ไขความลับ Gradient Descent: เข็มทิศนำทางสู่จุดต่ำสุดของการฝึกสมองกล

1. 🎯 ตอนที่ 37: ไขความลับ Gradient Descent เข็มทิศนำทางสู่ความฉลาด
สวัสดีครับน้องๆ วิศวกรสาย AI และ Vision ทุกท่าน! เติมกาแฟให้เต็มแก้วแล้วมาลุยกันต่อครับ ในบทความก่อนหน้านี้เราได้ทำความรู้จักกับกระบวนการ Model Training (การฝึกฝนโมเดล) ในภาพรวม และได้เห็นว่า Backpropagation ทำหน้าที่สืบสวนหาคนผิด (คำนวณ Gradient) ไปแล้ว
แต่เมื่อเรารู้แล้วว่าค่าน้ำหนัก (Weights) ตัวไหนทำผิด คำถามต่อมาคือ… “เราจะเดินไปในทิศทางไหน และก้าวเท้ายาวแค่ไหน เพื่อให้ความผิดพลาดนั้นลดลง?”
ในบริบทของการฝึกฝนโมเดล นี่คือหน้าที่ของพระเอกตัวจริงที่ชื่อว่า Gradient Descent ครับ! อัลกอริทึมตัวนี้เปรียบเสมือนเครื่องยนต์หลัก (Engine) ที่ขับเคลื่อนให้เกิดการเรียนรู้ของโครงข่ายประสาทเทียมแทบทุกรูปแบบบนโลกใบนี้ วันนี้พี่จะพาไปเจาะลึกกันว่า มันทำงานอย่างไร และมีวิทยายุทธ์กี่สายที่เราต้องรู้เพื่อเอาไปใช้งานจริงครับ!
2. 📖 เปิดฉาก (The Hook)
แหล่งข้อมูลระดับโลกได้เปรียบเปรยการทำงานของ Gradient Descent ไว้อย่างเห็นภาพครับ… ลองจินตนาการว่า น้องกำลังหลงทางอยู่บนยอดเขาที่มีหมอกลงจัดจนมองไม่เห็นอะไรเลย ภารกิจของน้องคือการเดินลงไปให้ถึง “ก้นหุบเขา (จุดที่ต่ำที่สุด)”
ถ้าน้องมองไม่เห็นทาง น้องจะทำอย่างไรครับ? สัญชาตญาณของมนุษย์คือ น้องจะใช้เท้า “คลำความชัน (Slope)” ของพื้นดินรอบๆ ตัว ถ้ารู้สึกว่าฝั่งไหนลาดลง น้องก็จะก้าวเท้าไปในทิศทางนั้น ก้าวไปเรื่อยๆ คลำไปเรื่อยๆ จนกระทั่งพื้นดินเริ่มแบนราบ (ความชันเป็นศูนย์) น้องก็จะรู้ตัวว่า “อ้อ! ฉันมาถึงก้นหุบเขาแล้ว!”
ในโลกของ AI ก้นหุบเขา ก็คือ จุดที่โมเดลมีความผิดพลาดต่ำที่สุด (Minimum Cost/Loss) และการเอาเท้าคลำหาความชัน ก็คือการหา Gradient ส่วนการก้าวเดินลงเขา ก็คืออัลกอริทึม Gradient Descent นั่นเองครับ! เรียบง่ายแต่งดงามไหมล่ะครับ?
