MNIST Dataset: 'Hello World' แห่งวงการ Image Classification และแมลงหวี่ทดลองของ AI

1. 🎯 ตอนที่ 39: MNIST Dataset “Hello World” แห่งวงการ Image Classification
สวัสดีครับน้องๆ วิศวกรสาย Vision ทุกท่าน! กาแฟพร้อมแล้วใช่ไหมครับ วันนี้เราจะมาคุยกันเรื่องจุดเริ่มต้นของทุกสิ่ง
เวลาที่น้องๆ เริ่มเรียนเขียนโปรแกรม ไม่ว่าจะเป็นภาษา C, Python หรือ Java โค้ดบรรทัดแรกที่ทุกคนต้องเขียนคือ print("Hello, World!") ใช่ไหมครับ? ในโลกของ AI และคอมพิวเตอร์วิทัศน์ (Computer Vision) โดยเฉพาะในงาน Image Classification (การจำแนกประเภทภาพ) เราก็มีธรรมเนียมปฏิบัติแบบนั้นเหมือนกันครับ แต่มันมาในรูปแบบของชุดข้อมูลที่ชื่อว่า MNIST Dataset
แหล่งข้อมูลระดับโลกและปรมาจารย์ด้าน AI ต่างยกย่องให้ชุดข้อมูลนี้เป็น “จุดเริ่มต้น” ที่นักพัฒนาทุกคนต้องเคยผ่านมา วันนี้พี่จะพาไปเจาะลึกว่า ภายใต้ภาพตัวเลขยึกยือสีขาวดำพวกนี้ มันสอนอะไรให้กับวงการ Deep Learning และทำไมมันถึงเปรียบเสมือน “แมลงหวี่” ของนักวิจัย AI ครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการย้อนกลับไปในยุคที่ AI ยังไม่เก่งเท่าทุกวันนี้ การจะสอนให้คอมพิวเตอร์อ่าน “รหัสไปรษณีย์” จากซองจดหมายที่เขียนด้วยลายมือคนร้อยพ่อพันแม่ ถือเป็นปัญหาปราบเซียน (Pain Point) ระดับชาติเลยนะครับ เพราะลายมือคนเรามีความแปรปรวนสูงมาก บางคนเขียนเลข 1 เหมือนขีดเดียว บางคนเขียนเลข 7 แบบมีขีดตรงกลาง
สถาบันมาตรฐานและเทคโนโลยีแห่งชาติของสหรัฐฯ (NIST) จึงได้รวบรวมลายมือของพนักงานสำรวจสำมะโนประชากรและเด็กนักเรียนมัธยมปลายมาไว้ด้วยกัน จากนั้น คุณ Yann LeCun (บิดาแห่ง CNN) และทีมงานได้นำข้อมูลนี้มาปรับปรุง (Modified) ลดทอนความซับซ้อน จัดกึ่งกลางภาพ จนเกิดมาเป็น MNIST (Modified NIST) ชุดข้อมูลที่กลายเป็นสนามเด็กเล่นแห่งแรกที่ทำให้อัลกอริทึมอย่าง Convolutional Neural Network (CNN) ได้แจ้งเกิดอย่างเต็มตัว!
