เปิดตำนาน ImageNet: ลานประลองโอลิมปิกที่พลิกโฉมหน้า AI และ Image Classification

1. 🎯 ตอนที่ 41: เปิดตำนาน ImageNet ลานประลองโอลิมปิกที่พลิกโฉมหน้า AI
สวัสดีครับน้องๆ วิศวกรสาย Vision และผู้ที่หลงใหลใน AI ทุกท่าน! ชงกาแฟแก้วโปรดแล้วมานั่งล้อมวงกันตรงนี้ครับ ตลอดหลายตอนที่ผ่านมา เราได้ฝึกฝนวิชาทายภาพจากชุดข้อมูลระดับอนุบาล (MNIST) และระดับมัธยม (CIFAR-10) กันไปแล้ว
แต่ในโลกความเป็นจริง หากเราต้องการสร้าง AI ที่ “มองเห็นและเข้าใจโลก” ได้ใกล้เคียงกับมนุษย์ การให้มันดูรูปภาพแค่หลักหมื่นรูปที่มีความละเอียดต่ำนั้นไม่เพียงพอครับ! ในบริบทที่กว้างขึ้นของวงการ Image Classification (การจำแนกประเภทภาพ) แหล่งข้อมูลระดับโลกชี้ให้เห็นตรงกันว่า จุดเปลี่ยนที่แท้จริง (Turning Point) ที่ทำให้ปัญญาประดิษฐ์บูมขึ้นมาจนถึงทุกวันนี้ เกิดจากอภิมหาชุดข้อมูลและลานประลองที่ชื่อว่า ImageNet ครับ!
วันนี้พี่จะพาน้องๆ ไปเจาะลึกว่า ImageNet คืออะไร ทำไมมันถึงกลายเป็น “มาตรฐานทองคำ (Gold Standard)” ของวงการ และมันได้ให้กำเนิดสถาปัตยกรรมระดับตำนานอะไรขึ้นมาบ้าง ลุยกันเลยครับ!
2. 📖 เปิดฉาก (The Hook)
ย้อนกลับไปในยุคก่อนปี 2012 วงการ Computer Vision ค่อนข้างจะตื้อตันครับ ในสมัยนั้นวิศวกรต้องมานั่งคิดค้นอัลกอริทึมสกัดจุดเด่น (Hand-crafted Features) ด้วยตัวเอง ชุดข้อมูลที่ใช้ทดสอบความเก่งของ AI ในยุคนั้นอย่าง PASCAL VOC มีรูปภาพที่ถูกคัดแยกไว้เพียงหลักหมื่นรูป และมีหมวดหมู่ให้ทายแค่ 20 หมวดหมู่ (20 Classes) เท่านั้น ซึ่งมันน้อยเกินไปที่จะสอนให้โครงข่ายประสาทเทียมระดับลึก (Deep Neural Networks) เรียนรู้ความซับซ้อนของโลกได้
ลองนึกภาพว่าน้องกำลังสอนเด็กคนหนึ่งให้รู้จักโลก ถ้าน้องให้เขาดูรูปสัตว์แค่ 20 ชนิด ชนิดละไม่กี่สิบรูป เด็กคนนั้นก็คงแยกหมากับแมวออก แต่ถ้าไปเจอ “สุนัขจิ้งจอก” หรือ “หมาป่าดิงโก้” เขาคงจะงงเป็นไก่ตาแตกแน่ๆ
นักวิจัยจากมหาวิทยาลัย Stanford และ Princeton จึงเกิดไอเดียบ้าบิ่นว่า “ถ้าข้อมูลมันน้อยไป งั้นเราก็สร้างฐานข้อมูลภาพที่ใหญ่ที่สุดในประวัติศาสตร์มนุษยชาติขึ้นมาเลยสิ!” และนั่นคือจุดเริ่มต้นของการระดมพลคนทั่วโลกผ่าน Amazon’s Mechanical Turk เพื่อมาช่วยกันนั่งแปะป้ายชื่อรูปภาพกว่า 14 ล้านรูป และก่อให้เกิดการแข่งขัน ILSVRC ที่ดึงดูดวิศวกรหัวกะทิจากทั่วโลกมาห้ำหั่นกันครับ!
