วิชาฝึกสมองกล: แกะรอยกระบวนการ Model Training พื้นฐานสำคัญที่ AI ใช้เรียนรู้โลก

1. 🎯 ตอนที่ 35: วิชาฝึกสมองกล แกะรอยกระบวนการ Model Training
สวัสดีครับน้องๆ วิศวกรสาย Vision ทุกท่าน! จิบกาแฟให้ชุ่มคอแล้วมาลุยกันต่อครับ ตลอดหลายตอนที่ผ่านมา เราพูดถึงโครงสร้างของสถาปัตยกรรม (Architectures) ต่างๆ กันมาเยอะมาก ไม่ว่าจะเป็น CNN, RNN, หรือ YOLO
แต่คำถามที่น่าสนใจคือ… ต่อให้เราออกแบบโครงสร้าง “สมอง” มาดีแค่ไหน ถ้ามันไม่เคยถูก “สั่งสอน” มันก็เป็นแค่ตารางตัวเลขสุ่มๆ ที่ทายอะไรไม่ถูกเลยใช่ไหมครับ? ในบริบทที่กว้างขึ้นของ พื้นฐานการเรียนรู้เชิงลึก (Deep Learning Fundamentals) กระบวนการ การฝึกฝนโมเดล (Model Training) คือหัวใจสำคัญที่สุดที่เปลี่ยนเครือข่ายโง่ๆ ให้กลายเป็นผู้เชี่ยวชาญระดับโลก วันนี้พี่จะพาไปเจาะลึกว่า ภายใต้กระโปรงรถของระบบ AI มันมีกลไกอะไรทำงานอยู่ตอนที่เรากดปุ่ม “Train” ครับ!
2. 📖 เปิดฉาก (The Hook)
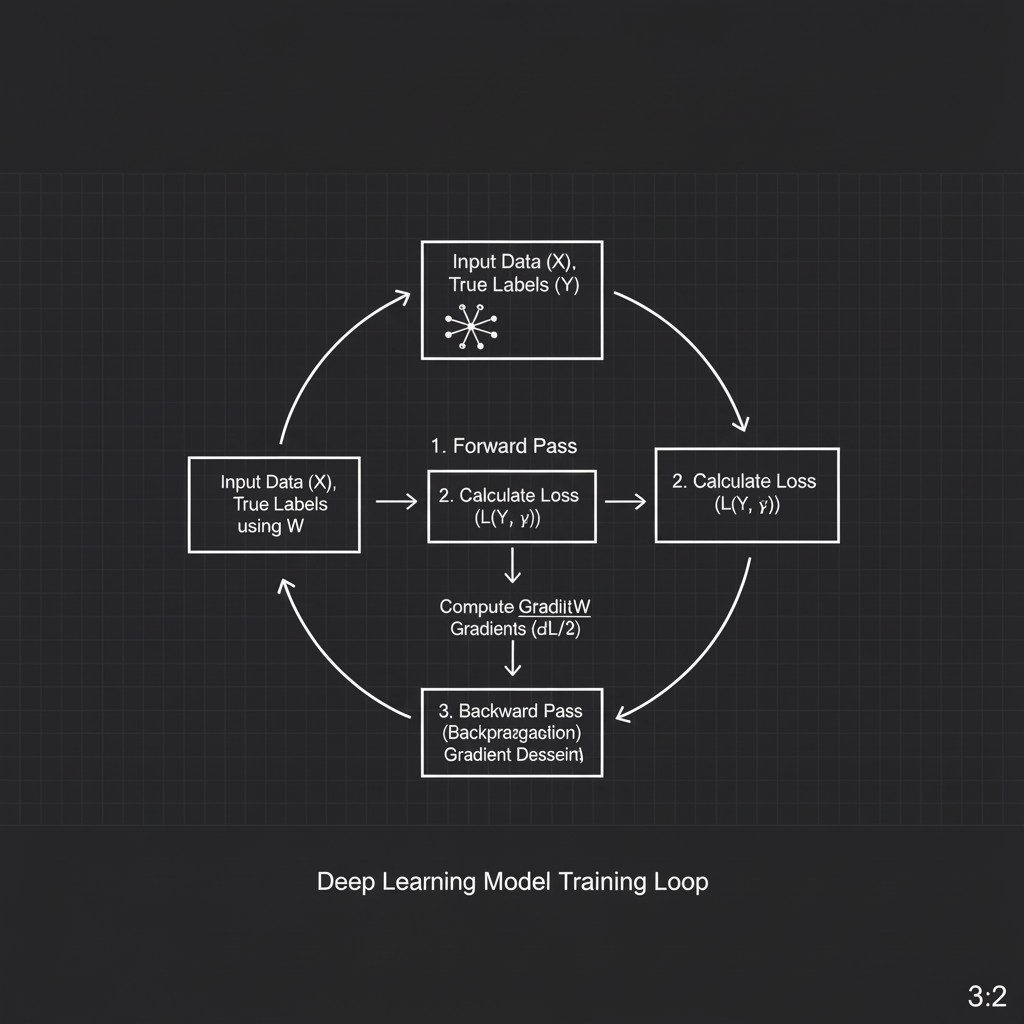
ลองจินตนาการว่าน้องกำลังสอนพนักงานใหม่ (โมเดล AI) ให้คัดแยกชิ้นงานที่สายพานการผลิต ในวันแรก พนักงานคนนี้จะไม่รู้อะไรเลย พอมีของไหลมา เขาก็ “เดาสุ่ม” (Random Initialization) ถัดมาน้องในฐานะหัวหน้า (Supervisor) ก็จะถือไม้บรรทัดคอยตรวจผลงาน ถ้าพนักงานทายผิด น้องก็จะบอกว่า “ผิดนะ อันนี้มันของเสีย!” (นี่คือการคำนวณ Loss) จากนั้นพนักงานก็จะเอาความผิดพลาดนี้ “กลับไปทบทวนและปรับปรุงวิธีคิด” เพื่อให้รอบหน้าทายได้แม่นขึ้น (นี่คือ Backpropagation และ Gradient Descent)
เมื่อทำซ้ำๆ เป็นพันเป็นหมื่นรอบ พนักงานคนนี้ก็จะเริ่มจับจุดสังเกตได้เอง และทำงานได้แม่นยำอย่างน่าเหลือเชื่อ! และนี่แหละครับคือสิ่งที่เรียกว่า Supervised Learning (การเรียนรู้แบบมีผู้สอน) ซึ่งเป็นรากฐานของการฝึกฝนโมเดลในปัจจุบัน
3. 🧠 แก่นวิชา (Core Concepts)
แหล่งข้อมูลระดับโลกได้อธิบายองค์ประกอบสำคัญที่เป็นฟันเฟืองขับเคลื่อนการเรียนรู้ของโมเดลไว้ดังนี้ครับ:
- 1. Loss Function (ไม้บรรทัดวัดความกาก): ทุกครั้งที่โมเดลทายผลออกมา (Forward pass) เราต้องมีฟังก์ชันทางคณิตศาสตร์เพื่อวัดว่า “คำตอบที่ทาย” ห่างไกลจาก “คำตอบที่ถูกต้อง (Ground truth)” แค่ไหน ยิ่งค่า Loss สูง แปลว่าโมเดลยิ่งโง่ ฟังก์ชันยอดฮิตเช่น Cross-Entropy Loss สำหรับงานจัดหมวดหมู่ (Classification) หรือ Mean Squared Error (MSE) สำหรับงานทำนายตัวเลข (Regression)
- 2. Backpropagation (การส่งข้อความย้อนกลับ): เมื่อรู้แล้วว่าผิดพลาดแค่ไหน อัลกอริทึม Backpropagation จะทำงานโดยคำนวณย้อนกลับจากเลเยอร์สุดท้ายไปหาเลเยอร์แรกสุด เพื่อหาว่า “ค่าน้ำหนัก (Weights) ตัวไหนในเครือข่ายที่เป็นต้นเหตุของความผิดพลาดนี้ และต้องปรับแก้ไปในทิศทางใด” (หาค่า Gradient หรือความชัน)
- 3. Gradient Descent (การเดินลงเขาหาจุดต่ำสุด): นี่คืออัลกอริทึมในการ “อัปเดต” ค่าน้ำหนักครับ เปรียบเหมือนคนปิดตาที่พยายามเดินลงจากยอดเขาเพื่อหาจุดต่ำสุด (จุดที่ Loss ต่ำที่สุด) โดยก้าวเดินไปในทิศทางตรงข้ามกับความชัน (Negative Gradient) อัลกอริทึมยุคใหม่ที่นิยมใช้คือ Stochastic Gradient Descent (SGD) และ Adam ที่ช่วยให้เดินลงเขาได้ฉลาดและเร็วขึ้น
- 4. การแบ่งชุดข้อมูล (Train / Validation / Test Splits):
เพื่อไม่ให้ AI “จำข้อสอบ (Overfitting)” เราต้องแบ่งข้อมูลออกเป็น 3 ส่วนครับ:
- Training Set: ข้อสอบแบบฝึกหัด ให้ AI ดูเฉลยและปรับปรุงตัวเอง
- Validation Set: ข้อสอบย่อยกลางภาค เอาไว้วัดผลระหว่าง Train เพื่อปรับจูน Hyperparameters (เช่น ปรับ Learning Rate) โดย AI จะไม่ได้ใช้ชุดนี้ในการอัปเดตน้ำหนัก
- Test Set: ข้อสอบปลายภาคที่ AI ไม่เคยเห็นมาก่อนในชีวิต เอาไว้วัดความเก่งที่แท้จริง (Generalization)
สมการพื้นฐานของการอัปเดตน้ำหนักใน Gradient Descent คือ:
$$ w_{new} = w_{old} - \eta \cdot \nabla L $$
(เมื่อ $w$ คือค่าน้ำหนัก, $\eta$ (Learning Rate) คือขนาดของก้าวเดิน, และ $\nabla L$ คือความชันของ Loss)