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทที่กว้างขึ้นของการประยุกต์ใช้ Image Classification แหล่งข้อมูลได้อธิบายบทบาทและลักษณะเฉพาะของ MNIST ไว้ดังนี้ครับ:
- 1. แมลงหวี่แห่งวงการ AI (The Drosophila of Machine Learning): Geoffrey Hinton ปรมาจารย์ด้าน Deep Learning เปรียบเทียบ MNIST ว่าเป็นเหมือน “แมลงหวี่ (Drosophila)” ของวงการ Machine Learning ในทางชีววิทยา นักวิจัยชอบใช้แมลงหวี่ทดลองเพราะมันเพาะพันธุ์ง่ายและเห็นผลลัพธ์ไว MNIST ก็เช่นกันครับ มันมีขนาดเล็ก โหลดง่าย ทำให้วิศวกรสามารถทดสอบไอเดียหรืออัลกอริทึมใหม่ๆ ได้อย่างรวดเร็ว (Fast iteration) ก่อนจะเอาไปรันกับข้อมูลจริง
- 2. โครงสร้างที่เรียบง่ายแต่ทรงพลัง (Simple yet Effective): ตัวชุดข้อมูลประกอบด้วยภาพตัวเลขเขียนด้วยลายมือ 0-9 (10 คลาส) จำนวน 60,000 ภาพสำหรับฝึกสอน (Training set) และ 10,000 ภาพสำหรับทดสอบ (Test set) แต่ละภาพเป็นภาพระดับสีเทา (Grayscale) ขนาดเพียง $28 \times 28$ พิกเซล ซึ่งเมื่อจับมาคลี่เป็นเวกเตอร์ 1 มิติ (Flatten) จะได้ความยาวเพียง 784 มิติเท่านั้น ทำให้ใช้ทรัพยากรคอมพิวเตอร์น้อยมาก
- 3. ของเล่นที่ถูกพิชิตแล้ว (A “Solved” Problem): ในยุคปัจจุบัน MNIST ถือเป็นปัญหาที่ “ง่ายเกินไป” แล้วครับ โมเดล CNN ธรรมดาๆ ก็สามารถทำความแม่นยำ (Accuracy) ได้ทะลุ 99% อย่างง่ายดาย ดังนั้นในงานวิจัยยุคใหม่ จึงไม่ค่อยมีใครใช้ MNIST มาเป็นตัวชี้วัดประสิทธิภาพความเก่งของโมเดลอีกต่อไป แต่มันยังคงทำหน้าที่เป็น “แบบฝึกหัดพื้นฐาน” ที่ดีเยี่ยม
- 4. อคติที่ซ่อนอยู่ (Human Bias in Dataset): ถึงจะเป็นชุดข้อมูลที่ดูสมบูรณ์แบบ แต่แหล่งข้อมูลชี้ให้เห็นว่า MNIST มี อคติ (Bias) แฝงอยู่ครับ! เนื่องจากข้อมูลมาจากคนอเมริกัน ลายมือส่วนใหญ่จึงเป็นสไตล์อเมริกัน เช่น เลข ‘7’ มักจะไม่มีขีดแนวนอนตรงกลาง (ต่างจากสไตล์ยุโรป) ดังนั้น ถ้านำโมเดลที่เทรนด้วย MNIST ไปใช้อ่านลายมือคนยุโรป อาจจะเกิดปัญหาเรื่อง Generalization (การสรุปความกับข้อมูลที่ไม่เคยเห็น) ได้ครับ
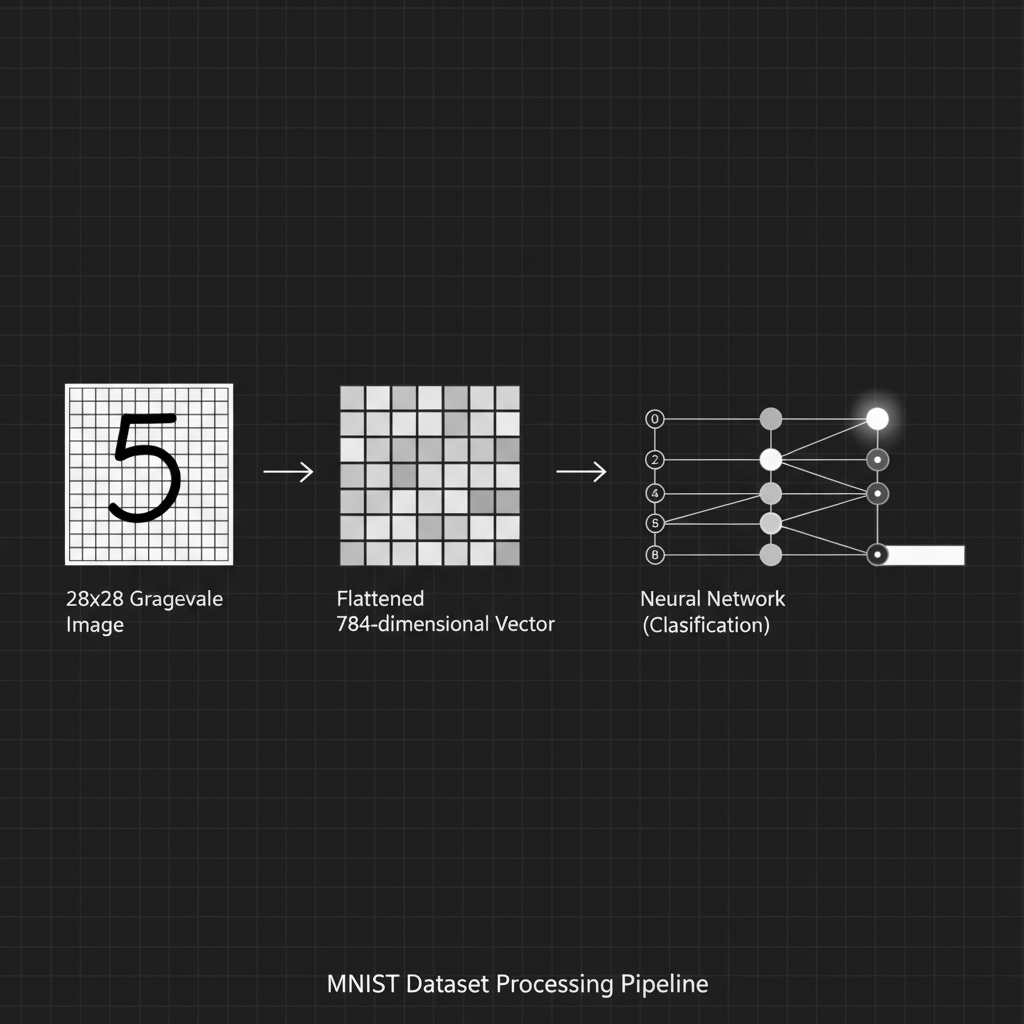
