เจาะลึก Linked Lists แบบต่างๆ: ทำไมเดินหน้าอย่างเดียวถึงไม่พอ?

1. 🎯 ตอนที่ 4: เจาะลึก Linked Lists แบบต่างๆ (Singly, Doubly, Circular)
2. 📖 เปิดฉาก (The Hook)
จากตอนที่แล้ว เราได้เห็นความเทพของ Linked List ที่สามารถแทรกและลบข้อมูลได้ไวระดับ $O(1)$ ชนะ Array ไปแบบขาดลอยเมื่อต้องจัดการกับข้อมูลที่มีการเปลี่ยนแปลงบ่อยๆ แต่น้องๆ รู้ไหมครับว่า Singly Linked List (ลิงก์ลิสต์แบบทางเดียว) ที่เราเพิ่งรู้จักกันไปนั้น มีจุดอ่อนร้ายแรงซ่อนอยู่!
ลองจินตนาการว่าน้องกำลังเขียนแอปฟังเพลงแข่งกับ Spotify น้องเก็บคิวเพลงแบบ Singly Linked List การกด “Next” ไปเพลงถัดไปทำได้สบายมาก… แต่เดี๋ยวก่อน! ถ้าผู้ใช้กดปุ่ม “Previous” เพื่อกลับไปฟังเพลงเมื่อกี้ล่ะ? ชิบหายแล้วครับ ลายแทง (Pointer) ของเรามันชี้ไปข้างหน้าได้อย่างเดียว! ถ้าจะกลับไปเพลงก่อนหน้า น้องต้องเริ่มวิ่งไล่หาใหม่ตั้งแต่เพลงแรกสุดของเพลย์ลิสต์!
ปัญหาหน้างานแบบนี้แหละครับที่บังคับให้โปรแกรมเมอร์ต้องคิดค้นและวิวัฒนาการโครงสร้างข้อมูล วันนี้พี่จะพาไปเจาะลึก Linked List ร่างอีโว ทั้ง Doubly Linked List และ Circular Linked List ว่ามันเกิดมาเพื่อแก้ปัญหาอะไร และบริษัทระดับ FAANG เอาไปใช้ออกแบบระบบแบบไหนกัน!
3. 🧠 แก่นวิชา (Core Concepts)
เรามาดูวิวัฒนาการของโครงสร้างข้อมูลตระกูล Linked List จากคัมภีร์ Coding Interview Patterns และ Data Structures and Algorithms กันครับ
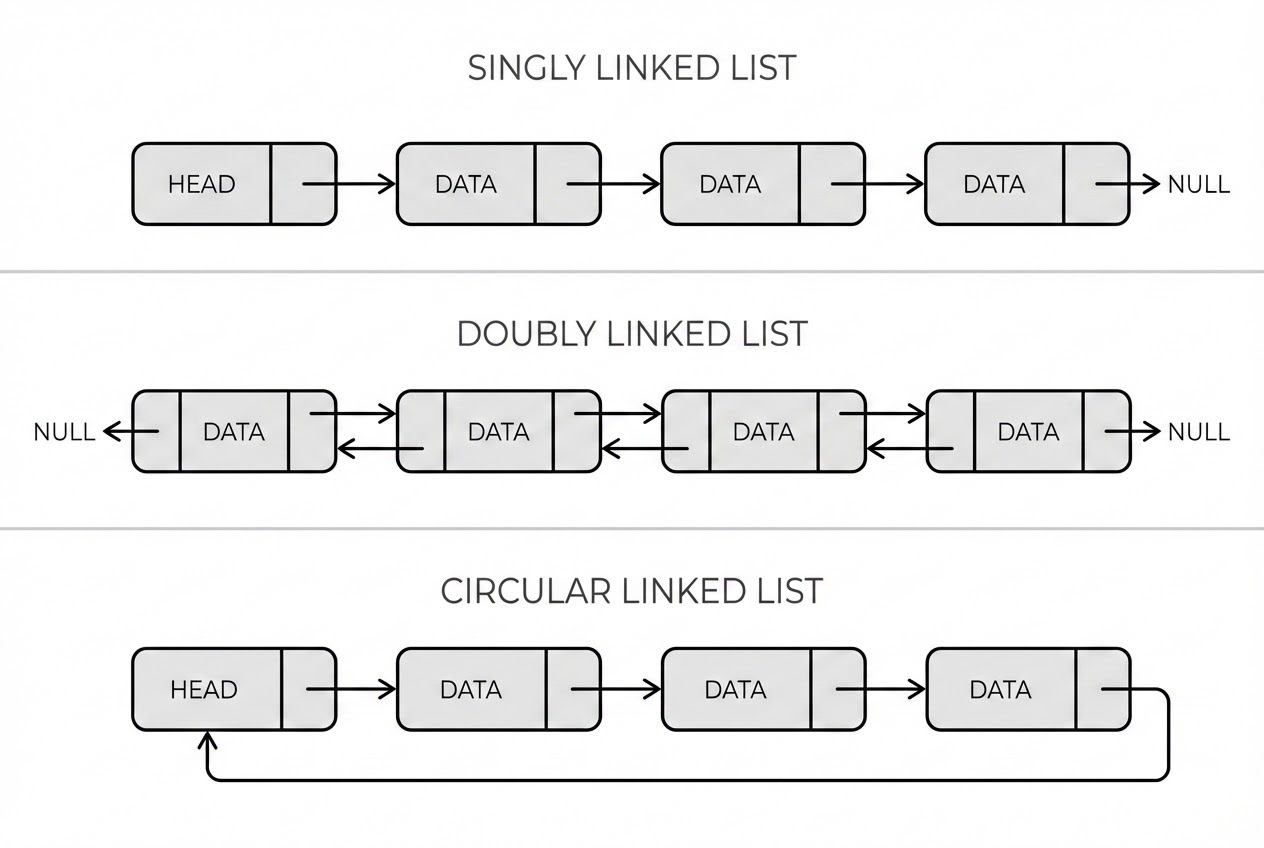
1. Singly Linked List (ถนนวันเวย์)
- โครงสร้าง: แต่ละ Node จะมีแค่ข้อมูล (Data) และ Pointer (Next) ที่ชี้ไปยัง Node ถัดไป ส่วนตัวสุดท้ายจะชี้ไปที่
NULL(ทางตัน) - จุดอ่อน: วิ่งกลับหลังไม่ได้ และถ้าเรามี Pointer ชี้อยู่ที่โหนดๆ หนึ่ง แล้วต้องการ “ลบ” โหนดนั้นทิ้ง มันจะทำในเวลา $O(1)$ ไม่ได้! เพราะเราต้องรู้ว่า “ใครคือคนก่อนหน้าเรา” เพื่อจับ Pointer ของคนก่อนหน้ามาเชื่อมต่อใหม่ ซึ่งการหาคนก่อนหน้าต้องเริ่มหาใหม่ตั้งแต่ Head ใช้เวลา $O(N)$
2. Doubly Linked List (ถนนเลนสวน)
- โครงสร้าง: อัปเกรด Node ให้มี Pointer 2 ตัว คือ