3. 🧠 แก่นวิชา (Core Concepts)
เพื่อให้โมเดล AI สามารถอัปเดตตัวเองได้ อัลกอริทึมนี้มีสมการและตัวแปรหลักๆ ที่เราต้องควบคุมดังนี้ครับ:
- 1. ทิศทางและขนาดก้าวเดิน (The Update Rule): ในการอัปเดตค่าน้ำหนัก ($w$) โมเดลจะนำค่าเดิม มาลบออกด้วย “ความชัน (Gradient)” คูณกับ “ขนาดของก้าวเดิน (Learning Rate: $\eta$)” ตามสมการคลาสสิกนี้ครับ:
$$ w_{new} = w_{old} - \eta \cdot \nabla L $$
*(ถ้าความชันเป็นบวก แปลว่ากำลังขึ้นเขา เราต้องลบออกเพื่อเดินสวนทางลงมา)*
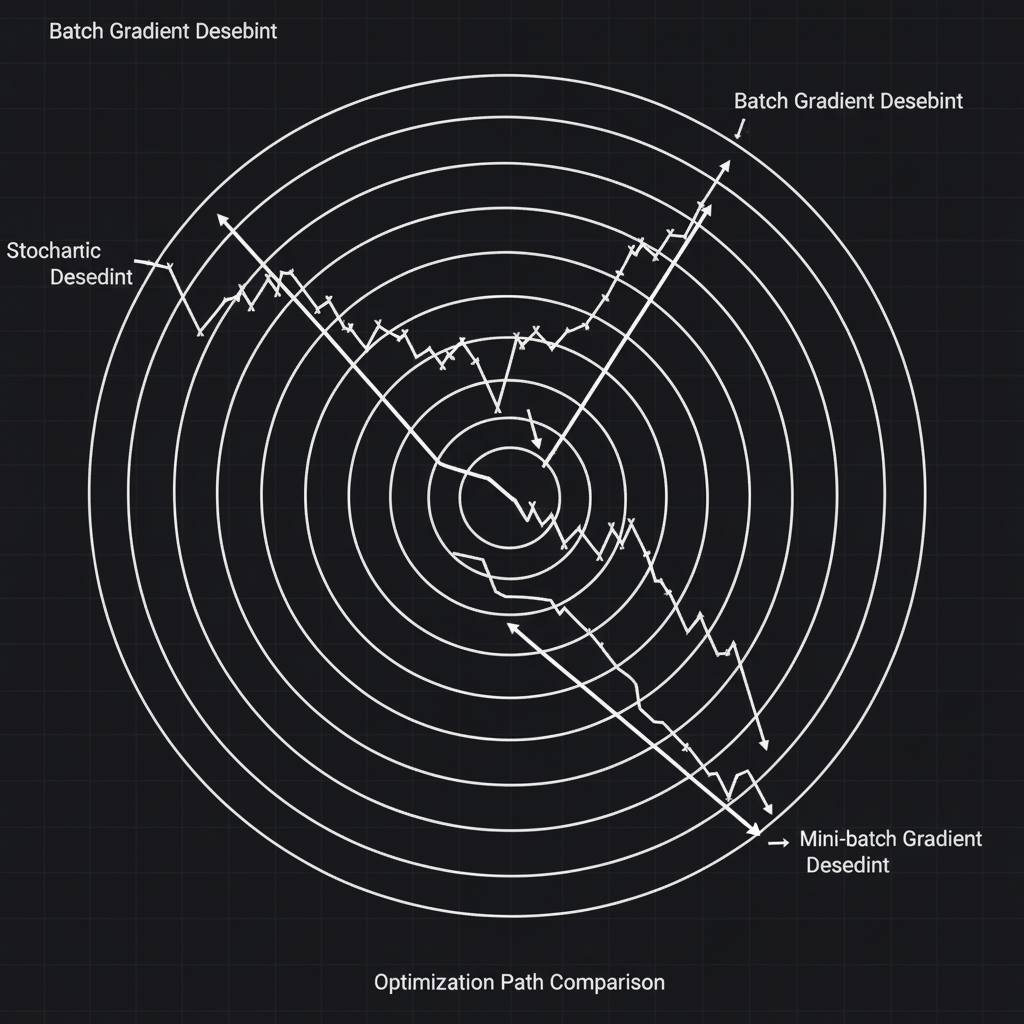
- 2. Batch Gradient Descent (รุ่นใหญ่ใจต้องนิ่ง): นี่คือรูปแบบดั้งเดิมที่สุดครับ การจะก้าวเท้า 1 ก้าว โมเดลจะขออ่านข้อมูลแบบฝึกหัด “ทั้งหมดทุกข้อ” ในชุดข้อมูล (Full Training Set) มาหาค่าเฉลี่ยความผิดพลาดก่อน ข้อดีคือมันเดินมุ่งตรงดิ่งไปยังเป้าหมายได้แม่นยำมาก แต่ข้อเสียคือ โคตรช้าและกินแรมมหาศาล! หากมีข้อมูล 1 ล้านรูป กว่าจะได้อัปเดตน้ำหนัก 1 ครั้ง รอจนหลับเลยครับ
- 3. Stochastic Gradient Descent (SGD) (รุ่นเล็กสายซิ่ง): เพื่อแก้ปัญหาความอืด SGD จึงเปลี่ยนกฎใหม่คือ “สุ่มหยิบข้อมูลมาแค่ 1 ตัว (Random instance)” คำนวณความชัน แล้วก้าวเดินเลย! ผลลัพธ์คือมันทำงานได้เร็วปรู๊ดปร๊าดมาก แต่ข้อเสียคือทิศทางการเดินของมันจะ “แกว่งไปมา (Noisy)” ดั่งคนเมา เพราะข้อมูล 1 ตัวไม่ได้เป็นตัวแทนที่ดีของข้อมูลทั้งหมด แต่ความแกว่งนี้แหละครับที่มีประโยชน์แฝง คือมันช่วยให้โมเดล “กระโดดหลุดรอดออกมาจากหลุมพราง (Local Minima)” ได้!
- 4. Mini-batch Gradient Descent (จุดสมดุลแห่งวงการ): ในทางปฏิบัติ วิศวกร AI จะใช้ทางสายกลางครับ นั่นคือสุ่มหยิบข้อมูลมาเป็นกลุ่มเล็กๆ (Mini-batch) เช่น 32, 64, หรือ 256 ตัว แล้วค่อยคำนวณก้าวเดิน 1 ก้าว วิธีนี้ได้ทั้งความรวดเร็วจากการประมวลผลแบบขนานบน GPU (Matrix Multiplication) และได้ทิศทางที่เสถียรขึ้นกว่า SGD แบบเพียวๆ ครับ (ปัจจุบันเวลาคนพูดถึง SGD ใน Deep Learning มักจะหมายถึง Mini-batch SGD เสมอครับ)
