ศาสตร์แห่งการตีกรอบ! เจาะลึก Bounding Boxes หัวใจของการชี้เป้าใน Object Detection

1. 🎯 ศาสตร์แห่งการตีกรอบ! เจาะลึก Bounding Boxes
สวัสดีครับน้องๆ วิศวกรและนักล่าฝันสาย Vision ทุกท่าน! ชงกาแฟแก้วโปรดแล้วมาลุยกันต่อครับ ตลอดหลายตอนที่ผ่านมา เราพูดถึงคำว่า Object Detection กันมาเยอะมาก ซึ่งเราสรุปกันไปแล้วว่ามันคือการเอาความสามารถของ Image Classification (ทายว่าคืออะไร) มารวมกับ Object Localization (หาว่ามันอยู่ตรงไหน)
แต่คำถามที่น่าสนใจและเป็นจุดตายของวิศวกรมือใหม่คือ… “แล้ว AI มันบอกตำแหน่งเราด้วยภาษาอะไรล่ะ?” ในบริบทที่กว้างขึ้นของงาน Object Detection แหล่งข้อมูลระดับโลกชี้ให้เห็นว่า สื่อกลางที่ AI ใช้คุยกับมนุษย์เพื่อ “ชี้เป้า” ก็คือกล่องสี่เหลี่ยมมหัศจรรย์ที่เราเรียกกันว่า Bounding Box ครับ วันนี้พี่จะพาน้องๆ ไปเจาะลึกคณิตศาสตร์และกลไกเบื้องหลังกล่องสี่เหลี่ยมเหล่านี้ ว่ามันทำงานอย่างไรในโครงข่ายประสาทเทียมครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องกำลังพัฒนาระบบ AI ให้กับโดรนกู้ภัย (Search and Rescue) ที่ต้องบินค้นหาผู้รอดชีวิตในป่า ถ้าน้องใช้แค่โมเดล Image Classification มันก็จะตะโกนบอกแค่ว่า “ลูกพี่! ผมเห็นคนในรูปนี้!” แต่ประเด็นคือรูปถ่ายทางอากาศมันกว้างตั้งกี่ร้อยไร่! โดรนไม่ยอมบอกว่าคนอยู่มุมไหนของรูป แล้วเราจะส่งทีมเดินเท้าไปช่วยถูกได้อย่างไรล่ะครับ?
เพื่อแก้ปัญหานี้ วิศวกรจึงต้องสอนให้ AI รู้จักการ “วาดกรอบ” ล้อมรอบผู้รอดชีวิต ซึ่งการวาดกรอบสี่เหลี่ยมนี้เองคือสิ่งที่เรียกว่า Bounding Box มันเปลี่ยนสถานะของ AI จากแค่คนดูรูปธรรมดา ให้กลายเป็น “นักสไนเปอร์” ที่สามารถบอกพิกัด X, Y บนหน้าจอได้อย่างแม่นยำระดับพิกเซล!
3. 🧠 แก่นวิชา (Core Concepts)
ในโลกของ Object Detection การทำงานกับ Bounding Box มีความน่าสนใจซ่อนอยู่หลายมิติครับ แหล่งข้อมูลได้อธิบายแนวคิดหลักๆ ไว้ดังนี้:
- 1. ภาษากล่องสี่เหลี่ยม (The Parameters): AI ไม่ได้ระบายสีกล่องให้เราดูโดยตรงนะครับ แต่มันถูกสอนให้ทำนาย (Predict) เป็นตัวเลข 4 ตัว ซึ่งโดยทั่วไปจะอยู่ในรูปแบบ $x, y, w, h$ โดยที่ $x$ และ $y$ คือพิกัดจุดกึ่งกลาง (Center point) ของกล่อง (หรือบางค่ายก็ใช้จุดมุมบนซ้าย) ส่วน $w$ และ $h$ คือความกว้างและความสูงของกล่องสี่เหลี่ยมนั้นครับ
- 2. Localization คือปัญหา Regression: ด้วยความที่ผลลัพธ์ของ Bounding Box คือ “ตัวเลขค่าต่อเนื่อง (Continuous values)” การสอนให้ AI ตีกรอบจึงถือเป็นปัญหาการวิเคราะห์ถดถอย (Regression Problem) แตกต่างจากการทายคลาส (Classification) ที่เป็นเรื่องของความน่าจะเป็นครับ