next(ชี้ไปข้างหน้า) และprev(ชี้กลับหลัง) - ทำไมถึงต้องมี Pointer ชี้กลับหลัง?: เพราะมันปลดล็อกพลังการเดินหน้า-ถอยหลัง (Bidirectional traversal) และที่สำคัญที่สุดคือ ปลดล็อกการลบ Node ในเวลา $O(1)$ ได้อย่างแท้จริง เพราะเรารู้ตัวคนก่อนหน้า (ผ่าน
prev) และคนถัดไป (ผ่านnext) ทันทีโดยไม่ต้องเริ่มค้นหาใหม่ตั้งแต่ต้น! - Use Case: ระบบ Music Playlist, ปุ่ม Undo/Redo ในโปรแกรม Word, และการทำ LRU Cache (เดี๋ยวพี่เล่าใน Pro-Tips)
3. Circular Linked List (วงเวียนไม่รู้จบ)
- โครงสร้าง: เหมือน Singly หรือ Doubly ทุกอย่าง แต่จุดไคลแมกซ์คือ “Node สุดท้าย (Tail) จะชี้กลับมาที่ Node แรก (Head) เสมอ” ไม่มี
NULLให้หยุด - Use Case: เกมกระดานแบบเทิร์นเบส (พอวนถึงผู้เล่นคนสุดท้าย ก็กลับมาตาคนแรกใหม่), ระบบปฏิบัติการที่ใช้จัดคิว CPU ให้โปรแกรมต่างๆ ทำงานสลับกันแบบ Round-Robin Scheduling
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อโชว์ความเทพของ Doubly Linked List พี่จะเขียนโค้ด Python ในการ “ลบ Node” ออกจากตรงกลาง List แบบไวแสง $O(1)$ ให้ดูครับ
# สร้างพิมพ์เขียวของ Doubly Linked List Node
class DoublyNode:
def __init__(self, data):
self.data = data
self.next = None # ชี้ไปคนข้างหน้า
self.prev = None # ชี้กลับหลังหาคนก่อนหน้า
def delete_node(node_to_delete):
# สมมติว่าเราจับตัว node_to_delete ได้แล้ว และอยากลบมันทิ้ง
# เช็คก่อนว่าโหนดนี้มีคนก่อนหน้าไหม (ไม่ใช่ Head)
if node_to_delete.prev is not None:
# สั่งให้ "คนก่อนหน้าเรา" ชี้ข้ามหัวเรา ไปหา "คนถัดจากเรา" เลย
node_to_delete.prev.next = node_to_delete.next
# เช็คว่าโหนดนี้มีคนถัดไปไหม (ไม่ใช่ Tail)
if node_to_delete.next is not None:
# สั่งให้ "คนถัดจากเรา" ชี้กลับหลังข้ามหัวเรา ไปหา "คนก่อนหน้าเรา"
node_to_delete.next.prev = node_to_delete.prev
