ซิ่งทะลุหมอก! เจาะลึก Stochastic Gradient Descent (SGD) หัวใจขับเคลื่อนการฝึก AI ให้ฉลาดล้ำ
1. 🎯 ตอนที่ 37: ซิ่งทะลุหมอก! เจาะลึก Stochastic Gradient Descent (SGD)
สวัสดีครับน้องๆ วิศวกรสาย Vision และนักพัฒนาทุกท่าน! กาแฟแก้วโปรดพร้อมแล้วใช่ไหมครับ ในตอนที่แล้วเราพูดถึง Model Training (การฝึกฝนโมเดล) และได้เห็นภาพรวมว่า AI เรียนรู้โดยการปรับค่าน้ำหนักผ่านการหาความชัน (Gradient)
แต่คำถามที่น่าสนใจคือ… ในโลกความเป็นจริงที่ข้อมูลภาพ (Datasets) ของเรามีขนาดมหาศาลระดับล้านๆ รูป การจะคำนวณความผิดพลาดทั้งหมดแล้วค่อย “ก้าวเดิน” ลงเขาหาจุดต่ำสุด (Minimum Error) มันช่างเชื่องช้าเสียเหลือเกิน! ในบริบทที่กว้างขึ้นของการฝึกฝนโมเดล วันนี้พี่จะพาไปเจาะลึกอัลกอริทึมยอดฮิตที่เปรียบเสมือน “เครื่องยนต์ V8” ของวงการ Deep Learning นั่นก็คือ Stochastic Gradient Descent (SGD) ครับ เรามาดูกันว่าความ “สุ่ม (Stochastic)” ของมัน กลับกลายเป็นเวทมนตร์ที่ช่วยให้โมเดลเก่งขึ้นได้อย่างไร!
2. 📖 เปิดฉาก (The Hook)
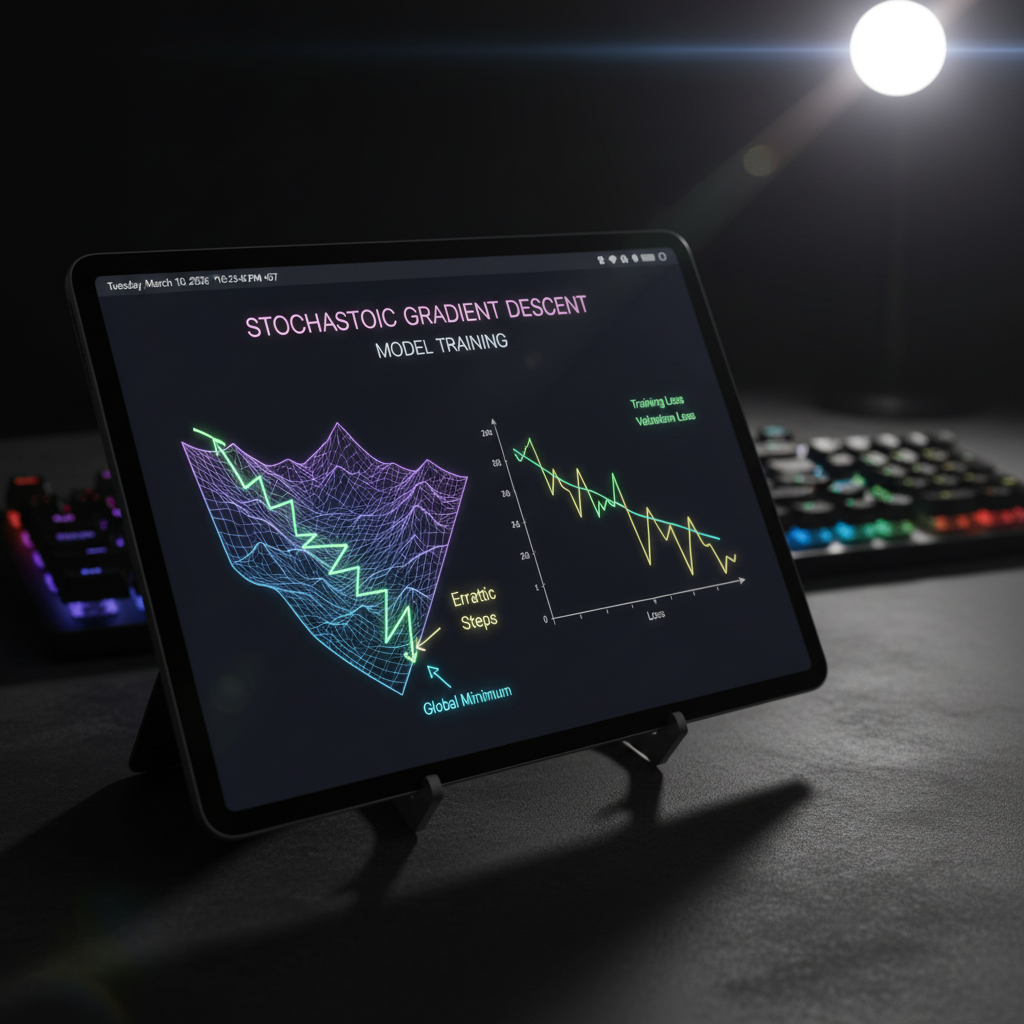
