ก้าวข้ามการมองเห็น สู่โลกของการตีกรอบด้วย Object Detection (R-CNN, SSD, YOLO)

1. 🎯 ตอนที่ 33: ก้าวข้ามการมองเห็น สู่โลกของการตีกรอบด้วย Object Detection
สวัสดีครับน้องๆ วิศวกรสาย Vision ทุกท่าน! กาแฟพร้อมแล้วใช่ไหมครับ วันนี้พี่จะพาน้องๆ ก้าวข้ามพรมแดนจากบทความที่แล้ว ที่เราทำได้แค่บอกว่า “ภาพนี้คืออะไร (Image Classification)” ไปสู่คำถามที่ล้ำลึกยิ่งกว่า นั่นคือ “ของสิ่งนั้น มันอยู่ตรงไหนในภาพบ้าง? (Object Detection)”
ในบริบทของการประยุกต์ใช้งานคอมพิวเตอร์วิทัศน์ (Computer Vision Applications) บนโลกความจริง เช่น รถยนต์ไร้คนขับ (Autonomous Vehicles) ที่ต้องหลบคนเดินถนน, แขนกลในโรงงานที่ต้องหยิบจับชิ้นงาน (Robotics), หรือระบบรักษาความปลอดภัย การแค่รู้ว่า “มีคนอยู่ในภาพ” นั้นไม่พอครับ ระบบจำเป็นต้อง “ตีกรอบ (Bounding Box)” ให้ได้แม่นยำและรวดเร็วระดับเสี้ยววินาที!
วันนี้เราจะมาเจาะลึก 3 ขุนพลแห่งวงการ Object Detection ระดับตำนานอย่างตระกูล R-CNN, SSD, และ YOLO ว่าสถาปัตยกรรมเหล่านี้มีวิธีคิดที่แตกต่างกันอย่างไร และมันพลิกโฉมวงการอุตสาหกรรมได้อย่างไร ลุยกันเลยครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องเป็น รปภ. ที่ต้องดูกล้องวงจรปิด ถ้าน้องใช้อัลกอริทึมยุคเก่า (Image Classification) พอมันเห็นภาพปุ๊บ มันจะตอบแค่ว่า “มีผู้บุกรุก” แต่มันไม่ยอมบอกว่าอยู่มุมไหนของจอ! กว่าน้องจะกวาดสายตาหาเจอ โจรก็วิ่งหนีไปแล้ว