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ความเจ๋งของ MNIST คือมันถูกฝังอยู่ในไลบรารี Deep Learning ทุกตัวบนโลกครับ น้องๆ แทบไม่ต้องไปหาโหลดไฟล์ให้เหนื่อย ลองดูการโหลดและสร้างโมเดลจัดหมวดหมู่ (Classifier) ง่ายๆ ด้วย Keras กันครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
# -------------------------------------------------------------
# 📌 1. โหลดข้อมูล MNIST ผ่าน Keras API (ง่ายเหมือนดีดนิ้ว!)
# -------------------------------------------------------------
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# -------------------------------------------------------------
# 📌 2. ทำ Image Preprocessing ขั้นพื้นฐาน
# ภาพเดิมมีค่า Pixel 0-255 เราต้องทำ Normalization ให้อยู่ในช่วง
# เพื่อให้ Gradient Descent เดินลงเขาได้ง่ายขึ้น
# -------------------------------------------------------------
x_train = x_train / 255.0
x_test = x_test / 255.0
# -------------------------------------------------------------
# 📌 3. สร้างโมเดลสมองกล (Feedforward Neural Network หรือ Multi-layer Perceptron)
# -------------------------------------------------------------
model = models.Sequential([
# Flatten แปลงตารางภาพ 28x28 ให้เป็นเส้นก๋วยเตี๋ยว (Vector) ความยาว 784
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation='relu'), # ชั้นซ่อนเร้น (Hidden Layer)
layers.Dense(10, activation='softmax') # ทายผล 0-9 (Output Layer ให้ผลรวมความน่าจะเป็น = 1)
])
# -------------------------------------------------------------
# 📌 4. ประกอบร่างและเริ่มเทรน!
# ใช้ sparse_categorical_crossentropy เพราะ Label เราเป็นตัวเลข 0-9 เดี่ยวๆ ไม่ใช่ One-hot
# -------------------------------------------------------------
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# เทรนแค่ 5 รอบ (Epochs) ความแม่นยำก็พุ่งทะลุ 97% แล้วครับ!