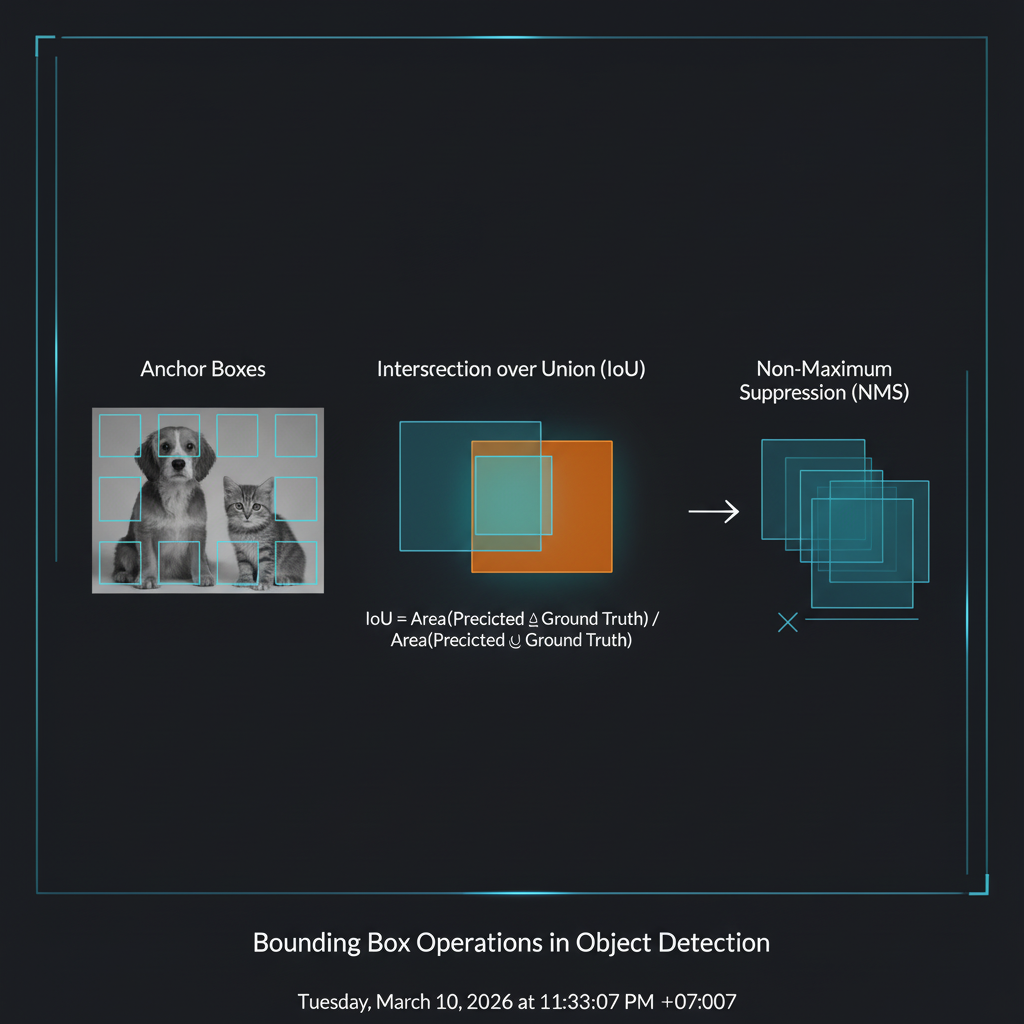
- 3. Anchor Boxes (กล่องสมมติช่วยเดา): ถ้าน้องให้ AI เดาพิกัดสี่เหลี่ยมจากหน้าจอเปล่าๆ มันจะเดายากมากและเรียนรู้ช้าครับ! สถาปัตยกรรมระดับเทพอย่าง Faster R-CNN, SSD หรือ YOLO จึงใช้เทคนิคสร้าง Anchor Boxes (หรือ Default Boxes) ซึ่งเป็นการนำกล่องสี่เหลี่ยมหลายๆ ขนาดและหลายอัตราส่วน (Aspect ratios) เช่น 1:1, 1:2, 2:1 ไปตีตารางวางทาบไว้ทั่วทั้งรูปภาพล่วงหน้า จากนั้นหน้าที่ของ AI จะไม่ใช่การเดากล่องใหม่จากศูนย์ แต่เป็นการคำนวณ “ค่าความคลาดเคลื่อน (Offsets / Deltas)” เช่น $\Delta x, \Delta y, \Delta w, \Delta h$ เพื่อปรับขนาดและขยับกล่อง Anchor เหล่านั้นให้ครอบวัตถุเป้าหมายได้พอดีเป๊ะครับ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในการเตรียมข้อมูลสำหรับสอน AI ทำ Object Detection น้องๆ จะต้องเจอกับไฟล์ Annotation (เช่น ไฟล์ XML สไตล์ PASCAL VOC) ที่เก็บพิกัดของ Ground Truth Bounding Box เอาไว้ พี่มีตัวอย่างโค้ด Python ในการดึงค่าพิกัดเหล่านี้ออกมาสร้างเป็น Dataset ครับ:
import xml.etree.ElementTree as ET
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def extract_boxes(filename):
"""ฟังก์ชันอ่านไฟล์ XML เพื่อดึงพิกัด Bounding Box ออกมา"""
# 📌 โหลดและพาร์สไฟล์ XML
tree = ET.parse(filename)
root = tree.getroot()
boxes = []
# 📌 วนลูปหา tag <bndbox> ทุกอันในไฟล์
for box in root.findall('.//bndbox'):
# ดึงพิกัดมุมซ้ายบน และมุมขวาล่าง
xmin = int(box.find('xmin').text)
ymin = int(box.find('ymin').text)
xmax = int(box.find('xmax').text)
ymax = int(box.find('ymax').text)
# เก็บลง List ในรูปแบบพิกัด 4 มุม
boxes.append([xmin, ymin, xmax, ymax])
# 📌 ดึงขนาดภาพรวม (กว้าง, ยาว) มาด้วยเพื่อเอาไว้ทำ Normalization
width = int(root.find('.//size/width').text)
height = int(root.find('.//size/height').text)
return boxes, width, height
# สมมติเราดึงข้อมูลมาแล้ว จะวาดกล่องทดสอบดู
# rect = patches.Rectangle((xmin, ymin), xmax-xmin, ymax-ymin, linewidth=2, edgecolor='r', facecolor='none')
# plt.gca().add_patch(rect)คอมเมนต์: โค้ดนี้คือด่านแรกสุดของวิศวกร AI สาย Vision เลยครับ สังเกตว่าพิกัดในไฟล์ XML มักจะเก็บเป็น xmin, ymin, xmax, ymax (มุมซ้ายบน กับ มุมขวาล่าง) เวลาน้องจะเอาไปป้อนเข้าโมเดลอย่าง YOLO น้องต้องเขียนสมการแปลงมันให้กลับกลายเป็น x_center, y_center, w, h ก่อนเสมอนะครับ!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
เวลาที่เราได้พิกัดมาแล้ว เราจะรู้ได้อย่างไรว่า AI มันตีกรอบได้ “แม่น” แค่ไหน? พี่มีวิชาลับและตัวชี้วัดจากหน้างานจริงมาฝากครับ:
