ถอดรหัส mAP (Mean Average Precision): ตัวชี้วัดระดับจักรวาลที่ใช้ตัดสินความเก่งของ Object Detection
1. 🎯 ตอนที่ 44: ถอดรหัส mAP ตัวชี้วัดระดับจักรวาล
สวัสดีครับน้องๆ วิศวกรสาย Vision และนักพัฒนา AI ทุกท่าน! กาแฟพร้อมแล้วใช่ไหมครับ ในตอนที่แล้วเราคุยกันเรื่อง IoU (Intersection over Union) ซึ่งเป็นไม้บรรทัดวัดความแม่นยำของกรอบสี่เหลี่ยม (Bounding Box) แบบรายกล่องกันไปแล้ว
แต่คำถามที่สำคัญกว่านั้นคือ… เวลาที่เราต้องการสรุปว่า “โมเดล YOLO หรือ Faster R-CNN ตัวนี้มีความเก่งโดยรวมกี่เปอร์เซ็นต์?” เราจะใช้อะไรวัดครับ? ถ้าน้องตอบว่า “ก็ใช้ Accuracy (ความแม่นยำ) ไงพี่!” พี่บอกเลยว่าในโลกของ Object Detection การใช้ Accuracy ธรรมดาคือ “หายนะ” ครับ!
ในบริบทที่กว้างขึ้นของ Object Detection ตัวชี้วัดมาตรฐานทองคำ (Gold Standard) ที่นักวิจัยทั่วโลกใช้ตัดสินว่าใครคือจ้าวแห่งการตรวจจับวัตถุ มีชื่อว่า mAP (Mean Average Precision) ครับ วันนี้พี่จะพาน้องๆ ไปขุดคุ้ยที่มาของสมการนี้กันว่า ทำไมมันถึงเป็นตัวชี้วัดที่ทรงพลังที่สุด!
2. 📖 เปิดฉาก (The Hook)
ทำไมเราถึงใช้ Accuracy แบบงาน Image Classification ธรรมดาไม่ได้? ลองนึกภาพน้องทำระบบ AI จับผิดรอยร้าวบนถนน (Crack detection) ในภาพ 1 ภาพ พื้นที่ 99% คือถนนปกติ (Background) และมีรอยร้าวแค่ 1% ถ้าน้องสร้างโมเดล “ขี้เกียจ” ที่หลับตาทายว่า “ทุกอย่างคือถนนปกติหมด ไม่มีรอยร้าวเลย!” โมเดลตัวนี้จะได้ Accuracy 99% ทันทีครับ! (ทายถูกว่าไม่มีรอยร้าวบนพิกเซลส่วนใหญ่) แต่มันใช้งานจริงไม่ได้เลย เพราะมันหาของที่เราอยากเจอไม่เจอ!
งาน Object Detection จึงมีความท้าทายพิเศษตรงที่มันเป็นข้อมูลที่ไม่สมดุลอย่างรุนแรง (Imbalanced Data) การบอกว่าโมเดลเก่ง จึงต้องบาลานซ์ระหว่าง:
- การไม่ทายมั่วซั่ว หรือไม่ทำ False Alarm (นี่คือ Precision)
- การหาของที่ซ่อนอยู่ให้เจอให้หมด (นี่คือ Recall)
และพระเอกที่จะมาผนบรวมสองสิ่งนี้เข้าด้วยกันจนกลายเป็นตัวเลขสวยๆ ค่าเดียว ก็คือ mAP นั่นเองครับ!
