ผ่าตัดสมอง AI: เจาะลึก Backpropagation กลไกย้อนกลับที่ทำให้จักรกลเรียนรู้จากความผิดพลาด

1. 🎯 ตอนที่ 36: ผ่าตัดสมอง AI เจาะลึก Backpropagation
สวัสดีครับน้องๆ วิศวกรสาย Vision และนักพัฒนาทุกคน! ชงกาแฟแก้วโปรดแล้วมานั่งล้อมวงกันต่อเลยครับ ในบทความที่แล้วเราได้เห็นภาพรวมของ “กระบวนการฝึกฝนโมเดล (Model Training)” กันไปแล้วว่ามันคือการทำงานร่วมกันของ Loss Function และ Gradient Descent
แต่วันนี้ พี่จะพาไปเจาะลึก “จิ๊กซอว์ชิ้นที่สำคัญที่สุด” ที่ทำให้ Deep Learning เกิดขึ้นได้จริงบนโลกใบนี้ มันคืออัลกอริทึมระดับตำนานที่ชื่อว่า Backpropagation (การแพร่ย้อนกลับ) ครับ ในบริบทที่กว้างขึ้นของการฝึกฝนโมเดล อัลกอริทึมนี้เปรียบเสมือน “ระบบประสาทที่คอยส่งความรู้สึกเจ็บปวด (Error)” กลับไปบอกสมองส่วนต่างๆ ว่าใครเป็นคนทำพลาด เพื่อให้เกิดการปรับปรุงตัวอย่างตรงจุด เรามาแกะกล่องดำดูวิชาคณิตศาสตร์สุดงดงามที่ซ่อนอยู่เบื้องหลังกันครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องเป็นผู้จัดการโรงงานที่ดูแลพนักงานในสายพานการผลิต 3 แผนก (Layer 1, 2, 3) วันหนึ่ง สินค้าที่ออกมาตอนท้ายสุดเกิด “มีตำหนิ (Error)” ถ้าน้องใช้วิธีด่ากราดทุกคนแบบสุ่ม โรงงานคงไม่พัฒนาแน่ๆ สิ่งที่ผู้จัดการที่ฉลาดทำคือการ “สืบสวนย้อนกลับ (Backward pass)”
น้องจะเดินไปถามพนักงานแผนกที่ 3 ว่า “น้องพลาดตรงไหน?” พนักงานคนที่ 3 อาจจะบอกว่า “ผมทำถูกแล้ว แต่พนักงานแผนกที่ 2 ส่งของมาเบี้ยว!” น้องก็เดินย้อนกลับไปถามแผนก 2 ต่อไปเรื่อยๆ จนถึงต้นทาง เพื่อสืบหาว่าความผิดปกตินี้มีต้นตอมาจากใคร และใครต้องรับผิดชอบกี่เปอร์เซ็นต์ เพื่อปรับปรุงแก้ไข (Update weights) ให้ถูกต้องในรอบถัดไป
นี่แหละครับคือหลักการทำงานของ Backpropagation! ในยุคก่อนปี 1986 โลก AI พยายามสร้างโครงข่ายประสาทที่มีหลายชั้น (Multi-layer networks) แต่พวกเขามืดแปดด้านเพราะ “ไม่รู้วิธีสอนมัน” จนกระทั่งงานวิจัยอันโด่งดังของ Rumelhart, Hinton, และ Williams ได้ชุบชีวิตวงการนี้ขึ้นมาด้วยอัลกอริทึม Backpropagation ซึ่งทำให้ AI สามารถเรียนรู้ฟังก์ชันที่ซับซ้อนได้อย่างมีประสิทธิภาพ!
