ชี้เป้าให้แม่นยำ! เจาะลึก Localization จิ๊กซอว์ชิ้นสำคัญในโลกของ Object Detection

1. 🎯 ตอนที่ 42: ชี้เป้าให้แม่นยำ! เจาะลึก Localization จิ๊กซอว์ชิ้นสำคัญ
สวัสดีครับน้องๆ วิศวกรสาย Vision และนักพัฒนา AI ทุกท่าน! จิบกาแฟอุ่นๆ แล้วมาล้อมวงกันครับ ตลอดซีรีส์ที่ผ่านมา เราได้สอน AI ให้รู้จักโลกผ่านการแยกแยะรูปภาพ (Image Classification) กันไปแล้ว แต่วันนี้เราจะมาเจาะลึกอีกมิติหนึ่งที่ท้าทายกว่ามากครับ
น้องๆ เคยสับสนไหมครับเวลาได้ยินคำว่า Image Classification, Object Localization, และ Object Detection? ในบริบทที่กว้างขึ้นของวงการคอมพิวเตอร์วิทัศน์ งานเหล่านี้เกี่ยวข้องกันอย่างแนบแน่นครับ แหล่งข้อมูลระดับโลกชี้ให้เห็นว่า การที่เราจะสร้างระบบ Object Detection ที่สมบูรณ์แบบได้นั้น มันเกิดจากการผสมผสานกันระหว่างการบอกว่า “นี่คืออะไร (Classification)” และการชี้เป้าว่า “มันอยู่ตรงไหน (Localization)”
วันนี้พี่จะพาน้องๆ ไปแกะกล่องดำของกระบวนการ Localization ว่าระบบ AI มันเรียนรู้ที่จะ “ตีกรอบ” วัตถุในภาพได้อย่างไร และคณิตศาสตร์อะไรที่อยู่เบื้องหลังการชี้เป้านี้ ลุยกันเลยครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องกำลังพัฒนาระบบหุ่นยนต์คัดแยกแอปเปิลเสียในสายพานการผลิต ถ้าน้องใช้แค่โมเดล Image Classification ธรรมดา พอกล้องถ่ายภาพแอปเปิลมา 1 ลัง AI จะตะโกนบอกน้องแค่ว่า “ลูกพี่! ในรูปนี้มีแอปเปิลเน่า!” …แต่มันไม่ยอมบอกว่าอยู่ตรงไหน! หุ่นยนต์แขนกลของน้องก็งงสิครับ จะหยิบลูกไหนออกไปทิ้งล่ะทีนี้?
นี่คือปัญหาเจ็บปวด (Pain Point) ที่วิศวกรต้องเจอครับ การรู้แค่ว่ามีวัตถุอยู่ (Classification) นั้นไม่เพียงพอสำหรับหน้างานจริง เราต้องการให้ AI “ชี้เป้า (Localize)” ด้วยการวาดกรอบสี่เหลี่ยม (Bounding Box) ล้อมรอบแอปเปิลลูกที่เน่าเอาไว้ เพื่อให้แขนกลส่งพิกัดไปหยิบได้อย่างแม่นยำ กระบวนการนี้แหละครับที่เป็นรากฐานสำคัญ นำไปสู่สถาปัตยกรรมระดับเทพอย่าง R-CNN หรือ YOLO ที่เราใช้กันในปัจจุบัน