3. 🧠 แก่นวิชา (Core Concepts)
แหล่งข้อมูลระดับโลกได้ให้ความหมายและบริบทความสำคัญของ ImageNet ต่อวงการ Image Classification ไว้ดังนี้ครับ:
- 1. ฐานข้อมูลที่จัดระเบียบโลก (The ImageNet Dataset): ImageNet ไม่ใช่แค่โฟลเดอร์เก็บรูปภาพธรรมดานะครับ แต่มันเป็นโปรเจกต์ขนาดยักษ์ที่จัดระเบียบตามพจนานุกรมคำศัพท์ WordNet โดยแต่ละคำศัพท์หรือหมวดหมู่ (Synonym set หรือ Synset) จะมีรูปภาพประกอบมากกว่า 1,000 รูป ปัจจุบันมีภาพรวมกว่า 14-15 ล้านภาพ และแบ่งเป็นหมวดหมู่ย่อยถึง 22,000 หมวดหมู่ (เช่น ไม่ใช่แค่บอกว่าเป็น “หมา” แต่แยกย่อยไปถึงสายพันธุ์ “ไซบีเรียน ฮัสกี้” หรือ “ปั๊ก”)
- 2. ลานประลอง ILSVRC (ImageNet Large Scale Visual Recognition Challenge): เพื่อให้เกิดการแข่งขันนำไปสู่การพัฒนา จึงเกิดการจัดแข่ง ILSVRC ขึ้นทุกปี โดยคัดเลือกรูปภาพประมาณ 1.2 ล้านภาพ และหมวดหมู่ 1,000 คลาส มาเป็นข้อสอบให้ AI ทาย งานนี้แหละครับที่เป็นเป้าหมายหลักที่ทุกคนพูดถึงเมื่อกล่าวคำว่า “ImageNet”
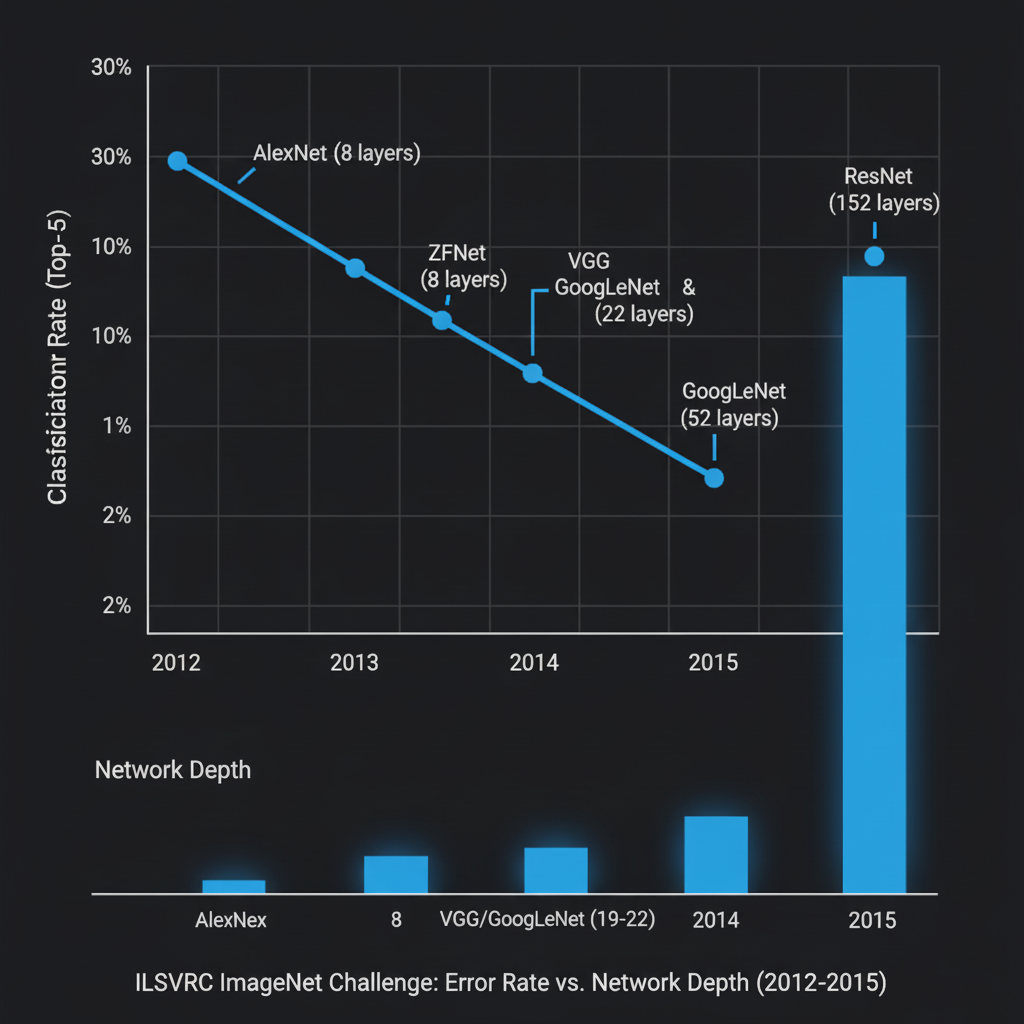
