ไม้บรรทัดวัดความโง่เขลา: เจาะลึก Cross-Entropy Loss ทำไม AI ถึงต้องเจ็บปวดเมื่อทายผิด!
1. 🎯 ตอนที่ 38: ไม้บรรทัดวัดความโง่เขลา เจาะลึก Cross-Entropy Loss
สวัสดีครับน้องๆ วิศวกรสาย Vision และผู้หลงใหลใน AI ทุกท่าน! กาแฟแก้วโปรดพร้อมแล้วใช่ไหมครับ ในบทความที่แล้วเราได้ทำความรู้จักกับ Gradient Descent ซึ่งเป็น “เครื่องยนต์” ที่ใช้ขับเคลื่อนการเรียนรู้ของโมเดลกันไปแล้ว
แต่ก่อนที่เครื่องยนต์จะรู้ว่าต้องขับไปทางไหน มันต้องมี “ไม้บรรทัด” คอยตีกรอบและบอกมันก่อนว่า “ตอนนี้แกทำงานได้ห่วยแตกแค่ไหน!” สิ่งนั้นในโลกของ Machine Learning เรียกว่า Loss Function (ฟังก์ชันความสูญเสีย) ครับ
ในบริบทที่กว้างขึ้นของกระบวนการฝึกฝนโมเดล (Model Training) หากเราทำโจทย์แยกแยะประเภทรูปภาพ (Image Classification) อาวุธมาตรฐานที่วิศวกรทั่วโลกเลือกใช้คือสิ่งที่เรียกว่า Cross-Entropy Loss วันนี้พี่จะพาไปขุดคุ้ยกันว่า ทำไมฟังก์ชันทางคณิตศาสตร์หน้าตาแปลกๆ ที่มีลอการิทึม (Logarithm) ปนอยู่ ถึงกลายมาเป็นมาตรฐานทองคำที่ขาดไม่ได้ในโลกของ Deep Learning ครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องกำลังตรวจข้อสอบแบบปรนัยของนักเรียนคนหนึ่ง (ซึ่งก็คือ AI ของเรา) ข้อสอบถามว่า “รูปนี้คือสัตว์อะไร?” ก. แมว ข. หมา ค. ปลา ความจริงแล้วรูปนั้นคือ “หมา” (นี่คือ Ground Truth หรือสิ่งที่เราเฉลย)
ถ้านักเรียนตอบด้วยความมั่นใจว่า “ผมมั่นใจ 99% ว่ามันคือปลา!” สิ่งที่น้องต้องทำในฐานะครูคือการลงโทษ (Penalize) นักเรียนคนนี้อย่างหนักหน่วง เพื่อให้เขาจำฝังใจและไม่ตอบผิดแบบโง่ๆ อีก!
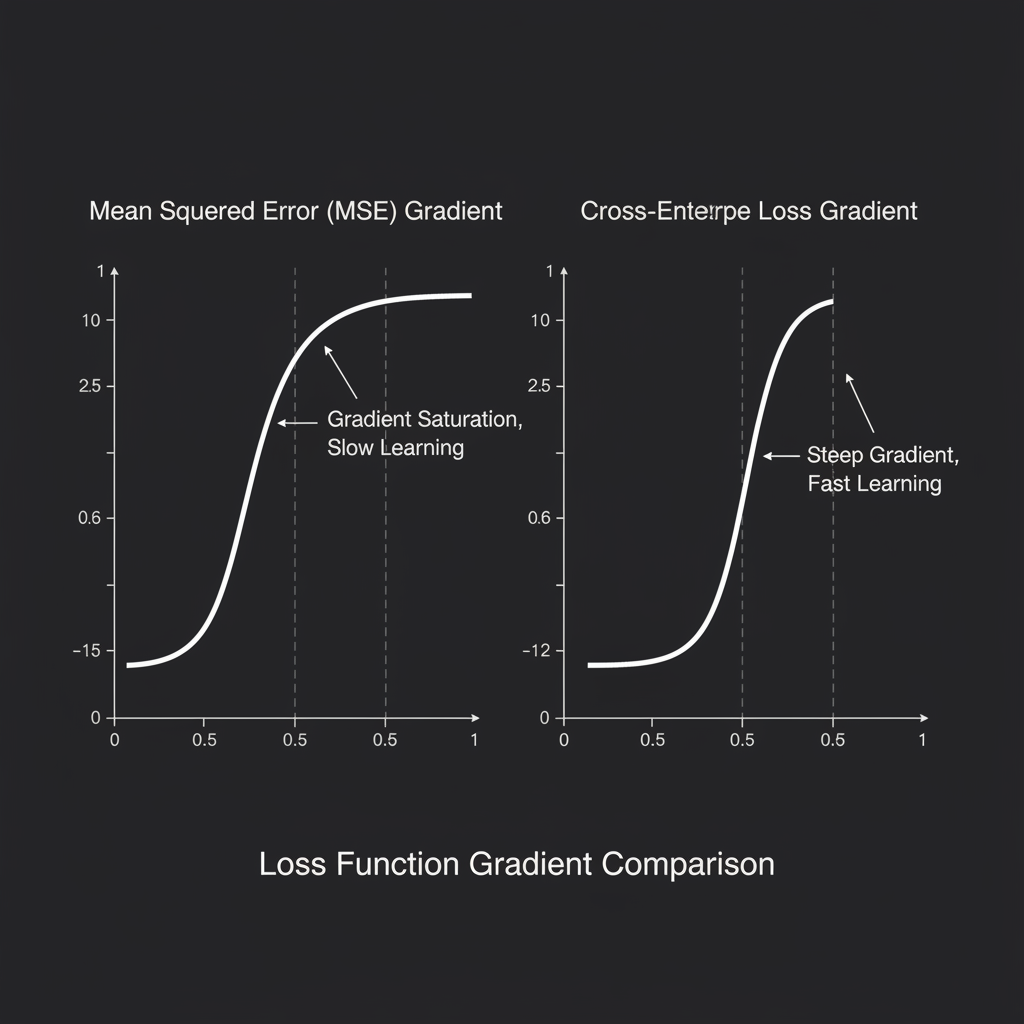
ในยุคแรกๆ วิศวกรลองใช้ไม้บรรทัดแบบ Mean Squared Error (MSE) มาวัดความผิดพลาดนี้ แต่ปรากฏว่าพอใช้คู่กับฟังก์ชันกระตุ้นอย่าง Sigmoid หรือ Softmax มันเกิดปัญหา “ครูใจดีเกินไป” ครับ คือพอนักเรียนทายผิดแบบสุดกู่ การอัปเดตน้ำหนัก (Gradient) กลับกลายเป็นศูนย์ (Gradient Saturation) ทำให้นักเรียนไม่ยอมเรียนรู้อะไรเลย!
โลกของ AI จึงต้องไปยืมแนวคิดมาจากทฤษฎีข้อมูล (Information Theory) และคลอดฟังก์ชันสุดโหดที่ชื่อว่า Cross-Entropy Loss ออกมา ซึ่งฟังก์ชันนี้มีนิสัยที่ว่า “ยิ่งแกมั่นใจในคำตอบที่ผิดมากเท่าไหร่ แกยิ่งต้องโดนตบ (Loss พุ่งสูงปรี๊ด) แรงมากเท่านั้น!”
