี้จะเก็บข้อมูลทั้งหมดลงใน Array ตรงๆ โดยไม่ใช้ Linked List แต่เมื่อเกิดการชนกัน มันจะใช้วิธี Probing (การตรวจหาตำแหน่งใหม่) แทน
- เปรียบเทียบ: เหมือนการขึ้นรถไฟใต้ดิน ถ้าน้องเดินไปที่นั่งหมายเลข 5 แล้วมีคนนั่งอยู่ น้องก็แค่เดินถัดไปดูที่นั่งหมายเลข 6, 7, 8 เรื่อยๆ จนกว่าจะเจอที่นั่งว่าง
- เทคนิคการเดินหา (Probing):
- Linear Probing: ขยับไปช่องถัดไปทีละ 1 ช่อง (ดื้อๆ แบบนี้แหละ) แต่อาจทำให้เกิดปัญหา Primary Clustering หรือ “ข้อมูลกระจุกตัวเป็นก้อน”
- Quadratic Probing: ขยับเป็นระยะทางยกกำลังสอง ($+1^2, +2^2, +3^2$) เพื่อหนีการกระจุกตัว
- Double Hashing: เอาคีย์ไปเข้า Hash Function อีกตัวนึง เพื่อหา “ระยะก้าว (Step Size)” แบบสุ่มที่ไม่ซ้ำกันเลย วิธีนี้ FAANG ชอบมากเพราะกระจายข้อมูลได้เนียนสุดๆ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
วันนี้พี่จะโชว์โค้ดวิชา Separate Chaining ด้วยภาษา Python ครับ เพราะเป็นท่าที่เข้าใจง่าย และเป็นพื้นฐานในการต่อยอดระบบใหญ่ๆ เราจะใช้ Array ร่วมกับ Node ของ Linked List ครับ
# 1. สร้างพิมพ์เขียวของ Node สำหรับ Linked List
class Node:
def __init__(self, key, value):
self.key = key # เก็บ Key ไว้ด้วย เพื่อใช้เปรียบเทียบตอนค้นหา
self.value = value
self.next = None # ลายแทงชี้ไปยังคนต่อไป
# 2. สร้าง Hash Table
class HashTable:
def __init__(self, size):
self.size = size
# สร้าง Array ช่องว่างๆ เตรียมไว้ตามขนาดที่กำหนด
self.table = [None] * size
def insert(self, key, value):
# โยน key เข้า Hash Function (ใช้ฟังก์ชัน hash() ของ Python ดื้อๆ เลย)
# แล้ว modulo ด้วย size เพื่อให้อยู่ในขอบเขตล็อกเกอร์ของเรา
index = hash(key) % self.size
# ถ้าล็อกเกอร์ช่องนี้ยังว่างอยู่... จัดไป! เสียบเลย
if self.table[index] is None:
self.table[index] = Node(key, value)
print(f"✅ ใส่ {key} ลงในช่องที่ {index}")
else:
# 💥 อุ๊ย! เกิด Collision แล้ว! งั้นเราใช้วิชา Separate Chaining
current = self.table[index]
print(f"⚠️ ชนโครม! {key} ต้องต่อคิวที่ช่อง {index}")
while current:
# ถ้า key ซ้ำกับที่เคยมี ให้รันทับ (Update Value)
if current.key == key:
current.value = value
return
# ถ้าเจอปิดท้ายคิว (None) ให้หยุด
if current.next is None:
break
current = current.next
# ผูกคิวคนใหม่ ต่อท้ายคนที่อยู่ก่อนหน้า
current.next = Node(key, value)
# ----- ลองวิชา -----
ht = HashTable(5)
ht.insert("Apple", 10)
ht.insert("Banana", 20)
# สมมติว่า Mango ดัน Hash ออกมาได้ Index เดียวกับ Apple
ht.insert("Mango", 30) 5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ความลับที่ Senior Engineer ใช้ในการจูน Performance ของ Hash Table คือสิ่งที่เรียกว่า Load Factor (ความหนาแน่น) ครับ
สมการคือ: Load Factor = จำนวนข้อมูลที่ใส่เข้าไป / จำนวนช่อง (Size) ของ Array
- กฎเหล็กของ Separate Chaining: คัมภีร์ Data Structures & Algorithms บอกไว้ว่า เราควรคุม Load Factor ให้อยู่ที่ไม่เกิน 1.0 (หรือโดยเฉลี่ย 1 ช่อง มีคนต่อคิว 1 คน) ถ้ายาวกว่านี้ Time Complexity จะเริ่มเสื่อมสภาพไปสู่ $O(N)$
- กฎเหล็กของ Open Addressing: ห้ามให้ Load Factor เกิน 0.5 ถึง 0.7 เด็ดขาด! เพราะถ้าล็อกเกอร์เริ่มเต็มเกิน 70% การเดินหาช่องว่าง (Probing) จะเกิดการชนแล้วชนอีก (Clustering) รันช้าจน Timeout ทันที
เมื่อถึงจุดที่ Load Factor เกินขีดจำกัด สิ่งที่เราต้องทำคือการ Rehashing (การขยายตู้ล็อกเกอร์ให้ใหญ่ขึ้น 2 เท่า แล้วคำนวณคีย์เก่าทั้งหมดลงตู้ใหม่) ซึ่งกระบวนการนี้จะกินเวลาหนักมาก ดังนั้นการคาดการณ์ Size ของข้อมูลล่วงหน้าตั้งแต่ตอนสร้างตาราง จึงเป็นสกิลที่แยก Dev ทั่วไป กับ Senior Dev ออกจากกันครับ!
6. 🏁 บทสรุป (To be continued…)
Hash Collisions ไม่ใช่เรื่องผิดปกติหรือบั๊กของระบบ แต่มันเป็นธรรมชาติของโครงสร้างข้อมูลที่เราต้องเตรียมแผนรับมือ (Collision Resolution) ไม่ว่าจะเป็นการต่อคิว (Separate Chaining) หรือการเดินหาช่องใหม่ (Open Addressing) หากน้องๆ เข้าใจหลักการเหล่านี้ รับรองว่าตอบคำถามสัมภาษณ์ผ่านฉลุย และสามารถออกแบบระบบแคชระดับสเกลใหญ่ได้อย่างมั่นใจครับ
ในตอนหน้า เราจะโบกมือลาโครงสร้างข้อมูลแบบเส้นตรง แล้วพุ่งทะยานเข้าสู่โลกของ Trees (โครงสร้างต้นไม้) เริ่มต้นด้วย Binary Search Tree อาวุธลับเบื้องหลัง Database Indexing เตรียมตัวให้พร้อม แล้วเจอกันครับ!
ต้องการที่ปรึกษาด้านการออกแบบ System Architecture และพัฒนาระบบซอฟต์แวร์สเกลใหญ่ให้กับองค์กรของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและพัฒนาซอฟต์แวร์แบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p