แหล่งข้อมูลระดับโลกเปรียบเทียบการทำงานของ Gradient Descent ไว้อย่างเห็นภาพครับ… ลองจินตนาการว่า น้องกำลังหลงทางอยู่บนภูเขาที่มีหมอกลงจัดจนมองไม่เห็นอะไรเลย ภารกิจของน้องคือการเดินลงไปให้ถึง “ก้นหุบเขา (จุดที่ต่ำที่สุดใน Loss Function)”
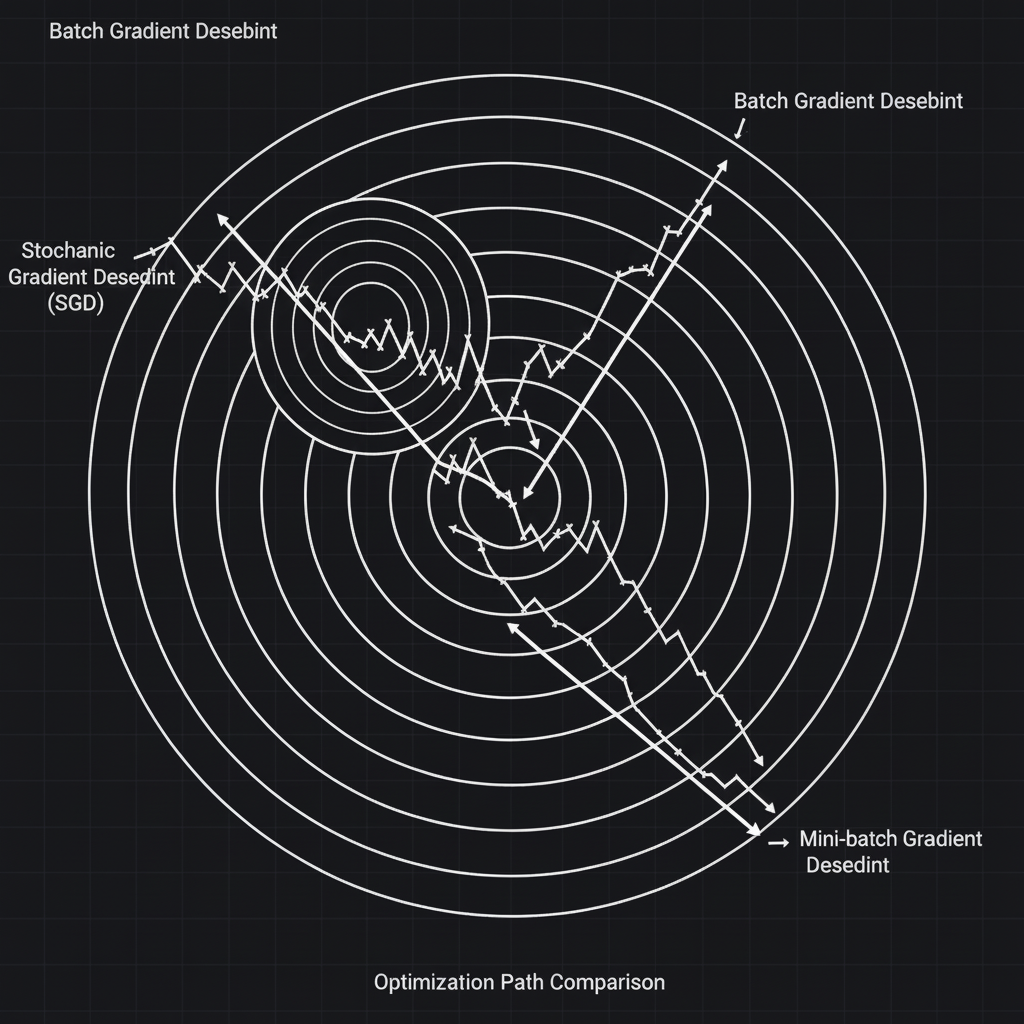
- ถ้าใช้วิธี Batch Gradient Descent (BGD) รุ่นเดอะ: น้องจะต้องให้ลูกน้องวิ่งไปสำรวจพื้นที่ “ทุกตารางนิ้วบนภูเขา (ใช้ข้อมูลทุกรูปใน Dataset)” เพื่อหาความชันเฉลี่ยที่แม่นยำที่สุด แล้วน้องค่อยก้าวเท้า 1 ก้าว… วิธีนี้แม่นยำครับ แต่ถ้าน้องมีข้อมูล 1 ล้านรูป กว่าจะได้ก้าว 1 ก้าว น้องคงแก่ตายไปก่อน!
- แต่ถ้าเปลี่ยนมาใช้ Stochastic Gradient Descent (SGD) รุ่นเล็กสายซิ่ง: น้องจะไม่รอลูกน้องครับ น้องจะหลับตา “สุ่ม (Random)” คลำความชันจากพื้นที่แค่ “จุดเดียว (ข้อมูล 1 รูป)” หรือ “หย่อมเล็กๆ (Mini-batch)” ถ้ารู้สึกว่าตรงนี้ลาดลงปุ๊บ น้องก้าวเลย!