# แค่นี้ node_to_delete ก็หลุดออกจากสายวงจร ลอยเคว้ง รอให้ Garbage Collector มาเก็บกวาด
# ใช้เวลาทำงานแค่ O(1) ชิลๆ!5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ถ้าน้องไปสัมภาษณ์งานตำแหน่ง Backend หรือ System Design ที่บริษัทใหญ่ๆ คำถามระดับบอสที่เจอบ่อยมากคือ “จงออกแบบ LRU Cache (Least Recently Used Cache)”
จากคัมภีร์ Coding Interview Patterns ของ Alex Xu การจะทำ LRU Cache ให้ดึงข้อมูลก็ไว $O(1)$ และอัปเดตข้อมูลก็ไว $O(1)$ เราต้องใช้การคอมโบกันระหว่าง Hash Map (ดิกชันนารี) + Doubly Linked List ครับ!
- Hash Map เอาไว้ค้นหาข้อมูลให้เจอใน $O(1)$
- Doubly Linked List เอาไว้เรียงลำดับว่าข้อมูลไหนถูกใช้ล่าสุด (อยู่ Head) ข้อมูลไหนไม่ได้ใช้นานแล้ว (อยู่ Tail เตรียมโดนเตะทิ้ง)
- เมื่อข้อมูลถูกเรียกใช้ เราจะใช้ Hash Map กระโดดไปหา Node นั้นทันที แล้วใช้พลังของ Doubly Linked List สับเปลี่ยน Pointer เตะ Node นั้นขึ้นมาไว้ที่ Head ภายในเวลา $O(1)$ นี่คือเวทมนตร์แห่งวงการวิศวกรรมซอฟต์แวร์เลยครับ!
ข้อควรระวังเดียวของ Doubly Linked List คือ Space Complexity เพราะการเก็บ prev Pointer เพิ่ม 1 ตัวในทุกๆ โหนด หมายความว่าน้องต้องเสีย Memory เพิ่มขึ้น ถ้าระบบมีข้อมูลพันล้านเรคคอร์ด ก็คือเสีย Memory ไปฟรีๆ พันล้าน Pointers ดังนั้นเลือกใช้ให้คุ้มค่ากับ Trade-off นะครับ
6. 🏁 บทสรุป (To be continued…)
จะเห็นได้ว่า Linked List ไม่ได้มีแค่แบบเดียว การเพิ่ม Pointer ชี้กลับหลัง (Doubly) หรือการจับหางชนหัว (Circular) ล้วนเกิดมาเพื่อแก้ปัญหา Time Complexity เฉพาะทางบางอย่าง หน้าที่ของ Senior Engineer คือการมองให้ออกว่าฟีเจอร์ที่เรากำลังสร้าง เหมาะสมกับโครงสร้างแบบไหนที่สุดครับ
ในตอนหน้า เราจะเอา Array และ Linked List ที่เราเรียนกันมาอย่างทะลุปรุโปร่ง ไปสร้างเป็นโครงสร้างข้อมูลตัวใหม่ที่ชื่อว่า Stacks (กองตั้ง) และ Queues (คิวต่อแถว) เตรียมตัวให้พร้อม แล้วพบกันครับ!
ต้องการที่ปรึกษาด้านการออกแบบ System Architecture และพัฒนาระบบซอฟต์แวร์สเกลใหญ่ให้กับองค์กรของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและพัฒนาซอฟต์แวร์แบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p