3. 🧠 แก่นวิชา (Core Concepts)
แหล่งข้อมูลระดับโลกได้อธิบายแนวคิดและคณิตศาสตร์เบื้องหลังของ Cross-Entropy ไว้อย่างงดงาม ดังนี้ครับ:
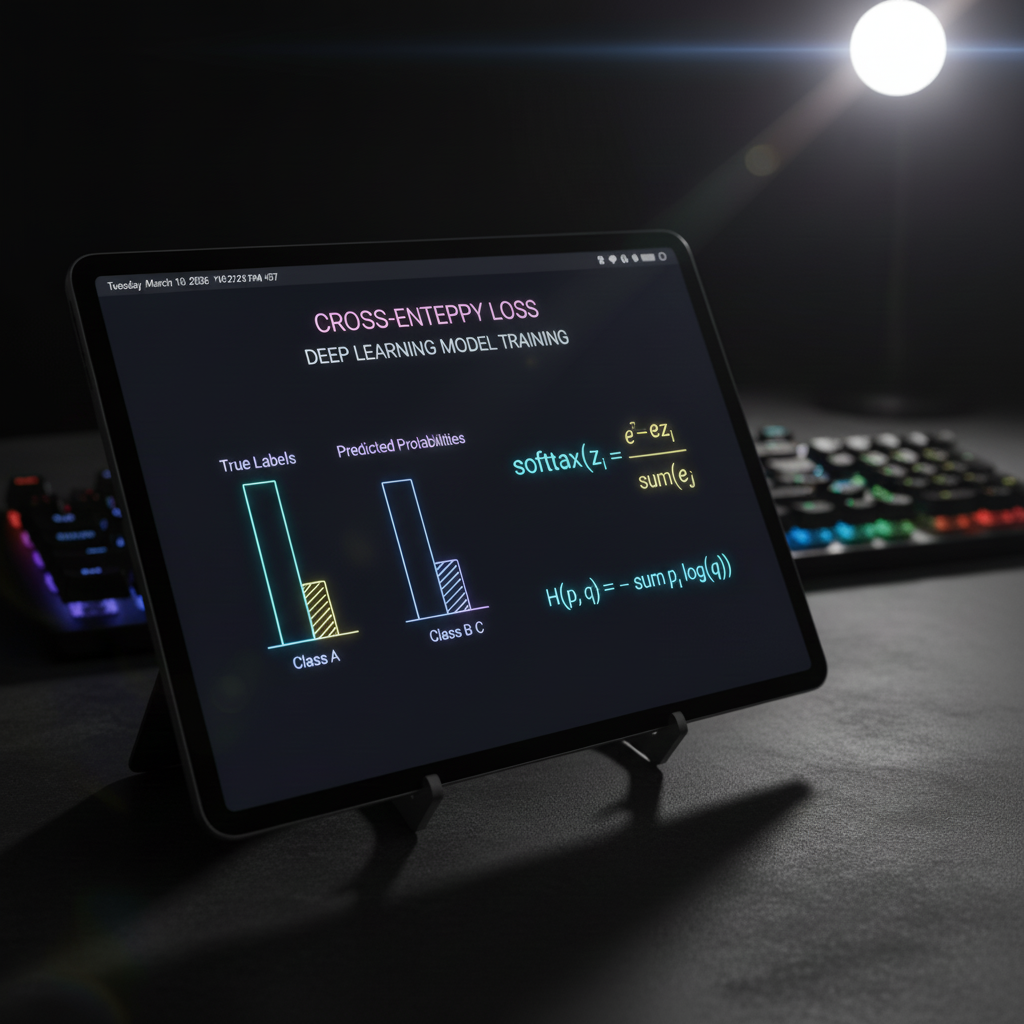
1. การเปรียบเทียบการกระจายความน่าจะเป็น (Probability Distributions): หน้าที่หลักของ Cross-Entropy คือการวัดว่า “ความน่าจะเป็นที่โมเดลทำนาย (Predicted Distribution)” มีหน้าตาห่างไกลจาก “ความน่าจะเป็นที่แท้จริง (True Distribution)” มากแค่ไหน สมมติความจริงคือ หมา 100% (1.0), แมว 0%, ปลา 0% แต่โมเดลทายว่า หมา 50% (0.5), แมว 30%, ปลา 20% ฟังก์ชันนี้จะคำนวณระยะห่างระหว่างสองชุดตัวเลขนี้ครับ
2. คู่หูดูโอ้ Softmax & Cross-Entropy: ในการทำ Multiclass Classification (แยกคลาสมากกว่า 2 คลาส) เรามักจะจบเลเยอร์สุดท้ายของ CNN ด้วยชั้น Softmax เสมอ เพราะมันจะแปลงคะแนนดิบๆ ให้กลายเป็นความน่าจะเป็น (รวมกันได้ 1.0 พอดี) หลังจากนั้น Cross-Entropy จะรับไม้ต่อเพื่อบีบคั้นให้ความน่าจะเป็นของคลาสที่ถูก ต้องเข้าใกล้ 1 ให้มากที่สุด
3. คณิตศาสตร์ของการลงโทษ (The Math): สมการของ Cross-Entropy สำหรับ 1 ตัวอย่างข้อมูล (ที่มีคลาสที่ถูกต้องเพียง 1 คลาส) เขียนได้ว่า:
$$ L = -\sum_{k=1}^{K} y_k \log(\hat{y}_k) $$
(เมื่อ $y_k$ คือป้ายกำกับเฉลย (มักเป็น 0 หรือ 1) และ $\hat{y}_k$ คือความน่าจะเป็นที่โมเดลทายออกมา)