ผลลัพธ์คือ น้องจะวิ่งลงเขาได้เร็วปรู๊ดปร๊าดมาก! แต่การเดินของน้องจะดูเหมือนคนเมาหน่อยๆ (Zigzagging / Noisy) เพราะน้องไม่ได้ดูภาพรวม แต่เชื่อไหมครับว่า… “ความเมา” หรือ “ความผันผวน (Noise)” นี่แหละ คือกุญแจสำคัญที่ทำให้ AI ของเรารอดตาย!
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทของการฝึกสมองกล แหล่งข้อมูลได้อธิบายบทบาทและกลไกของ SGD ไว้ดังนี้ครับ:
- 1. ความเร็วและสมรรถนะ (Speed & Scalability): ในขณะที่ Batch GD ต้องโหลดข้อมูลทั้งหมดเข้าแรม (RAM) ซึ่งเป็นไปไม่ได้สำหรับ Big Data แต่ SGD โหลดข้อมูลขึ้นมาทีละ 1 รูป (หรือกลุ่มเล็กๆ) ทำให้เราสามารถเทรนโมเดลขนาดใหญ่ด้วยทรัพยากรที่จำกัดได้ (Out-of-core learning)
- 2. การหลบหนีจากหลุมพราง (Escaping Local Minima): พื้นผิวความผิดพลาด (Loss surface) ของ Deep Learning มักไม่ได้เป็นชามเรียบๆ แต่เต็มไปด้วยหลุมย่อยๆ (Local Minima) การเดินที่แม่นยำเกินไปของ Batch GD มักจะไปติดแหง็กในหลุมย่อยเหล่านี้ แต่เนื่องจาก SGD มีทิศทางการเดินที่ “ผันผวน (Stochastic)” การกระเด้งกระดอนไปมาของมันกลับช่วยให้โมเดล “กระโดดหลุดรอด” ออกจากหลุมหลอกๆ ไปสู่ก้นหุบเขาที่แท้จริงได้เก่งกว่ามากครับ!