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ใน Keras การรวมกลไกสุดซับซ้อนอย่าง Backpropagation และ Gradient Descent ถูกบีบอัดให้อยู่ในโค้ดไม่กี่บรรทัดครับ ลองดูตัวอย่างการสั่ง Train โมเดลกัน:
import tensorflow as tf
from tensorflow.keras import layers, models
# 1. สมมติว่าเรามีโมเดลสร้างเตรียมไว้แล้ว
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.Dense(10, activation='softmax')
])
# -------------------------------------------------------------
# 📌 2. การคอมไพล์โมเดล (กำหนดวิธีการเรียนรู้)
# - optimizer='adam': เลือกวิธีเดินลงเขาที่ฉลาด (Gradient Descent รูปแบบหนึ่ง)
# - loss='sparse_categorical_crossentropy': ไม้บรรทัดวัดความผิดพลาดสำหรับงานแยกคลาส
# -------------------------------------------------------------
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# -------------------------------------------------------------
# 📌 3. เริ่มวงจรการฝึก (Training Loop)
# - epochs=10: ให้โมเดลวนอ่านหนังสือเรียน (Training data) จนจบเล่มซ้ำ 10 รอบ
# - batch_size=32: อ่านทีละ 32 ข้อ (Mini-batch) แล้วค่อยอัปเดตน้ำหนัก 1 ครั้ง (เร็วกว่าอัปเดตทีละข้อ)
# - validation_split=0.2: หักข้อมูล 20% ไว้เป็นข้อสอบย่อย (Validation set)
# -------------------------------------------------------------
history = model.fit(X_train, y_train,
epochs=10,
batch_size=32,
validation_split=0.2)คอมเมนต์: สังเกตการใช้ batch_size นะครับ ในทางปฏิบัติเรามักไม่ป้อนข้อมูลทั้งหมดลงไปรวดเดียวเพราะแรมจะเต็ม แต่เราจะหั่นเป็นชุดเล็กๆ (Mini-batches) ซึ่งทำให้ทิศทางการอัปเดตน้ำหนักมีความแกว่ง (Stochastic) แต่กลับช่วยให้โมเดลหนีออกจากหลุมพราง (Local Minima) ได้ดีครับ!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
พี่มีทริควิชาลึกๆ จากหน้างานจริงเกี่ยวกับการฝึกโมเดลมาฝากครับ:
- วิชาหนีการจำข้อสอบ (Combatting Overfitting): ถ้าโมเดลของน้อง Loss ในฝั่ง Train ลดลงเรื่อยๆ แต่ Loss ในฝั่ง Validation กลับเด้งสูงขึ้น แปลว่ามันกำลัง “ท่องจำข้อสอบ” แล้วครับ! วิธีแก้คือต้องใช้ท่า Regularization เช่น การใส่ Dropout Layer (ปิดการทำงานของนิวรอนบางตัวชั่วคราว), หรือการทำ Data Augmentation (หมุนภาพ, พลิกภาพ, ใส่ Noise เพิ่มเพื่อสร้างข้อมูลจำลอง)
- ทางลัดสู่ความสำเร็จ (Transfer Learning & Fine-tuning): ในยุคนี้ การ Train โมเดลภาพจากศูนย์ (From scratch) เป็นเรื่องสิ้นเปลืองมากครับ วิศวกรนิยมโหลดโมเดลที่พรีเทรนแล้ว (เช่น โหลดน้ำหนักจาก ImageNet) มาใช้งาน โดยในช่วงแรกของการ Train เราจะสั่ง “แช่แข็ง (Freeze)” เลเยอร์แรกๆ ไว้ไม่ให้น้ำหนักที่ดีอยู่แล้วพังทลาย แล้วค่อยๆ อัปเดตเฉพาะเลเยอร์ท้ายๆ ก่อน (เรียกว่า Fine-tuning) วิธีนี้ประหยัดเวลาและได้ผลดีมาก!
- ระวังปัญหาความชันจางหาย (Vanishing Gradients): ในเครือข่ายที่ลึกมากๆ ตอนทำ Backpropagation สัญญาณความผิดพลาดมักจะเจือจางหายไปจนเลเยอร์แรกๆ ไม่ได้เรียนรู้อะไรเลย ปัญหานี้แก้ได้ด้วยการใช้ Activation function อย่าง ReLU, การใช้โครงสร้าง ResNet (Skip connections), และการใส่ชั้น Batch Normalization ครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว องค์ความรู้ด้าน Model Training คือหัวใจที่เสกให้คณิตศาสตร์และตัวเลขสุ่มๆ กลายเป็นปัญญาประดิษฐ์ที่รู้คิดได้จริง ด้วยความร่วมมือกันของ Loss Function ที่คอยชี้เป้าความผิดพลาด, Backpropagation ที่หาคนรับผิดชอบ, และ Gradient Descent ที่ทำการปรับปรุงแก้ไข ทำให้เครือข่ายสามารถซึมซับความรู้จากข้อมูลได้อย่างมีประสิทธิภาพสูงสุด
เมื่อเรามีโมเดลที่ฝึกฝนมาอย่างดีแล้ว ในบทความถัดไป พี่จะพาน้องๆ ไปดูว่าเราจะ “ประเมิน (Evaluate)” ความเก่งกาจของมันอย่างไรให้ชัวร์ว่าเอาไปลงหน้างานแล้วจะไม่พัง! มารู้จักกับตัวชี้วัดอย่าง Precision, Recall และ mAP กันครับ รอติดตามได้เลย!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p