3. 🧠 แก่นวิชา (Core Concepts)
แหล่งข้อมูลได้อธิบายความแตกต่างและกลไกการทำงานของ Localization ในบริบทของ Object Detection ไว้ดังนี้ครับ:
- 1. ความสัมพันธ์ของ 3 พี่น้อง (The Trinity of Recognition):
คำว่า Object Recognition เป็นคำกว้างๆ ที่ครอบคลุม 3 งานหลัก ได้แก่
- Image Classification: ทายว่าภาพทั้งภาพคืออะไร (มีป้ายกำกับเดียว)
- Object Localization: ชี้เป้าตำแหน่งวัตถุในภาพ มักจะทำกับ “วัตถุหลักชิ้นเดียว (Single-object)” ในภาพ โดยวาดกรอบ Bounding Box ขึ้นมา
- Object Detection: ร่างขั้นสุดยอด! คือการหาวัตถุ “หลายๆ ชิ้น (Variable number of objects)” พร้อมๆ กัน วาดกรอบให้ทุกชิ้น และทายชื่อให้ถูกทุกชิ้นด้วย
- 2. Localization คือปัญหาการวิเคราะห์ถดถอย (Regression Problem): AI วาดกรอบสี่เหลี่ยมได้อย่างไร? คำตอบคือ เราไม่ได้สอนให้มันระบายสีครับ แต่เราสอนให้มัน “ทำนายตัวเลข 4 ตัว” ต่างหาก! ซึ่งตัวเลขเหล่านี้คือพิกัดของ Bounding Box มักอยู่ในรูปแบบ (x, y, w, h) โดยที่ $x$ และ $y$ คือจุดกึ่งกลางของกล่อง ส่วน $w$ และ $h$ คือความกว้างและความสูง ด้วยเหตุนี้ การทำ Localization จึงถูกปฏิบัติเหมือนเป็นปัญหา Regression ล้วนๆ ครับ
- 3. เทคนิคในการหาพิกัด (Localization Strategies):
- Sliding Window: ยุคแรกเริ่ม วิศวกรจะเอากรอบสี่เหลี่ยมเลื่อนกวาดไปทั่วภาพ (Slide) แล้วครอปภาพย่อยนั้นส่งให้ CNN ทายว่ามีของหรือไม่ (วิธีนี้คำนวณหนักและช้ามาก)
- Region Proposals: ยุคต่อมาอย่าง R-CNN ใช้กลไกอย่าง Selective Search เพื่อเดาว่าบริเวณไหน “น่าจะ” มีวัตถุ (สร้างกรอบจำลองมาสัก 2,000 กรอบ) แล้วค่อยเอาไปจัดคลาส และปรับแต่งพิกัดกล่องให้เป๊ะขึ้นด้วย Bounding Box Regressor
- Single-Stage Detectors (YOLO, SSD): โมเดลสายซิ่งยุคใหม่ แบ่งภาพเป็นตาราง (Grid) แล้วให้แต่ละช่องทำนายทั้งคลาสและตัวเลข 4 ตัวของ Bounding Box ออกมาพร้อมๆ กันในการมองภาพเพียงครั้งเดียว!
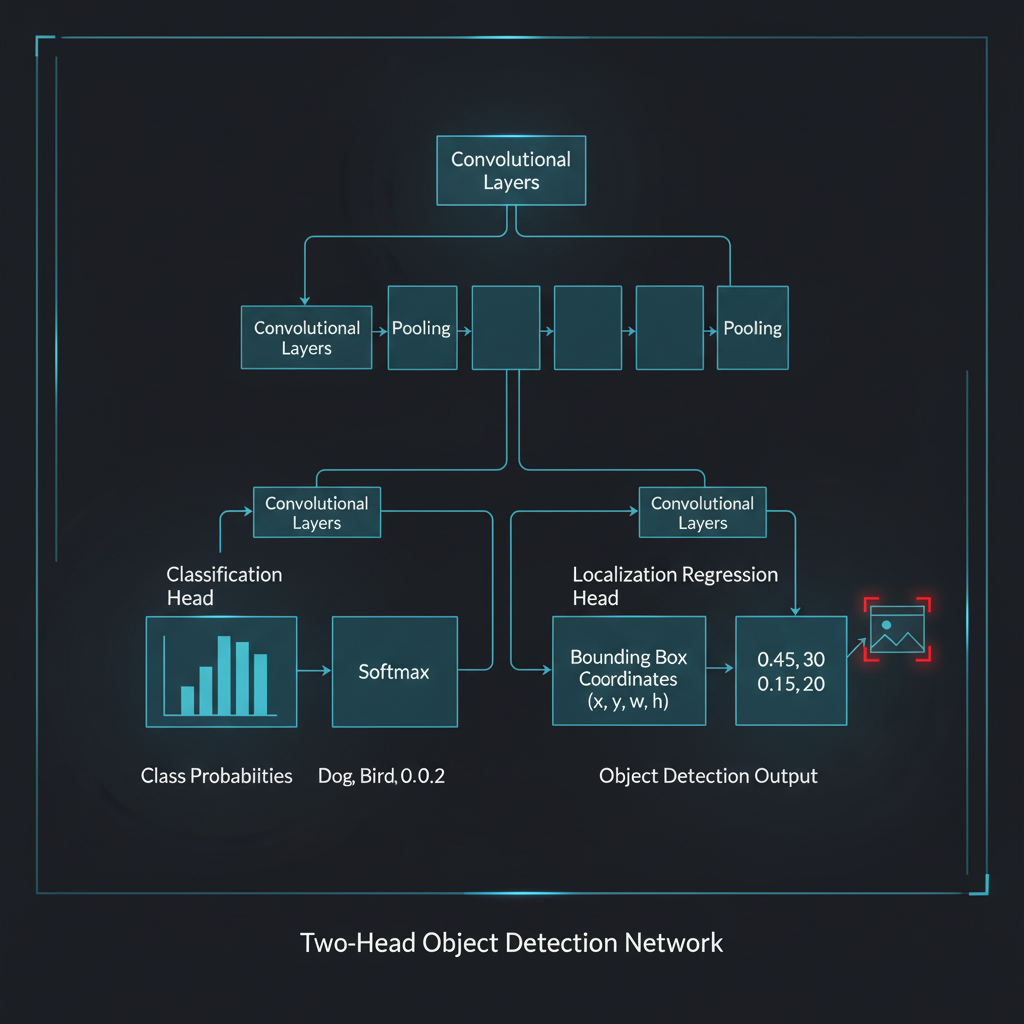