- ไม้บรรทัดแห่งวงการ IoU (Intersection over Union): เพื่อวัดความแม่นยำของ Bounding Box เราไม่ได้ดูค่า Loss ธรรมดาครับ แต่เราใช้ IoU (หรือ Jaccard Index) มันคือการเอา “พื้นที่ที่กล่อง AI ทายซ้อนทับกับกล่องเฉลย (Ground Truth)” หารด้วย “พื้นที่รวมของทั้งสองกล่อง” สมการคือ: $$ IoU = \frac{Area_of_Overlap}{Area_of_Union} $$ ค่านี้จะอยู่ระหว่าง 0 ถึง 1 ยิ่งใกล้ 1 แปลว่ากล่องซ้อนทับกันสนิท (แม่นมาก!) โดยทั่วไปถ้า IoU > 0.5 เราจะถือว่า AI “จับภาพเจอแล้ว (True Positive)” ครับ
- เวทมนตร์ปราบกล่องซ้ำซ้อน NMS (Non-Maximum Suppression): เมื่อน้องรันโมเดล Object Detection ครั้งแรก (เช่น โมเดล YOLO หรือ SSD) สิ่งที่จะเกิดขึ้นคือ AI มันจะพ่นกรอบสี่เหลี่ยมออกมาซ้อนทับกันยุ่บยั่บเต็มไปหมดครับ! (เพราะมันเห็นจุดเด่นหลายจุดในวัตถุชิ้นเดียว) วิศวกรจึงต้องใส่ฟิลเตอร์ NMS เข้าไปเพื่อจัดระเบียบ โดยมันจะ 1. เลือกกล่องที่ AI มั่นใจที่สุด (Confidence score สูงสุด) มาเป็นตัวหลัก 2. ลบกล่องอื่นที่ทายคลาสเดียวกันและมีค่า IoU ซ้อนทับกับกล่องหลักเกินกว่าเกณฑ์ (Threshold) ทิ้งไป ทำให้ท้ายที่สุดเหลือ Bounding Box แค่กล่องเดียวต่อวัตถุ 1 ชิ้นครับ!
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Bounding Box คือตัวกลางสำคัญที่ทำให้เทคโนโลยี Object Detection สมบูรณ์แบบ มันแปลงปัญหาการหาตำแหน่งที่ยุ่งยากให้กลายเป็นการทาย “ค่าตัวเลขพิกัด (Regression)” เพียง 4 ค่า และด้วยการเข้ามาช่วยเหลือของ Anchor Boxes และฟิลเตอร์อย่าง NMS ก็ทำให้ AI ในปัจจุบันสามารถตีกรอบล้อมรอบวัตถุบนวิดีโอแบบ Real-time ได้อย่างงดงาม
แต่ทว่า… กล่องสี่เหลี่ยมมันก็ยังเป็นแค่ “กล่องทื่อๆ” ใช่ไหมครับ? ในหน้างานอุตสาหกรรมบางอย่าง เช่น รถยนต์ไร้คนขับที่ต้องรู้ระยะหอบของถนน หรือการแพทย์ที่ต้องดูขนาดเนื้องอก การตีแค่กล่องสี่เหลี่ยมมันหยาบเกินไป! ในบทความตอนต่อไป พี่จะพาน้องๆ ทะลวงขีดจำกัดนี้ ไปทำความรู้จักกับเทคนิคการ “ระบายสี” แยกวัตถุแบบพิกเซลต่อพิกเซล ที่เราเรียกว่า Semantic Segmentation และ Instance Segmentation กันครับ รอติดตามความล้ำนี้ได้เลย!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p