- 3. จุดสมดุล Mini-batch Gradient Descent: ในทางปฏิบัติ หากเราใช้ข้อมูลแค่ 1 รูป (Pure SGD) เราจะสูญเสียประโยชน์จากการคำนวณเมทริกซ์แบบขนาน (Matrix Multiplication) บนการ์ดจอ (GPU) ไปครับ วิศวกรจึงประนีประนอมด้วยการใช้ Mini-batch SGD คือสุ่มหยิบข้อมูลมาเป็นกลุ่มเล็กๆ เช่น 32, 64, หรือ 256 รูป แล้วค่อยก้าวเดิน วิธีนี้ได้ทั้งความเร็วจาก GPU และความเสถียรที่พอดี (ปล. ปัจจุบันเวลาคนพูดถึง SGD มักจะหมายถึง Mini-batch SGD เสมอครับ)
- 4. Implicit Regularization (การลด Overfitting แฝง): ความผันผวน (Variance) จากการสุ่มแบตช์ใน SGD ไม่ได้แค่ช่วยหนีหลุมพราง แต่มันยังมีคุณสมบัติในการช่วยตีกรอบ (Implicit Regularization) ให้โมเดลเลือกเดินไปหา “ก้นหุบเขาที่กว้างและแบน (Flat minima)” ซึ่งในทางทฤษฎีแล้ว จุดที่แบนกว้างจะช่วยให้โมเดลทำนายข้อมูลที่มันไม่เคยเห็น (Test set) ได้ดีกว่า (Generalize ดีกว่า) การตกไปในหลุมแคบๆ ครับ!
สมการการอัปเดตน้ำหนักของ SGD เขียนได้ง่ายๆ ว่า:
$$ w_{new} = w_{old} - \eta \cdot \nabla L_i $$
(เมื่อ $\eta$ คือ Learning Rate และ $\nabla L_i$ คือความชันที่คำนวณจากข้อมูลสุ่มเพียง 1 จุด หรือ 1 แบตช์)
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ใน Keras และ TensorFlow การเรียกใช้ SGD และการกำหนดขนาด Mini-batch ทำได้เรียบง่ายมากๆ ครับ ลองดูตัวอย่างนี้:
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.optimizers import SGD
# 1. สร้างโมเดลแบบง่าย
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.Dense(10, activation='softmax')
])
# -------------------------------------------------------------
# 📌 2. กำหนด Optimizer เป็น SGD
# - learning_rate: ความยาวของก้าวเดิน (เริ่มที่ 0.01 เป็นค่ามาตรฐานที่ดี)
# - momentum: ใส่แรงส่ง (ลูกเล่นเสริมของ SGD ที่ฮิตมาก)
# -------------------------------------------------------------
sgd_optimizer = SGD(learning_rate=0.01, momentum=0.9)
model.compile(optimizer=sgd_optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# -------------------------------------------------------------