3. 🧠 แก่นวิชา (Core Concepts)
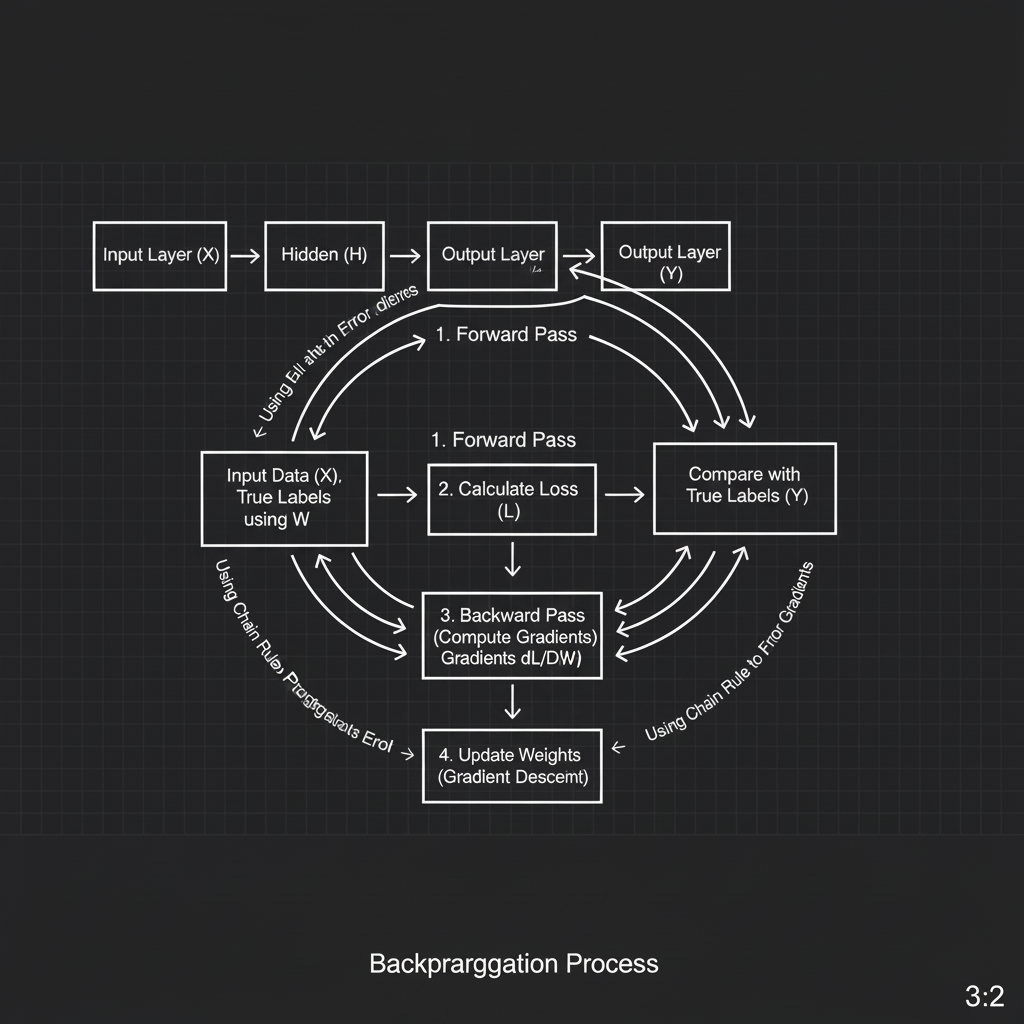
ในบริบทของการฝึกฝนสมองกล แหล่งข้อมูลระดับโลกได้อธิบายสถาปัตยกรรมและกลไกของ Backpropagation ไว้ 2 เฟสหลักๆ ดังนี้ครับ:
- 1. สเต็ปเดินหน้า (The Forward Pass): ในขั้นตอนนี้ ข้อมูล Input จะถูกป้อนเข้าสู่เครือข่าย ไหลผ่านแต่ละเลเยอร์ เกิดการคูณน้ำหนัก (Weights) รวมกับ Bias และผ่านฟังก์ชันกระตุ้น (Activation Function) ไปเรื่อยๆ จนถึงปลายทางได้ผลลัพธ์การทำนาย (Prediction) ออกมา ระหว่างทาง โมเดลจะ “จดจำ (Store) ค่าที่คำนวณได้ในแต่ละโหนด” เอาไว้ในหน่วยความจำ เพราะมันจำเป็นต้องใช้ในสเต็ปถัดไป
- 2. กฎลูกโซ่แห่งเวทมนตร์ (The Chain Rule of Calculus): เมื่อเราเอาผลทำนายไปเทียบกับความจริงจนได้ค่าความผิดพลาด (Loss) แล้ว คำถามคือ “น้ำหนักตัวที่ 1 (ในเลเยอร์แรกสุด) ส่งผลต่อ Loss รวมกี่เปอร์เซ็นต์?” เพื่อหาคำตอบ Backprop อาศัยสมการคณิตศาสตร์ที่เรียกว่า กฎลูกโซ่ (Chain Rule) ในการหาอนุพันธ์ย่อย (Partial Derivatives) ย้อนหลังกลับไปทีละชั้น โดยเอาค่าความชันของเลเยอร์หลัง มาคูณกับความชันของเลเยอร์ก่อนหน้า ต่อกันเป็นทอดๆ
- 3. สเต็ปถอยหลัง (The Backward Pass): กระบวนการนี้จะเริ่มจากเลเยอร์สุดท้าย คำนวณหา Gradient ของ Loss เทียบกับน้ำหนักแต่ละตัว แล้ว “ส่งต่อ (Propagate)” ค่า Gradient กลับไปหาเลเยอร์ก่อนหน้า ท้ายที่สุดเราจะได้ค่าชี้เป้าหมายที่บอกว่า “น้ำหนักแต่ละเส้นควรจะปรับเพิ่มหรือลดลงเท่าไหร่” (และนี่คือจุดที่เราส่งค่า Gradient พวกนี้ไปให้ Optimizer อย่าง Gradient Descent หรือ Adam ทำการอัปเดตน้ำหนักต่อไป)
- 4. Reverse-Mode Autodiff: วิศวกรยุคนี้เรียกเทคนิคเบื้องหลัง Backprop ว่า Reverse-mode Automatic Differentiation (Autodiff) ซึ่งเป็นวิธีการคำนวณ Gradient บนกราฟการคำนวณ (Computation Graph) ที่แม่นยำและรวดเร็วมาก เหมาะกับโครงข่ายที่มีพารามิเตอร์นับล้านตัวแต่มี Output เพียงค่าเดียว (คือค่า Loss)
