รู้จัก Big O Notation ภาษากลางของการวัดประสิทธิภาพโค้ด
1. 🎯 ตอนที่ 2: รู้จัก Big O Notation ภาษากลางของการวัดประสิทธิภาพโค้ด
2. 📖 เปิดฉาก (The Hook)
น้องๆ เคยสงสัยไหมครับว่า ทำไมโค้ดที่เราเขียน รันทดสอบด้วยข้อมูล 100 ชิ้น ใช้เวลาแค่เสี้ยววินาที แต่พอเอาไปใช้จริงกับข้อมูลระดับพันล้านชิ้น ระบบกลับค้างไปเป็นวัน? มีเรื่องเล่าจากตำรา Grokking Algorithms ว่าโปรแกรมเมอร์คนหนึ่งเขียนโค้ดค้นหาข้อมูล ถ้าค้นหาข้อมูล 100 ชิ้นใช้เวลา 100 มิลลิวินาที เขาคิดว่าถ้าข้อมูล 1 พันล้านชิ้น ก็คงใช้เวลาแค่ 11 วัน แต่ในความเป็นจริง หากเขาเลือกใช้อัลกอริทึมที่ถูกต้อง มันอาจจะใช้เวลาเพียงแค่ 32 มิลลิวินาทีเท่านั้น!
ความแตกต่างระดับ “เสี้ยววินาที” กับ “สิบเอ็ดวัน” นี่แหละครับคือเหตุผลที่โปรแกรมเมอร์ระดับ Senior และบริษัท FAANG ให้ความสำคัญกับสิ่งที่เราเรียกว่า Big O Notation มันไม่ใช่การมานั่งจับเวลาเป็นวินาที เพราะคอมพิวเตอร์แต่ละเครื่องเร็วไม่เท่ากัน แต่มันคือ “ภาษากลาง” ที่เราใช้คุยกันว่า โค้ดของเราจะทำงานช้าลงแค่ไหนเมื่อข้อมูล (Data) มีขนาดใหญ่ขึ้นนั่นเองครับ
3. 🧠 แก่นวิชา (Core Concepts)
ก่อนจะไปดูว่า Big-O มีอะไรบ้าง เราต้องรู้จัก 2 คำศัพท์สำคัญที่เป็นมาตรวัดประสิทธิภาพของอัลกอริทึมกันก่อนครับ:
- Time Complexity (ความซับซ้อนด้านเวลา): ไม่ใช่การวัดเวลาเป็นวินาที แต่คือการวัดว่า “อัลกอริทึมนี้ต้องใช้จำนวนก้าว (Steps) ในการทำงานกี่ก้าว เมื่อเทียบกับขนาดของข้อมูล (N)”
- Space Complexity (ความซับซ้อนด้านพื้นที่): คือการวัดว่าอัลกอริทึมของเราต้องการ “หน่วยความจำส่วนเพิ่ม (Auxiliary Space)” มากแค่ไหนเมื่อข้อมูลใหญ่ขึ้น การสร้าง Array ใหม่เพื่อเก็บข้อมูลชั่วคราว คือการเพิ่ม Space Complexity นั่นเอง
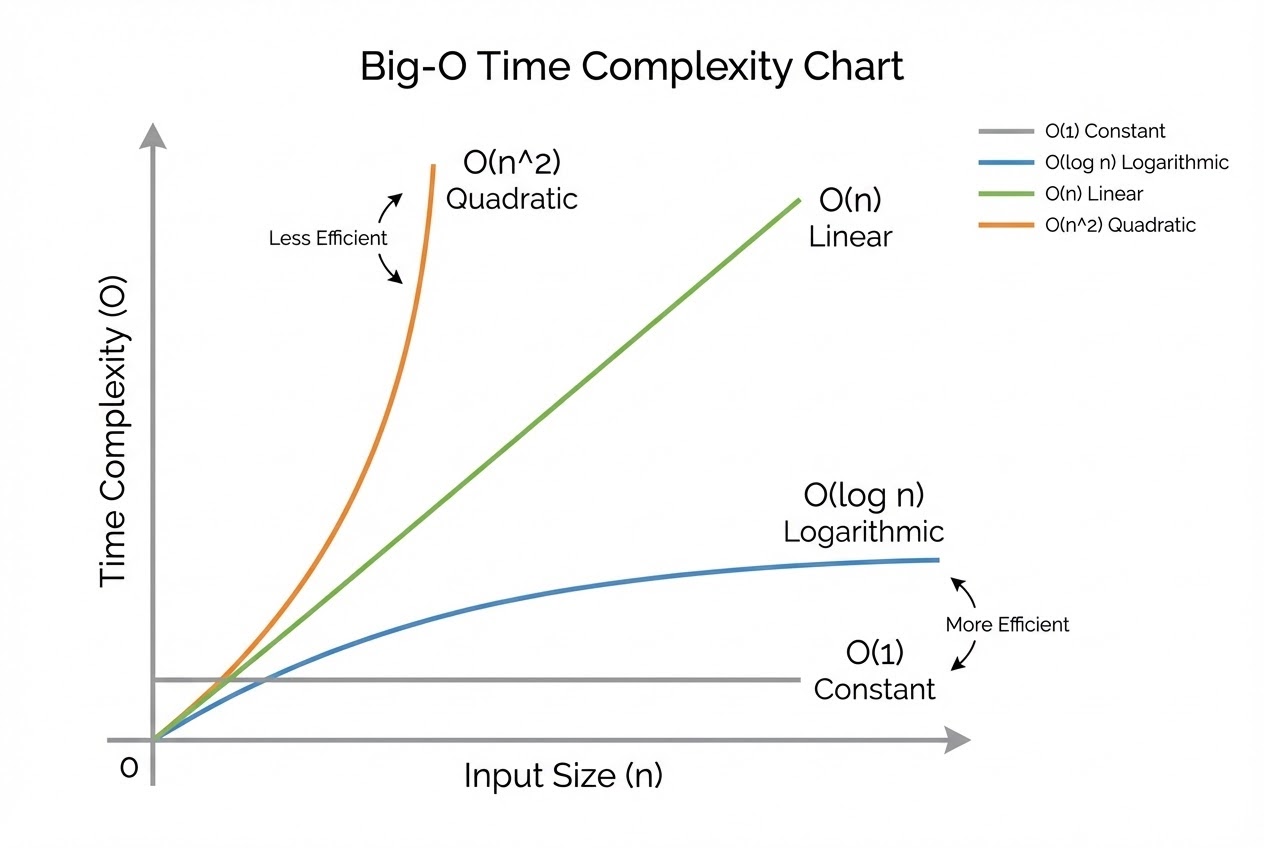
ทีนี้เรามาทำความรู้จักกับแก๊งค์ Big O Notation ที่เจอบ่อยๆ เรียงจากความเร็วระดับเทพ ไปจนถึงระดับเต่าคลานกันครับ:
- O(1) - Constant Time (เวลาคงที่): เร็วที่สุด! ไม่ว่าข้อมูลจะมี 10 ชิ้น หรือ 1 ล้านชิ้น ก็ใช้เวลาทำงานเท่าเดิมเสมอ