# 📌 3. การเริ่มฝึกฝน (The Training Loop)
# - batch_size=32: นี่แหละครับคือการแปลงร่างเป็น "Mini-batch SGD"
# สุ่มหยิบ 32 รูป -> หาความชัน -> ก้าวเดิน 1 ก้าว!
# -------------------------------------------------------------
model.fit(X_train, y_train,
epochs=50,
batch_size=32,
shuffle=True) # 📌 สับไพ่ (Shuffle) สำคัญมากสำหรับ SGD!คอมเมนต์: สังเกตการตั้งค่า shuffle=True ใน model.fit() ไหมครับ? สำหรับ SGD การสับไพ่ข้อมูลทุกๆ Epoch คือหัวใจสำคัญเลยครับ เพื่อให้ข้อมูลที่ถูกป้อนเข้ามามีความเป็นอิสระต่อกัน (IID - Independent and Identically Distributed) ไม่งั้นโมเดลจะเรียนรู้แบบมีอคติ (Bias) ทันที
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในมุมมองของวิศวกรที่ลุยโปรเจกต์จริง พี่มีเคล็ดลับของ SGD มาฝากครับ:
- เวทมนตร์ของ Momentum:
แม้ SGD จะเก่ง แต่ความ “เมา” ของมันทำให้บางทีมันแกว่งไปมาซ้ายขวา (Oscillate) จนลงเขาช้า วิศวกรจึงเติม Momentum (แรงเฉื่อย) เข้าไป เปรียบเหมือนการกลิ้งลูกบอลหิมะลงเขา ทิศทางไหนที่ลาดลงเรื่อยๆ ลูกบอลจะสะสมความเร็ววิ่งฉิวไปเลย! การตั้งค่า
momentum=0.9เป็น Best Practice ที่ควบคู่กับ SGD แทบทุกงานครับ - อย่าปล่อยให้แกว่งจนจบ (Learning Rate Scheduling): ข้อเสียของความเมาคือ พอใกล้จะถึงก้นหุบเขา SGD มักจะ “กระเด้งข้ามไปมา” ไม่ยอมหยุดนิ่งที่จุดต่ำสุดเป๊ะๆ วิธีแก้ที่เจ๋งที่สุดคือ เราจะเริ่มด้วยก้าวยาวๆ ก่อน (Learning Rate สูง) พอใกล้จบ Epoch ท้ายๆ เราก็ใช้สูตร Learning Rate Decay (หรือ Simulated Annealing) ค่อยๆ หรี่ความยาวก้าวลงเรื่อยๆ เพื่อให้มันสงบลงและลงจอดได้อย่างสวยงามครับ
- เมื่อไหร่ควรใช้ SGD?: ถึงแม้ยุคนี้อัลกอริทึมอย่าง Adam จะฮิตมากเพราะเรียนรู้ไวและไม่ต้องจูนเยอะ แต่สำหรับโมเดลสาย Vision ระดับเทพๆ (เช่น ResNet บน ImageNet) เปเปอร์วิจัยส่วนใหญ่ยังคงใช้ SGD + Momentum ครับ เพราะเมื่อเราจูน Learning Rate Schedule ดีๆ SGD มักจะลู่เข้าสู่จุด Minimum ที่ Generalize กับ Test data ได้ดีกว่า (แบนและกว้างกว่า) Adam ครับ!
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Stochastic Gradient Descent (SGD) และร่างอัปเกรดอย่าง Mini-batch SGD คือเครื่องยนต์หลักที่ทำให้การฝึกฝน Deep Learning บนชุดข้อมูลขนาดยักษ์เป็นไปได้จริงในโลกใบนี้
ด้วยเทคนิคการ “สุ่ม” เพื่อคำนวณความชัน แทนที่จะคำนวณทั้งหมดในรอบเดียว ทำให้มันรวดเร็ว ทรงพลัง และมีคุณสมบัติซ่อนเร้นในการหลบหนีจากหลุมพราง (Local Minima) ซึ่งส่งผลให้โมเดล AI ของเราสามารถจดจำและแยกแยะวัตถุบนหน้างานจริงได้อย่างแม่นยำ
ในตอนหน้า เราจะมาเจาะลึกอัลกอริทึมสาย “ล้ำยุค” ที่ต่อยอดมาจาก SGD อย่าง Adam และ RMSProp กันบ้างครับ ว่าทำไมมันถึงกลายมาเป็น Default เริ่มต้นที่นักพัฒนา AI มือใหม่แทบทุกคนต้องกดใช้ รอติดตามนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p