สมการกฎลูกโซ่ (Chain Rule) ที่เป็นหัวใจของความฉลาดนี้ เขียนง่ายๆ ได้ว่า:
$$ \frac{\partial Loss}{\partial Weight_{input}} = \frac{\partial Loss}{\partial Output} \cdot \frac{\partial Output}{\partial Hidden} \cdot \frac{\partial Hidden}{\partial Weight_{input}} $$
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
สมัยก่อน วิศวกรต้องมานั่งเขียนสมการคณิตศาสตร์หาอนุพันธ์ (Derivatives) ของแต่ละเลเยอร์ด้วยมือ (ซึ่งบั๊กกระจายและปวดหัวมาก!) แต่ในยุคปัจจุบัน ไลบรารีอย่าง PyTorch ได้ซ่อนความซับซ้อนของ Reverse-mode Autodiff ไว้ใต้คำสั่งสั้นๆ เพียงบรรทัดเดียวครับ ลองดูโครงสร้างการฝึกฝน (Training Loop) นี้:
import torch
import torch.nn as nn
import torch.optim as optim
# 1. สร้างโมเดลสมองกลอย่างง่าย (Multi-Layer Perceptron)
model = nn.Sequential(
nn.Linear(10, 64), # รับ Input 10 ตัว
nn.ReLU(), # ฟังก์ชันกระตุ้น (สำคัญมาก ต้องหาอนุพันธ์ได้!)
nn.Linear(64, 1) # ทายผลลัพธ์ 1 ตัว
)
# 2. กำหนด Loss Function และ Optimizer (เปรียบเสมือนผู้ตรวจงานและผู้ลงมือแก้)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# สมมติว่ามีข้อมูลภาพและเฉลย
inputs = torch.randn(32, 10) # Mini-batch 32 ตัว
targets = torch.randn(32, 1)
# -------------------------------------------------------------
# 📌 วงจรการฝึกฝนโมเดล (The Training Loop)
# -------------------------------------------------------------
optimizer.zero_grad() # ล้างค่า Gradient เก่าทิ้งก่อนเริ่มงานใหม่
# สเต็ปที่ 1: Forward Pass (เดินหน้าทำนายผล)
predictions = model(inputs)
loss = criterion(predictions, targets)