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ถ้าน้องอยากสร้างโมเดลที่มีทั้งการทำ Classification และ Localization พร้อมกัน (Single-object localization) น้องสามารถสร้างเครือข่ายที่มี “2 หัว (Two-headed Model)” ได้ง่ายๆ ด้วย Keras Functional API ครับ ลองดูคอนเซปต์นี้:
import tensorflow as tf
from tensorflow.keras import layers, models
# -------------------------------------------------------------
# 📌 1. สร้าง Backbone สำหรับสกัดฟีเจอร์ (Feature Extractor)
# เช่น ใช้ Pre-trained โมเดล หรือสร้าง CNN ธรรมดา
# -------------------------------------------------------------
inputs = layers.Input(shape=(224, 224, 3))
x = layers.Conv2D(32, (3, 3), activation='relu')(inputs)
x = layers.MaxPooling2D(2, 2)(x)
# ... ซ้อนชั้น Conv2D ลงไปเรื่อยๆ ...
x = layers.GlobalAveragePooling2D()(x) # สกัดออกมาเป็น Vector
# -------------------------------------------------------------
# 📌 2. หัวที่ 1: สำหรับทำ Image Classification (ทายคลาส)
# ใช้ Softmax และ Cross-Entropy Loss
# -------------------------------------------------------------
class_head = layers.Dense(128, activation='relu')(x)
class_output = layers.Dense(10, activation='softmax', name='class_output')(class_head)
# -------------------------------------------------------------
# 📌 3. หัวที่ 2: สำหรับทำ Object Localization (ทายพิกัดกล่อง)
# ใช้ Linear Activation (เพราะทำนายตัวเลข 4 ตัว: x, y, w, h)
# -------------------------------------------------------------
box_head = layers.Dense(128, activation='relu')(x)
# ออกเป็น 4 นิวรอนสำหรับ 4 พิกัด
box_output = layers.Dense(4, activation='linear', name='box_output')(box_head)
# ประกอบร่างโมเดล
model = models.Model(inputs=inputs, outputs=[class_output, box_output])