3. 🧠 แก่นวิชา (Core Concepts)
แหล่งข้อมูลระดับโลกได้อธิบายกระบวนการคำนวณ mAP ไว้เป็นขั้นเป็นตอนอย่างสวยงาม ดังนี้ครับ:
- 1. ตัดสินถูกผิดด้วย IoU: ก่อนอื่น ระบบจะใช้ค่า IoU มาตัดสินว่ากล่องที่ AI ทายมา (Predicted box) นั้นถือว่าเป็น True Positive (TP - ทายถูก) หรือ False Positive (FP - ทายผิด/ทายมั่ว) โดยทั่วไปจะตั้งเกณฑ์ IoU threshold ไว้ที่ 0.5 (กล่องทับเฉลยเกิน 50% ถือว่าสอบผ่าน)
- 2. ความแม่นยำ vs ความครอบคลุม (Precision & Recall):
- Precision (ความแม่นยำ): ในบรรดากล่องทั้งหมดที่ AI ทายออกมา มันทายถูกกี่เปอร์เซ็นต์? (ยิ่งพ่นกล่องขยะออกมาเยอะ Precision ยิ่งตก)
- Recall (ความครอบคลุม): ในบรรดาวัตถุของจริงทั้งหมดที่มีในภาพ AI หาเจอกี่เปอร์เซ็นต์? (ยิ่งพลาดวัตถุเยอะ Recall ยิ่งตก)
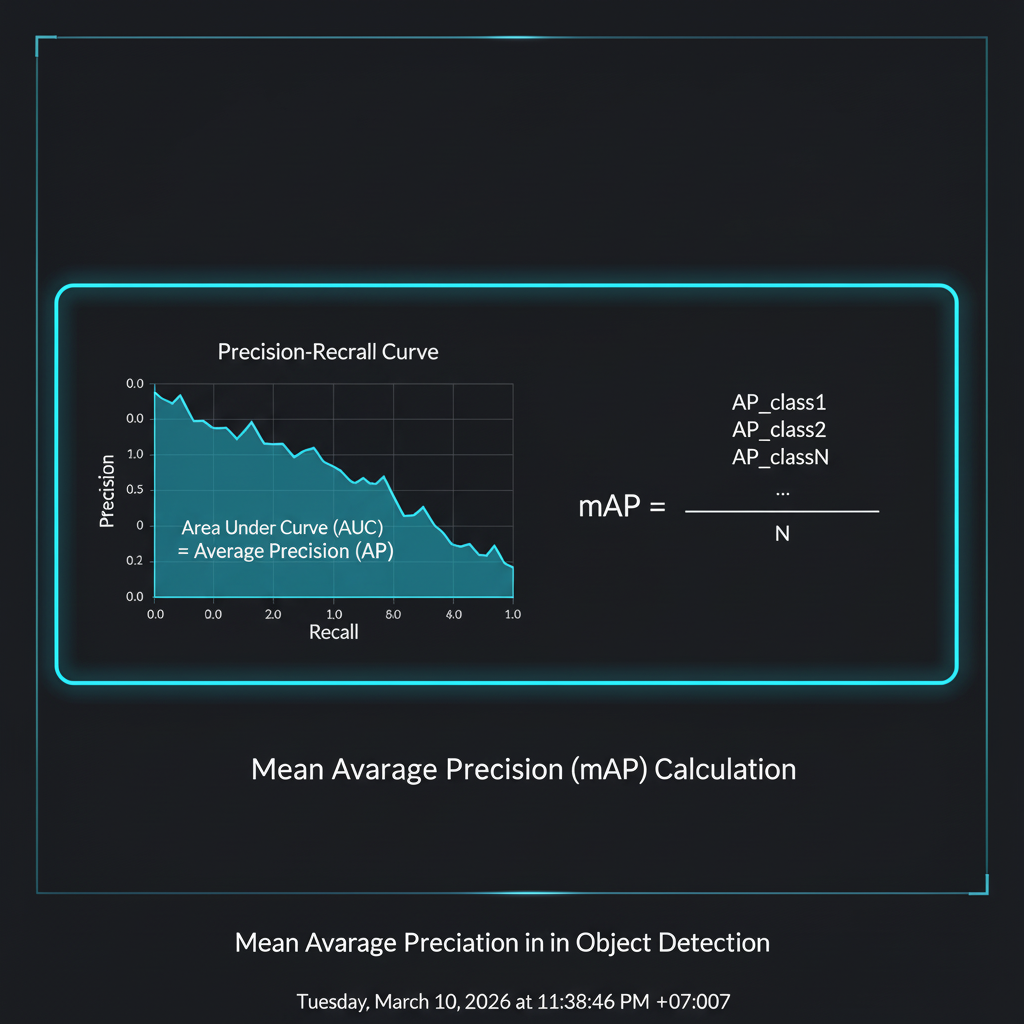
- 3. กราฟแห่งการประนีประนอม (Precision-Recall Curve): ปกติแล้วธรรมชาติของ AI คือ ถ้ายิ่งพยายามหาของให้เจอให้หมด (Recall สูง) มันก็จะยิ่งทายมั่วเยอะขึ้น (Precision ตก) ถ้าเรานำค่าความมั่นใจ (Confidence Score) มาปรับเป็น Threshold ไล่ระดับไปเรื่อยๆ แล้วพล็อตจุดตัดระหว่าง Precision และ Recall เราจะได้กราฟที่เรียกว่า PR Curve
- 4. พื้นที่ใต้กราฟ AP (Average Precision): เพื่อที่จะสรุปความเก่งของกราฟ PR Curve ให้ออกมาเป็นตัวเลขค่าเดียว เราจะทำการคำนวณ “พื้นที่ใต้กราฟ (Area Under the Curve - AUC)” ครับ ค่าที่ได้นี้เรียกว่า Average Precision (AP) ซึ่งใช้บอกความเก่งของ AI ในการหาวัตถุ “คลาสใดคลาสหนึ่ง (Single Class)” เท่านั้น
- 5. สู่จุดสูงสุด mAP (Mean Average Precision): เมื่อเรามีวัตถุหลายคลาส (เช่น หมา, แมว, รถ) เราก็จะคำนวณค่า AP ของแต่ละคลาสออกมา แล้วนำค่า AP ทั้งหมดมา “หาค่าเฉลี่ย (Mean)” อีกทีหนึ่ง จึงกลายเป็น mAP ในที่สุดครับ!
สมการของการหา mAP พื้นฐานเขียนได้ว่า:
$$ mAP = \frac{1}{C} \sum_{i=1}^{C} AP_i $$
(เมื่อ $C$ คือจำนวนคลาสทั้งหมด และ $AP_i$ คือค่า Average Precision ของคลาสที่ $i$)
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