# สเต็ปที่ 2: Backward Pass (ร่ายมนต์ Backpropagation สั่งสืบสวนย้อนกลับ!)
# คำสั่งนี้บรรทัดเดียว จะไล่ทำ Chain Rule ให้ทุกตัวแปรใน Computation Graph อัตโนมัติ!
loss.backward()
# สเต็ปที่ 3: Update Weights (ให้ Optimizer เดินลงเขาตามทิศทางความชันที่สืบมาได้)
optimizer.step()
print(f"Loss ปัจจุบัน: {loss.item():.4f}")คอมเมนต์: น้องๆ เห็นความมหัศจรรย์ของ loss.backward() ไหมครับ? ภายใต้คำสั่งสั้นๆ นี้ มันคือคณิตศาสตร์เมทริกซ์แคลคูลัส (Matrix Calculus) นับล้านการกระทำที่ส่ง Error ย้อนกลับไปหา nn.Linear ทุกชั้นในเสี้ยววินาที!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในมุมมองของการเอาไปทำระบบจริง พี่มีปัญหาลึกๆ ที่เกิดจาก Backprop มากระซิบบอกครับ:
- คำสาปของความชันจางหาย (The Vanishing Gradient Problem): เมื่อเราทำ Backprop ด้วยการ “คูณ” ค่าอนุพันธ์ติดต่อกันยาวๆ ในเครือข่ายที่ลึก (Deep Network) ถ้าค่าอนุพันธ์พวกนั้นน้อยกว่า 1 (เช่น การใช้ฟังก์ชัน Sigmoid หรือ Tanh) คูณกันหลายๆ รอบเข้า ค่า Gradient จะลดลงจนกลายเป็นศูนย์ (เข้าใกล้ 0) ผลคือ เลเยอร์แรกๆ จะไม่เกิดการเรียนรู้อะไรเลย! วิธีแก้สุดคลาสสิกคือเปลี่ยนไปใช้ฟังก์ชัน ReLU หรือใช้สถาปัตยกรรมแบบ ResNet (Skip connections) และใส่ Batch Normalization
- ปัญหาระเบิดตู้ม! (Exploding Gradients): ตรงข้ามกับข้อแรก ถ้าค่าอนุพันธ์มากกว่า 1 คูณกันไปเรื่อยๆ Gradient จะพุ่งสูงปรี๊ดจนค่าพารามิเตอร์เพี้ยน (NaN) มักเจอในโครงข่ายแบบ RNN วิธีแก้ที่วิศวกรนิยมใช้คือการทำ Gradient Clipping หรือการตัดยอด Gradient ไม่ให้สูงเกินเกณฑ์ที่กำหนด
- เจาะเวลาหาอดีต (Backpropagation Through Time - BPTT): สำหรับโครงข่ายแบบอนุกรมเวลา (RNN/LSTM) ตอนทำ Forward Pass เราจะคลี่ (Unroll) กราฟออกตามกาลเวลา ตอนทำ Backward Pass มันก็จะไหลย้อนกลับผ่านกาลเวลาเช่นกัน ซึ่งยิ่งประโยคยาวเท่าไหร่ ก็ยิ่งเกิดปัญหา Vanishing/Exploding Gradient ได้ง่ายขึ้นเท่านั้น
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว อัลกอริทึม Backpropagation ไม่ใช่แค่สูตรเลขธรรมดา แต่มันคือ “กลไกการรับรู้ความผิดพลาดและปรับตัว” ที่พลิกโฉมโลกของ Artificial Intelligence ให้ก้าวเข้าสู่ยุค Deep Learning อย่างเต็มตัว
การผสานพลังกันระหว่าง Forward Pass (เพื่อรับรู้โลก) $\rightarrow$ Loss Function (เพื่อรู้จุดอ่อนตนเอง) $\rightarrow$ Backward Pass (Backprop) (เพื่อหาคนรับผิดชอบ) และปิดท้ายด้วย Gradient Descent (เพื่อลงมือแก้ไข) คือกระบวนทัศน์หลัก (Paradigm) ของการฝึกสมองกลทุกประเภทยังคงใช้มาจนถึงทุกวันนี้ครับ!
เมื่อเราสอน AI ได้แล้ว เราจะรู้ได้อย่างไรว่ามัน “พร้อมใช้งานจริง” หรือแค่ “ท่องจำข้อสอบเพื่อมาหลอกเรา”? ในตอนถัดไป พี่จะพาน้องๆ ไปทำความรู้จักกับศัตรูตัวฉกาจของนักพัฒนา AI อย่างภาวะ Overfitting และเรียนรู้วิธีใช้อาวุธลับอย่าง Regularization และ Dropout มาปราบมันให้สิ้นซากครับ รอติดตามได้เลย!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p