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ใน Keras การเรียกใช้งาน Optimizer อย่าง Gradient Descent หรือ SGD นั้นง่ายมากครับ แค่บรรทัดเดียวตอน model.compile พร้อมกับกำหนด Learning Rate ที่เหมาะสม:
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.optimizers import SGD
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.Dense(10, activation='softmax')
])
# -------------------------------------------------------------
# 📌 กำหนดเข็มทิศ (Optimizer)
# - lr (Learning Rate): กำหนดความยาวของก้าวเดิน (สำคัญที่สุด!)
# - momentum: เพิ่มแรงส่งให้เดินเร็วขึ้น (เดี๋ยวจะเล่าใน Pro-tips ครับ)
# -------------------------------------------------------------
optimizer = SGD(learning_rate=0.01, momentum=0.9)
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# -------------------------------------------------------------
# 📌 เริ่มเดินลงเขา (Training)
# - batch_size=32: นี่แหละครับคือ Mini-batch SGD! อ่านทีละ 32 รูปแล้วค่อยก้าวเดิน 1 ก้าว
# - epochs=50: วนอ่านชุดข้อมูลทั้งหมดซ้ำ 50 รอบ
# -------------------------------------------------------------
model.fit(X_train, y_train, batch_size=32, epochs=50)คอมเมนต์: สังเกตไหมครับว่าแค่เราเปลี่ยน batch_size อัลกอริทึมเบื้องหลังก็จะเปลี่ยนจาก Batch (ถ้าใส่เท่ากับจำนวนข้อมูลทั้งหมด) ไปเป็น Mini-batch ได้ทันที!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
เวลาเอาวิชานี้ไปลงสนามจริง ปัญหาโลกแตกที่วิศวกรทุกคนต้องเจอคือการจูนพารามิเตอร์ครับ พี่มีเคล็ดลับระดับโปรมาฝาก:
- ระวังชามก๋วยเตี๋ยวเบี้ยว (Feature Scaling is a MUST): ถ้าน้องมีข้อมูลที่สเกลต่างกันมาก (เช่น Feature 1 หลักหน่วย, Feature 2 หลักแสน) หุบเขา Error ของน้องจะมีรูปร่างเป็น “ชามวงรีที่ยืดยาว (Elongated bowl)” ครับ การทำ Gradient Descent จะแกว่งไปมาตามขอบชามและใช้เวลานานมากในการลงไปถึงก้นชาม! ดังนั้น ต้องทำ Data Normalization / Scaling ให้ค่าอยู่ระหว่าง 0 ถึง 1 เสมอก่อนเทรนนะครับ!