- 3. The Big Bang of Deep Learning (การระเบิดครั้งใหญ่ของ AI): ในปี 2012 อัลกอริทึมคลาสสิกเริ่มไปต่อไม่ไหว ทำความแม่นยำได้ดีที่สุดแค่วราวๆ 75% จนกระทั่งทีมของ Alex Krizhevsky ได้ส่งโมเดล AlexNet ซึ่งเป็น Convolutional Neural Network (CNN) เข้าแข่งขัน และสามารถทำลายสถิติด้วยการเป็นระบบแรกที่ทำความแม่นยำทะลุ 80% ได้สำเร็จ (Error rate ลดลงเหลือ 15.4%) ซึ่งทิ้งห่างที่ 2 แบบไม่เห็นฝุ่น! เหตุการณ์นี้ได้จุดประกายให้คนทั้งโลกหันมาสนใจ Deep Learning อย่างบ้าคลั่ง
- 4. กำเนิดสถาปัตยกรรมระดับตำนาน (Milestone Architectures):
หลังจาก AlexNet ลานประลอง ILSVRC ก็กลายเป็นเวทีแจ้งเกิดของโมเดลที่เราใช้กันอยู่ทุกวันนี้ครับ:
- ปี 2013 (ZFNet): ปรับจูน AlexNet ให้ลึกขึ้นและเข้าใจ Feature Maps ได้ดีขึ้น
- ปี 2014 (VGGNet และ GoogLeNet/Inception): VGG โชว์ความเรียบง่ายด้วยการซ้อนชั้น Conv ขนาด 3x3 ลึก 19 ชั้น ในขณะที่ GoogLeNet เปิดตัว Inception Module ที่สกัดฟีเจอร์หลายๆ ขนาดพร้อมกันแบบคู่ขนาน (ลึก 22 ชั้น)
- ปี 2015 (ResNet): Kaiming He เสนอการทำ “ทางลัด (Skip connections หรือ Residual blocks)” ทำให้สร้างโมเดลที่ลึกทะลุ 152 ชั้นได้สำเร็จโดยไม่เจอปัญหา Gradient จางหาย (Vanishing Gradient) และเอาชนะความแม่นยำระดับมนุษย์ได้!