model.fit(x_train, y_train, epochs=5)คอมเมนต์: สังเกตว่าโค้ดนี้แทบจะเอาไปรันบน CPU ธรรมดาของแล็ปท็อปน้องๆ ได้ในเวลาไม่กี่วินาทีเลยครับ นี่แหละคือข้อดีของการใช้ “แมลงหวี่” ในการทดสอบตรรกะการเขียนโค้ดของเรา!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในมุมมองของวิศวกรที่ทำระบบขึ้น Production จริง พี่มีข้อควรระวังในการใช้งาน MNIST มาเตือนกันครับ:
- อย่าใช้ MNIST อวดความเก่งของโมเดล: โลกของ Image Classification ไปไกลมากแล้วครับ ถ้าวันนี้น้องออกแบบสถาปัตยกรรมใหม่ (Novel Architecture) แล้วเคลมว่า “โมเดลผมเก่งมากเพราะทำคะแนน MNIST ได้ 99.5%!” วงการอาจจะขำเอาได้ครับ เพราะปัจจุบันเรามองว่า MNIST คือ Sanity Check (การทดสอบความสติแตก) หมายความว่า ถ้าน้องเขียนโค้ดแล้วทำคะแนนบน MNIST ได้น้อยกว่า 95%… แสดงว่า “โค้ดน้องน่าจะมีบั๊ก หรือตรรกะผิดพลาดอย่างรุนแรง” แน่นอนครับ!
- เมื่อ MNIST ง่ายไป สู่ยุคของ Fashion-MNIST: เนื่องจาก MNIST พื้นฐานเกินไป นักวิจัย (Zalando) จึงได้สร้างชุดข้อมูล Drop-in replacement (เปลี่ยนแค่ชื่อตัวแปร แล้วรันต่อได้เลย) ที่ชื่อว่า Fashion-MNIST ขึ้นมาแทนครับ โดยยังคงขนาด $28 \times 28$ และจำนวน 70,000 ภาพเหมือนเดิมเป๊ะ แต่เปลี่ยนจากตัวเลขเป็นภาพ “เสื้อผ้าและรองเท้า” 10 หมวดหมู่แทน ซึ่งยากกว่าและท้าทายกว่ามาก!
- โลกจริงไม่ได้สะอาดแบบนี้: จำไว้นะครับว่าภาพใน MNIST ถูกจับครอบ (Crop), จัดให้อยู่ตรงกลาง (Center), และลบภาพพื้นหลังทิ้งหมดแล้ว (Clean data) แต่ภาพกล้องวงจรปิดในโรงงานของน้องเต็มไปด้วยสัญญาณรบกวน (Noise) แสงเงา และวัตถุเอียงไปมา การเอาโมเดลจากบทเรียนไปใช้ตรงๆ โดยไม่ทำ Data Augmentation (เช่น หมุนภาพ, เพิ่ม Noise) โมเดลของน้องพังหน้างานแน่นอนครับ!
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว MNIST Dataset ไม่ได้เป็นเพียงแค่กล่องเก็บรูปภาพตัวเลข แต่มันคือ “ประตูบานแรก” ที่ต้อนรับวิศวกรทุกคนเข้าสู่โลกของ Computer Vision และ Image Classification การฝึกฝนกับชุดข้อมูลนี้ช่วยให้เราเข้าใจวงจรการทำงานตั้งแต่การเตรียมข้อมูล, การสร้างเครือข่าย, ไปจนถึงการประเมินผล โดยไม่ต้องรอคอมพิวเตอร์ประมวลผลนานหลายวัน
เมื่อเราพิชิต “แมลงหวี่” ได้แล้ว ในตอนถัดไป พี่จะพาน้องๆ ไปลุยกับบอสระดับมัธยมและระดับมหาลัยอย่าง CIFAR-10 และ ImageNet กันครับ ว่าเมื่อภาพเริ่มมี “สี (RGB)” มีรูปทรงที่ซับซ้อน และมีจำนวนคลาสเป็นพันๆ คลาส สถาปัตยกรรมระดับตำนานอย่าง ResNet หรือ VGGNet จะถูกงัดออกมาใช้อย่างไร รอติดตามให้ดีนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p