การคำนวณ mAP ด้วยตัวเองตั้งแต่ต้น (From scratch) เป็นเรื่องที่โค้ดยาวและซับซ้อนมากครับ เพราะต้องมีการหาพื้นที่ใต้กราฟแบบ Interpolation (เช่น 11-point interpolation ตามมาตรฐาน PASCAL VOC) แต่ในโลกการทำงานจริง ไลบรารีระดับโลกอย่าง TensorFlow หรือระบบของ Mask R-CNN มักจะมีฟังก์ชันให้เรียกใช้สำเร็จรูปครับ ลองดูโครงสร้างการทำงานนี้:
import numpy as np
# -------------------------------------------------------------
# 📌 โครงสร้างการทำงานของฟังก์ชันคำนวณ mAP แบบภาพรวม (จำลอง)
# อ้างอิงจากลอจิกการหา mAP ในระบบ Mask R-CNN
# -------------------------------------------------------------
def evaluate_model(dataset, model, cfg):
APs = [] # ลิสต์เก็บค่า AP ของภาพแต่ละภาพ/คลาส
# วนลูปอ่านรูปภาพทุกรูปใน Dataset (เช่น ชุด Test set)
for image_id in dataset.image_ids:
# โหลดภาพและเฉลย (Ground Truth)
image, _, gt_class_id, gt_bbox, gt_mask = load_image_gt(dataset, cfg, image_id)
# ให้โมเดลทำการทำนายผล (Prediction)
results = model.detect([image], verbose=0)
# 📌 คำนวณค่า Average Precision (AP) ของภาพนี้
# ฟังก์ชันนี้เบื้องหลังจะเอา gt_bbox กับ pred_bbox มาหา IoU,
# จัดเรียง Confidence Score, พล็อต PR Curve และหาพื้นที่ใต้กราฟ (AUC)
AP, precisions, recalls, overlaps = compute_ap(
gt_bbox, gt_class_id, gt_mask,
results["rois"], results["class_ids"], results["scores"], results["masks"]
)
APs.append(AP)
# 📌 หาค่าเฉลี่ยของ AP ทั้งหมดเพื่อให้ได้ mAP
mAP = np.mean(APs)
return mAP
# ผลลัพธ์จากการเรียกใช้งาน
# print("Test mAP: %.3f" % test_mAP)คอมเมนต์: สังเกตว่าหัวใจหลักคือฟังก์ชัน compute_ap ครับ ซึ่งวิศวกรส่วนใหญ่เลือกใช้เครื่องมือวัดผลมาตรฐาน เช่น pycocotools หรือฟังก์ชันที่มาพร้อมกับไลบรารีแทนการเขียนเอง เพื่อป้องกันบั๊กในการคำนวณพื้นที่ใต้กราฟครับ
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในมุมมองของการแข่งขันและหน้างานจริง mAP มี “ภาษาเฉพาะ” ที่น้องๆ ต้องเข้าใจเวลาไปอ่านเปเปอร์วิจัย (Research Papers) ครับ:
- PASCAL VOC vs MS COCO:
- mAP@0.5 (แบบ PASCAL VOC): เป็นการคิด mAP โดยใช้เกณฑ์ IoU threshold ที่ 0.5 เสมอ (กล่องทับ 50% ถือว่าถูก)
- mAP@[.50:.95] (แบบ COCO Challenge): สุดยอดความโหด! งานวิจัยยุคใหม่จะใช้แบบนี้ครับ คือการคิด mAP ที่ IoU=0.50, ไปจนถึง IoU=0.95 (ขยับทีละ 0.05 รวม 10 ค่า) แล้วเอา mAP ทั้ง 10 ค่านั้น “มาหาค่าเฉลี่ยอีกรอบ (Mean of mean averages!)” วิธีนี้บังคับให้ AI ต้องตีกรอบให้ “แน่นเป๊ะ” แนบสนิทกับวัตถุจริงๆ ถึงจะได้คะแนนสูงครับ
- Weighted mAP (การแก้ปัญหาคลาสไม่สมดุล): ในกรณีที่ Dataset ของน้องมีรถ 10,000 คัน แต่มีคนเดินถนนแค่ 100 คน การคิดแบบเฉลี่ยตรงๆ (Macro average) อาจจะไม่ยุติธรรม แหล่งข้อมูลแนะนำให้ใช้ Weighted mAP ซึ่งเป็นการถ่วงน้ำหนักตามจำนวน Sample ของแต่ละคลาส ($w_i$) เพื่อให้คะแนนสะท้อนโลกความเป็นจริงมากขึ้นครับ
- เกณฑ์คะแนนที่น่าพอใจ: ค่า mAP > 35 ถือว่าดี และถ้า mAP > 45 ถือว่ายอดเยี่ยมมากในโลกของ Object Detection บนชุดข้อมูลที่ซับซ้อนอย่าง COCO ครับ (อย่าเผลอเอาไปเทียบกับ Accuracy 99% ของงาน Classification เชียวนะครับ มันคนละสเกลความยากกันเลย!)
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว mAP (Mean Average Precision) คือตัวชี้วัดที่สมบูรณ์แบบที่สุดที่ใช้อธิบาย “ดุลยภาพ (Trade-off)” ระหว่าง ความพยายามที่จะหาวัตถุให้เจอให้หมด (Recall) และ ความแม่นยำในการไม่ทายมั่ว (Precision) ในสภาพแวดล้อมที่เต็มไปด้วยพื้นหลัง (Background Clutter) ของงาน Object Detection
การทำความเข้าใจ mAP และ IoU ทำให้เราสามารถเปรียบเทียบสถาปัตยกรรมระดับเทพอย่าง R-CNN, SSD หรือ YOLO ได้อย่างเป็นรูปธรรมครับ
ถึงตอนนี้ เราเข้าใจกลไกทุกอย่างของ Object Detection ทั้งหมดแล้ว! ในบทความซีรีส์ต่อไป พี่จะพาน้องๆ ไปเจาะลึกสถาปัตยกรรมระดับตำนานทีละตัว เริ่มตั้งแต่ต้นตระกูลที่เปิดประตูยุคสมัยใหม่อย่าง R-CNN Family (R-CNN, Fast R-CNN, Faster R-CNN) มาดูกันว่าวิวัฒนาการของมันเปลี่ยนแปลงโลกคอมพิวเตอร์วิทัศน์ไปได้อย่างไร รอติดตามความสนุกได้เลยครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p