เมื่อผ่านชั้น Convolutional Layers นับร้อยชั้น ในชั้นสุดท้ายของโมเดลเหล่านี้มักจะใช้ฟังก์ชัน Softmax เพื่อแปลงผลลัพธ์ดิบ (Logits) ให้กลายเป็น “ความน่าจะเป็น (Probability)” ของทั้ง 1,000 คลาสครับ:
$$ P(y=j | x) = \frac{e^{z_j}}{\sum_{k=1}^{1000} e^{z_k}} $$
(เมื่อ $z_j$ คือค่าคะแนนดิบของคลาสเป้าหมาย และตัวหารคือผลรวมคะแนนของทั้ง 1,000 คลาส ทำให้ผลรวมความน่าจะเป็นทั้งหมดเท่ากับ 1.0 เสมอ)
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ด้วยความยิ่งใหญ่ของมัน ปัจจุบันน้องๆ ไม่จำเป็นต้องไปดาวน์โหลดภาพ 1.2 ล้านรูปมาเทรนโมเดลเองให้เปลืองค่าไฟแล้วครับ! ในไลบรารีอย่าง Keras และ TensorFlow วิศวกรใจดีได้เตรียม “โมเดลที่พรีเทรนแล้ว (Pre-trained Models)” บนชุดข้อมูล ImageNet มาให้เราเรียกใช้ได้ในไม่กี่บรรทัดเลยครับ:
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
from tensorflow.keras.preprocessing import image
import numpy as np
# -------------------------------------------------------------
# 📌 1. โหลดโมเดล ResNet50 พร้อมน้ำหนัก (Weights) ที่เรียนรู้วิชาจาก ImageNet มาแล้ว
# -------------------------------------------------------------
model = ResNet50(weights='imagenet')
# -------------------------------------------------------------
# 📌 2. โหลดรูปภาพของเราและปรับขนาดให้เป็น 224x224 (ขนาดมาตรฐานที่ ResNet ชอบ)
# -------------------------------------------------------------
img_path = 'my_dog.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0) # เพิ่มมิติ Batch size เข้าไป
# ปรับสเกลสีพิกเซลให้ตรงกับรูปแบบที่ ResNet เคยเห็นตอนเทรน (สำคัญมาก!)
x = preprocess_input(x)
# -------------------------------------------------------------
# 📌 3. สั่งให้ AI ทายผล (Prediction)
# -------------------------------------------------------------
preds = model.predict(x)
# ใช้ decode_predictions เพื่อแปลผลความน่าจะเป็น 1,000 คลาส ออกมาเป็นข้อความภาษาอังกฤษ 3 อันดับแรก
print('ผลลัพธ์ที่ AI ทาย:', decode_predictions(preds, top=3))
# ผลลัพธ์อาจจะออกมาเป็น: [('n02099712', 'Labrador_retriever', 0.95), ...]คอมเมนต์: เห็นความมหัศจรรย์ไหมครับ? แค่ใส่พารามิเตอร์ weights='imagenet' เราก็จะได้สมองกลของ AI ที่เข้าใจว่าหน้าตาของ “ลาบราดอร์” หรือ “แก้วกาแฟ” บนโลกใบนี้เป็นอย่างไรมาใช้งานได้ทันที (Out-of-the-box) โดยไม่ต้องเทรนเองเลยสัก epoch เดียว!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในโลกของการทำงานจริง (Production) ImageNet ไม่ได้มีดีแค่เอาไว้แยกรูปหมายรูปแมวนะครับ พี่มี “ของจริง” จากหน้างานมาเล่าให้ฟัง:
- เวทมนตร์แห่ง Transfer Learning: เป้าหมายสูงสุดที่วิศวกรยุคใหม่ใช้ ImageNet คือการทำ Transfer Learning (การถ่ายโอนความรู้) ครับ! แหล่งข้อมูลอธิบายว่า เลเยอร์แรกๆ ของ CNN ที่เทรนบน ImageNet จะเรียนรู้การมองหาฟีเจอร์พื้นฐาน เช่น เส้นขอบ (Edges), มุม, หรือพื้นผิว (Textures) ซึ่ง “ความรู้พื้นฐาน” เหล่านี้สามารถเอาไปประยุกต์ใช้กับโจทย์ภาพอะไรก็ได้บนโลก! สมมติว่าน้องอยากทำ AI ตรวจจับ “รอยร้าวบนแผงวงจร (Defect)” น้องแค่โหลด Backbone ของ ResNet50 ตัดเลเยอร์สุดท้ายทิ้ง แล้วเทรนต่อด้วยรูปแผงวงจรของน้องแค่ไม่กี่ร้อยรูป โมเดลน้องก็จะเก่งกาจและลู่เข้า (Converge) ได้อย่างรวดเร็วเลยครับ!