# -------------------------------------------------------------
# 📌 4. คอมไพล์โมเดลด้วย 2 Loss Functions!
# หัวคลาสใช้ Cross-entropy ส่วนหัวกล่องพิกัดใช้ MSE (Mean Squared Error)
# -------------------------------------------------------------
model.compile(optimizer='adam',
loss={'class_output': 'categorical_crossentropy',
'box_output': 'mse'}, # ตำราแนะนำว่าให้ใช้ Regression Loss
metrics={'class_output': 'accuracy'})คอมเมนต์: เห็นไหมครับว่าการทำ Localization ก็แค่เพิ่มชั้น Dense(4) เข้าไป แล้วให้โมเดลฝึกการกะระยะ (Regression) โดยมี “พิกัดที่คนวาดไว้เป็นเฉลย (Ground-truth)” คอยสอนมันผ่าน Loss Function อย่าง MSE ครับ
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในการทำพิกัด Bounding Box ให้แม่นยำในระดับใช้งานจริง พี่มีเคล็ดวิชามาเตือนก่อนลงสนามครับ:
- หนีจาก MSE ไปซบ Smooth L1 (Huber Loss): แม้โค้ดด้านบนพี่จะเขียนว่าใช้ MSE (L2 Loss) ตามพื้นฐานการทำ Regression แต่แหล่งข้อมูลชี้ว่าในงาน Localization จริงๆ การใช้ L2 Loss จะพังง่ายมากถ้าเจอค่า Outlier (เช่น ตอนแรกโมเดลยังเดากล่องมั่วๆ ค่า Error จะสูงปรี๊ดจน Gradient ระเบิด) วิศวกรจึงนิยมเปลี่ยนไปใช้ L1 Loss (Mean Absolute Error) หรือที่เจ๋งที่สุดคือ Smooth L1 Loss ที่จะค่อยๆ ลดความชันลงเมื่อค่า Error เข้าใกล้ศูนย์ ทำให้กล่องค่อยๆ ขยับเข้าเป้าอย่างนุ่มนวลครับ!
- การประเมินผลด้วยไม้บรรทัด IoU: เราจะรู้ได้อย่างไรว่ากล่องพิกัด 4 ตัวที่โมเดลทาย (Predicted box) มัน “แม่น” พอหรือยัง? เราใช้วิธีทางคณิตศาสตร์ที่เรียกว่า Intersection over Union (IoU) ครับ มันคือการเอา “พื้นที่ทับซ้อน (Intersection)” มาหารด้วย “พื้นที่รวมทั้งหมด (Union)” ระหว่างกล่องที่ทายกับกล่องเฉลย ถ้า IoU > 0.5 โดยทั่วไปในงานแข่งคลาสสิกเราจะถือว่า “ตรวจเจอแล้ว (True Positive)” ครับ
- Anchor Boxes คือตัวช่วยชั้นดี:
ถ้าน้องให้โมเดลเดาพิกัด
(x, y, w, h)จากความว่างเปล่า มันจะเรียนรู้ยากมากครับ (เหมือนให้คนหลับตาเดาขนาดรถ) โมเดล Object Detection ระดับเทพอย่าง Faster R-CNN หรือ YOLO จึงใช้ Anchor Boxes (หรือ Default Boxes) ซึ่งเป็นกล่องขนาดต่างๆ (แนวตั้ง, แนวนอน, จัตุรัส) ที่ตีตารางทิ้งไว้ล่วงหน้า แล้วสอนให้โมเดลทำหน้าที่แค่ “ปรับแก้ (Offset/Refine)” ความกว้างยาวจากกล่อง Anchor เหล่านั้นแทน ทำให้โมเดลลู่เข้า (Converge) ได้เร็วและแม่นยำขึ้นมหาศาลครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Localization ไม่ใช่แค่การวาดกรอบสี่เหลี่ยมเท่ๆ แต่มันคือการเปลี่ยนกระบวนทัศน์ทางคณิตศาสตร์ให้ AI สามารถทำนาย “พิกัดเชิงพื้นที่ (Spatial Coordinates)” ผ่านกระบวนการของ Regression ได้
การผสานพลังระหว่าง Classification (ทายคลาส) และ Localization (ทายพิกัด) คือสิ่งที่ก่อกำเนิดเป็น Object Detection ที่ทรงพลัง ที่สามารถจับผิดชิ้นงานเสียบนสายพาน หรือบอกตำแหน่งรถรอบข้างในระบบขับขี่อัตโนมัติได้อย่างที่มนุษย์ต้องการครับ
ในบทความตอนถัดไป เราจะนำความรู้นี้ไปสวมทับลงในสถาปัตยกรรมตัวท็อปอย่าง YOLO (You Only Look Once) ดูกันว่าเขาจัดวางตารางพิกัดพวกนี้อย่างไร ถึงทำให้โมเดลทำงานได้รวดเร็วระดับ Real-time แบบที่รุ่นพี่อย่าง R-CNN ทำไม่ได้! รอติดตามกันให้ดีนะครับ
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p