- ศิลปะของการตั้งค่า Learning Rate ($\eta$):
นี่คือ Hyperparameter ที่สำคัญที่สุด!
- ถ้าตั้ง ใหญ่เกินไป (Too large): ก้าวเท้าน้องจะยาวเกินไปจน “ก้าวข้าม (Overshoot)” จุดที่ต่ำที่สุดไปมา โมเดลจะไม่มีวันคอนเวอร์จ (Diverge)
- ถ้าตั้ง เล็กเกินไป (Too small): ก้าวน้องจะสั้นแบบมดเดิน ใช้เวลาเทรนเป็นชาติกว่าจะถึงจุดหมาย
- เทคนิค: วิศวกรมักใช้เทคนิค Learning Rate Scheduling คือช่วงแรกให้ก้าวยาวๆ เพื่อลงเขาไวๆ พอเริ่มเข้าใกล้ก้นหุบเขา ค่อยๆ ลดขนาดก้าวลง (Decay) เพื่อให้ไปหยุดที่จุดต่ำสุดได้อย่างนุ่มนวลครับ
- เมื่อโลกจริงไม่ได้เป็นแค่ชามก๋วยเตี๋ยว: ใน Deep Learning พื้นผิวความผิดพลาด (Loss surface) ไม่ได้เป็นหลุมหลุมเดียวแบบ Convex เสมอไป แต่มันเต็มไปด้วยหลุมย่อย (Local Minima) และที่ราบสูง (Plateau / Saddle points) การใช้ Mini-batch SGD จะช่วยเติม “สัญญาณรบกวน (Noise)” เล็กๆ ทำให้โมเดลมีโอกาสกระเด้งหลุดออกจากหลุมหลอกๆ เพื่อไปหาจุดต่ำสุดที่แท้จริง (Global Minima) ได้ดีกว่าการใช้ Batch เต็มๆ ครับ!
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Gradient Descent (และตัวแทนยอดฮิตอย่าง Mini-batch SGD) คือกลไกหลักที่คอยแปลผลความผิดพลาดจาก Loss Function ให้ออกมาเป็น “การกระทำ (Action)” เพื่ออัปเดตค่าน้ำหนักของเครือข่ายทีละก้าวๆ จนกว่า AI ของเราจะฉลาดขึ้นและทำนายผลได้อย่างแม่นยำ
แต่อย่างที่พี่บอกไปครับ การก้าวเดินลงเขาด้วย SGD ธรรมดา บางครั้งก็อาจจะช้าไป หรืออาจจะติดหล่มได้ง่าย โลกของ AI จึงได้คิดค้น “รองเท้าวิ่งจลน์ศาสตร์” ที่จะมาติดจรวดให้ SGD เก่งขึ้นไปอีก ไม่ว่าจะเป็นการเติม Momentum หรือการใช้ Adaptive Learning Rate อย่าง Adam
ในบทความถัดไป พี่จะพาน้องๆ ไปอัปเกรดเครื่องยนต์นี้กันครับ ว่าทำไมปัจจุบันนี้วิศวกรแทบทุกคนถึงนิยมใช้ optimizer='adam' เป็นค่า Default เริ่มต้นกันหมด! ห้ามพลาดเลยนะครับ สนุกแน่นอน!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p