- ระวังเรื่อง Distribution Shift: ถึงแม้ ImageNet จะครอบจักรวาล แต่มันก็ยังเป็น “ภาพถ่ายทั่วไป (Natural Images)” ที่คนถ่ายในชีวิตประจำวัน ถ้าน้องเอาโมเดลพรีเทรนไปใช้ตรงๆ กับภาพสแกนเอกสาร (Document OCR), ภาพถ่ายดาวเทียม (Satellite imagery), หรือภาพเอกซเรย์ทางการแพทย์ (Medical Imaging) โดยไม่ทำ Fine-tuning เลย ความแม่นยำจะลดลงฮวบฮาบครับ เพราะสถิติของการกระจายข้อมูล (Data Distribution) มันต่างกันเกินไป
- อคติในข้อมูล (Dataset Bias): เนื่องจากรูปส่วนใหญ่ถูกดึงมาจากอินเทอร์เน็ตฝั่งตะวันตก โมเดลจึงอาจเก่งในการทายรถยนต์หรือบ้านสไตล์อเมริกัน มากกว่าบ้านสไตล์ไทยหรือเอเชียครับ (เป็นเรื่องปกติของ Dataset ระดับโลกที่เราพึงระวังไว้ตอนทำระบบจริง)
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว ImageNet และการแข่งขัน ILSVRC คือหน้าประวัติศาสตร์ที่สำคัญที่สุดหน้าหนึ่งของวงการ Image Classification ครับ มันคือแรงผลักดันมหาศาลที่เปลี่ยนผ่านกระบวนทัศน์จากการสกัดฟีเจอร์ด้วยมือแบบดั้งเดิม สู่ยุคของ Deep Learning อย่างเต็มตัว
ไม่ว่าจะเป็นสถาปัตยกรรมอย่าง AlexNet, VGGNet, หรือ ResNet ที่เราใช้งานกันอยู่ทุกวัน ล้วนถือกำเนิดและถูกพิสูจน์ความแข็งแกร่งมาจากสนามประลองแห่งนี้ทั้งสิ้น และที่สำคัญ “ความรู้ (Weights)” ที่มันสกัดได้จากภาพ 14 ล้านภาพ ก็ได้กลายมาเป็นมรดกตกทอดผ่าน Transfer Learning ให้นักพัฒนาอย่างพวกเราเอามาต่อยอดกับงานของตัวเองได้อย่างไร้รอยต่อครับ
แต่เดี๋ยวก่อน! การทายว่า “ภาพนี้คืออะไร (Classification)” มันเพิ่งจะเป็นแค่จุดเริ่มต้นเท่านั้น… แล้วถ้าในรูปภาพมีทั้ง หมา, แมว, และรถยนต์ อยู่ในภาพเดียวกันล่ะ? AI จะรู้ได้อย่างไรว่าของแต่ละชิ้นอยู่ตรงพิกัดไหนของภาพ? เตรียมตัวให้พร้อมครับ เพราะในตอนต่อไป พี่จะพาน้องๆ ก้าวข้ามขีดจำกัดไปสู่โลกของ Object Detection (R-CNN, SSD, YOLO) กันแล้ว รอติดตามความมันส์ได้เลย!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p