- เปรียบเทียบ: เหมือนการหยิบหนังสือเล่มบนสุดจากกองหนังสือ หรือการดึงข้อมูลจาก Array ด้วย Index ที่เรารู้อยู่แล้ว (เช่น
arr)
- เปรียบเทียบ: เหมือนการหยิบหนังสือเล่มบนสุดจากกองหนังสือ หรือการดึงข้อมูลจาก Array ด้วย Index ที่เรารู้อยู่แล้ว (เช่น
- O(log n) - Logarithmic Time (เวลาแบบลอการิทึม): โค้ดทำงานไวมาก เพราะทุกครั้งที่ทำงาน มันจะหั่นข้อมูลทิ้งไป “ครึ่งหนึ่ง” เสมอ
- เปรียบเทียบ: เหมือนการหาคำศัพท์ในพจนานุกรม เราไม่เปิดหาทีละหน้า แต่เราเปิดตรงกลางแล้วฉีกครึ่งที่ไม่ใช่ออกไปเรื่อยๆ (Binary Search)
- O(n) - Linear Time (เวลาแบบเชิงเส้น): เวลาที่ใช้ทำงานเพิ่มขึ้นเป็นเส้นตรงตามปริมาณข้อมูล ข้อมูลมี N ชิ้น ก็ต้องทำงาน N รอบ
- เปรียบเทียบ: เหมือนการไล่หาหนังสือทีละเล่มบนชั้นวางตั้งแต่เล่มแรกยันเล่มสุดท้าย (Linear Search) หรือการวนลูป
forอ่านข้อมูลใน Array แบบธรรมดา
- เปรียบเทียบ: เหมือนการไล่หาหนังสือทีละเล่มบนชั้นวางตั้งแต่เล่มแรกยันเล่มสุดท้าย (Linear Search) หรือการวนลูป
- O(n^2) - Quadratic Time (เวลาแบบยกกำลังสอง): เริ่มเข้าสู่หายนะเมื่อข้อมูลใหญ่ขึ้น โค้ดประเภทนี้มักเกิดจากการใช้ลูปซ้อนลูป (Nested Loops)
- เปรียบเทียบ: เหมือนการจับคู่หนังสือทุกเล่มบนชั้นกับหนังสือเล่มอื่นๆ เพื่อดูว่ามีเล่มไหนซ้ำกันบ้าง ยิ่งของเยอะ ยิ่งใช้เวลามหาศาล อัลกอริทึมจัดเรียงข้อมูลแบบบ้านๆ เช่น Bubble Sort ก็ตกอยู่ในหมวดหมู่นี้
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้เห็นภาพชัดเจน ลองมาดูตัวอย่างโค้ด Python ที่โชว์ความแตกต่างของ Time Complexity ในแต่ละระดับกันครับ
# 1. O(1) - Constant Time
# ไม่ว่า array จะมีขนาดใหญ่แค่ไหน การดึงข้อมูลช่องแรกก็ใช้เวลาเท่าเดิมเสมอ
def get_first_element(arr):
return arr
# 2. O(n) - Linear Time
# ต้องวนลูปเช็คข้อมูลทีละตัว ยิ่ง N เยอะ ยิ่งใช้เวลานานขึ้นตามสัดส่วน
def find_target_linear(arr, target):
for num in arr:
if num == target:
return True
return False
# 3. O(n^2) - Quadratic Time
# ลูปซ้อนลูป (Nested Loops) เพื่อเช็คว่ามีตัวเลขซ้ำกันหรือไม่
# ถ้าข้อมูลมี 100 ชิ้น โค้ดอาจต้องรันถึง 10,000 รอบ!
def has_duplicates(arr):
n = len(arr)
for i in range(n):
for j in range(i + 1, n): # เช็คจับคู่ทุกตัว
if arr[i] == arr[j]:
return True
return False5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในโลกของการสัมภาษณ์งานและการวิเคราะห์ระบบจริง มีกฎเหล็ก 2 ข้อจากคัมภีร์ A Common-Sense Guide to Data Structures and Algorithms ที่รุ่นพี่ Senior ทุกคนท่องจำจนขึ้นใจ:
- Big O สนใจแค่ภาพรวม ห้ามใส่ค่าคงที่ (Big O ignores constants): ต่อให้อัลกอริทึมของคุณจะต้องรันลูป 2 รอบ (คือ $O(2N)$) หรือต้องทำงานเพิ่มอีกนิดหน่อย (เช่น $O(N + 10)$) เวลาเราพูดในเชิง Big O เราจะปัดเศษทิ้งเหลือแค่ $O(N)$ เท่านั้นครับ เพราะ Big O ต้องการบอก “หมวดหมู่” ของการเติบโต การเอา $O(2N)$ ไปเทียบกับ $O(N^2)$ ก็เหมือนเอาบ้านสองชั้นไปเทียบกับตึกระฟ้า ยังไงมันก็จัดอยู่ในหมวดหมู่ $O(N)$ เหมือนกัน
- เตรียมพร้อมสำหรับเหตุการณ์ที่เลวร้ายที่สุด (Worst-case Scenario): เวลาเราพูดว่าโค้ดนี้มีความซับซ้อน $O(N)$ เราหมายถึง “ในกรณีที่โชคร้ายที่สุด” เช่น การหาเบอร์โทรศัพท์เพื่อนในสมุดหน้าเหลือง เพื่อนอาจจะอยู่หน้าแรกเลย ($O(1)$) แต่นั่นคือความฟลุ๊ค Big O จะมองว่า ถ้าเพื่อนอยู่หน้าสุดท้ายล่ะ? เราก็ต้องเปิดหา N หน้าอยู่ดี ดังนั้นเราจึงยึด Worst-case หรือ $O(N)$ เป็นหลักเพื่อรับประกันว่าโปรแกรมเราจะไม่พังเมื่อเจองานหนักครับ
6. 🏁 บทสรุป (To be continued…)
สรุปสั้นๆ ให้จำขึ้นใจ: Big O Notation คือเรื่องของการดูว่า “จำนวนก้าวในการทำงาน” ของโค้ดเรามันเติบโตขึ้นเร็วแค่ไหนเมื่อ “ข้อมูลมีขนาดใหญ่ขึ้น” การที่เราเข้าใจว่าเมื่อไหร่ควรใช้โค้ดแบบ $O(1)$, $O(\log n)$, หรือเมื่อไหร่ควรหลีกเลี่ยง $O(n^2)$ จะช่วยให้เราสามารถสเกลระบบเพื่อรองรับผู้ใช้งานหลักล้านได้โดยไม่ทำให้เซิร์ฟเวอร์ระเบิดครับ
ในตอนหน้า พี่จะพาไปเจาะลึกสุดยอดโครงสร้างข้อมูลพื้นฐานอย่าง Array และ Linked List ว่าเบื้องหลังการจัดเก็บข้อมูลใน Memory มันทำงานยังไง แล้วทำไมถึงเป็นท่าไม้ตายในการลด Time Complexity ได้อย่างไม่น่าเชื่อ เตรียมตัวให้พร้อมแล้วเจอกันครับน้องๆ!
ต้องการที่ปรึกษาด้านการออกแบบ System Architecture และพัฒนาระบบซอฟต์แวร์สเกลใหญ่ให้กับองค์กรของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและพัฒนาซอฟต์แวร์แบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p