สังเกตตรง $\log(\hat{y}k)$ นะครับ! ถ้าคลาสที่ถูกคือหมา ( $y{dog} = 1$ ) โมเดลจะสนใจเฉพาะค่าที่มันทายหมาออกมา ถ่ายมันทายหมาแค่ 0.01 (มั่นใจน้อยมากว่าใช่หมา) ค่า $-\log(0.01)$ จะได้ค่า Loss ที่ “สูงลิ่ว!” บังคับให้เกิดการปรับค่าน้ำหนักขนานใหญ่ผ่าน Backpropagation ครับ
4. ทำไมถึงขจัดปัญหา Vanishing Gradient ได้?: ความสวยงามที่สุดคือ เมื่อเรานำอนุพันธ์ (Derivative) ของ Cross-Entropy มาคูณกับอนุพันธ์ของ Softmax (ตามกฎลูกโซ่ Chain Rule) เทอมที่ซับซ้อนจะตัดกันทิ้งหมด! เหลือเพียงสมการง่ายๆ คือ $\hat{y} - y$ (สิ่งที่ทาย ลบด้วย ความจริง) ทำให้สัญญาณความผิดพลาด (Gradient) ถูกส่งย้อนกลับไปได้อย่างรุนแรงและตรงไปตรงมา โมเดลจึงเรียนรู้ได้เร็วปรู๊ดปร๊าดเลยครับ!
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ใน Keras และ TensorFlow การใช้งานฟังก์ชันอันล้ำลึกนี้ ถูกย่อมาให้เหลือแค่ข้อความสั้นๆ สตริงเดียวตอนที่เราเรียกคำสั่ง model.compile ครับ ลองดูโค้ดสำหรับงานแยกประเภทรูปภาพ 10 คลาส (เช่น CIFAR-10) กันครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
# สร้างโมเดล CNN แบบง่ายๆ จบท้ายด้วย Softmax สำหรับ 10 คลาส
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax') # 📌 บังคับให้ออกมาเป็นความน่าจะเป็น
])
# -------------------------------------------------------------
# 📌 ร่ายมนต์เรียกใช้ไม้บรรทัด (Loss Function)
# 'categorical_crossentropy' : ใช้เมื่อ Label ของเราเป็นแบบ One-hot encoding (เช่น [0, 0, 1, 0, ...])
# 'sparse_categorical_crossentropy' : ใช้เมื่อ Label ของเราเป็นตัวเลขเดี่ยวๆ (เช่น คลาสที่ 2)
# -------------------------------------------------------------
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# เริ่มการฝึกฝน
# model.fit(X_train, y_train, epochs=10)คอมเมนต์: ถ้าน้องๆ ทำโจทย์ Binary Classification (แยกแค่ หมา กับ แมว มีแค่ 2 คลาส) เลเยอร์สุดท้ายให้เปลี่ยนจาก Softmax เป็น sigmoid มี 1 นิวรอน และตัว Loss ให้เปลี่ยนเป็น 'binary_crossentropy' นะครับ!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในฐานะวิศวกรที่ต้องแก้ปัญหาหน้างานจริง พี่มีศาสตร์มืดเกี่ยวกับ Cross-Entropy มาเตือนกันครับ:
- ระวังปัญหา Log(0) เป็นอนันต์ (Numerical Instability):
ในทางคณิตศาสตร์ ถ้าโมเดลทายความน่าจะเป็นออกมาเป็น 0 เป๊ะๆ ค่า $-\log(0)$ จะพุ่งเข้าสู่ Infinity และทำให้โมเดลพัง (เกิดค่า NaN) ทันที! ใน TensorFlow เบื้องหลังมันจึงมักจะบวกค่า $\epsilon$ (epsilon ค่าที่เล็กมากๆ) เข้าไปกันพังเสมอ และนี่คือเหตุผลที่วิศวกรระดับโปร มักจะตัด Softmax เลเยอร์สุดท้ายทิ้ง และระบุใน Loss ว่า
from_logits=Trueเพื่อให้ TensorFlow คำนวณคณิตศาสตร์รวบยอดรวดเดียว ซึ่งจะเสถียรและหลีกเลี่ยงบั๊กได้ 100% ครับ! - มั่นใจเกินไปก็ไม่ดี (Label Smoothing): Cross-Entropy ปกติจะพยายามดึงให้ความน่าจะเป็นของคลาสเป้าหมายไปแตะ 1.0 (ซึ่งต้องใช้ค่า Weight เป็นอนันต์) ทำให้เกิดอาการ Overfitting ได้ง่าย วิศวกรจึงใช้ท่าที่เรียกว่า Label Smoothing โดยแทนที่จะบอกว่า “รูปนี้คือหมา 1.0” เราจะหลอกมันว่า “รูปนี้คือหมา 0.9 และเป็นคลาสอื่นๆ คลาสละเล็กน้อย” วิธีนี้ช่วยให้โมเดลไม่มั่นใจจนเกินงามและนำไปใช้กับหน้างานจริง (Generalization) ได้ดีขึ้นมากครับ!
- เมื่อข้อมูลไม่สมดุล (Class Imbalance): ถ้าน้องมีรูปของดี (Good) 10,000 รูป แต่มีรูปของเสีย (Defect) แค่ 10 รูป Cross-Entropy แบบธรรมดาจะโดนรูปของดี “กลบ (overwhelm)” จนมองไม่เห็นของเสียครับ แหล่งข้อมูลแนะนำให้ใช้ Focal Loss ซึ่งเป็นการเติมตัวแปรลงไปใน Cross-Entropy เพื่อ “ลดน้ำหนักความสำคัญ” ของคลาสที่โมเดลทายถูกบ่อยๆ (คลาสส่วนมาก) และไปโฟกัสกับคลาสที่ทายผิดบ่อยๆ (ของเสีย) แทนครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Cross-Entropy Loss คือส่วนประกอบสำคัญในกระบวนการฝึกฝนโมเดล (Model Training) ที่ทำงานเป็น “ไม้บรรทัดวัดความผิดพลาด” โดยใช้หลักการของลอการิทึมมาลงโทษโมเดลเมื่อมันทายผลผิดอย่างมั่นใจ
เมื่อนำมาจับคู่กับฟังก์ชัน Softmax มันช่วยทลายข้อจำกัดเรื่อง Gradient อิ่มตัว (Gradient Saturation) ที่เคยเกิดขึ้นตอนใช้ MSE ทำให้เครือข่ายประสาทเทียมสามารถรับรู้ความผิดพลาดและอัปเดตตัวเองผ่าน Backpropagation ได้อย่างรวดเร็วและทรงพลังครับ
ถึงตอนนี้ เราได้เรียนรู้การตั้งค่าเครื่องยนต์ การใช้ไม้บรรทัดวัดผล และการเดินลงเขาหาจุดต่ำสุดกันครบถ้วนแล้ว แต่คำถามคือ เราจะรู้ได้อย่างไรว่าโมเดลที่เราสอนมา มันไม่ได้แอบ “ท่องจำข้อสอบ” เข้าไป? ในบทความตอนต่อไป พี่จะพาน้องๆ ไปพบกับกลวิธีในการป้องกันไม่ให้ AI กลายเป็นเด็กฉลาดแต่หน้างานจริงทำไม่ได้ นั่นคือศาสตร์ของ Regularization และ Dropout ครับ รอติดตามความสนุกกันต่อได้เลย!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p