ยุคเริ่มต้นของ Object Detection วิศวกรพยายามแก้ปัญหานี้ด้วยการเอากรอบสี่เหลี่ยม (Sliding Window) ค่อยๆ เลื่อนกวาดไปทั่วภาพทีละพิกเซล แล้วส่งเข้า CNN ไปทายผล ซึ่งมัน “ช้าบรรลัย” เลยครับ! จนกระทั่งเหล่านักวิจัยได้คิดค้นวิธีที่ชาญฉลาดกว่า แบ่งออกเป็น 2 สำนักใหญ่ๆ คือ “นักสืบจอมประณีต (Two-Stage Detectors)” และ “นินจาความเร็วสูง (Single-Stage Detectors)” ซึ่งการต่อสู้ของ 2 สำนักนี้แหละครับ คือตัวขับเคลื่อนเทคโนโลยี AI หน้างานที่เราใช้กันอยู่ทุกวันนี้
3. 🧠 แก่นวิชา (Core Concepts)
แหล่งข้อมูลระดับโลกได้แบ่งสถาปัตยกรรมของ Object Detection ออกเป็น 2 กลุ่มหลักตามวิธีการตีกรอบ (Bounding Box) และการจำแนกคลาส (Classification) ดังนี้ครับ:
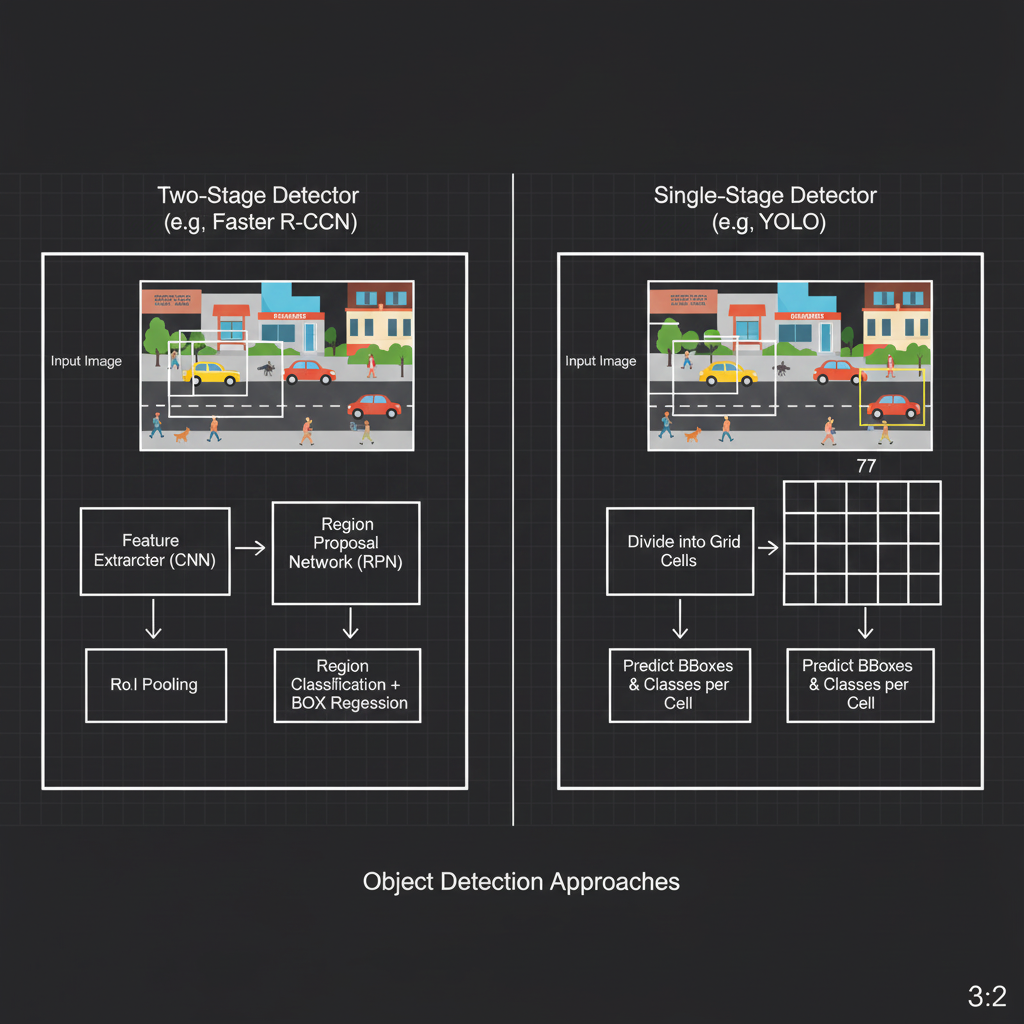
1. สำนัก Two-Stage Detectors (ช้าแต่ชัวร์): ตระกูล R-CNN ทำงาน 2 ขั้นตอน คือ 1. หาว่าบริเวณไหนน่าจะมีของ (Region Proposals) 2. เอาบริเวณนั้นมาทายว่าเป็นของอะไร
- R-CNN (2014): จุดเริ่มต้นตำนาน ใช้อัลกอริทึม Selective Search หากรอบที่น่าสนใจมา 2,000 กรอบ แล้วส่งเข้า CNN ทีละอัน (ทำงานช้ามาก)
- Fast R-CNN (2015): ฉลาดขึ้น เอาภาพทั้งภาพส่งเข้า CNN รอบเดียวก่อน แล้วค่อยเอา 2,000 กรอบไปดึง Features ย่อย (RoI Pooling) ออกมา ทำให้เร็วขึ้นมาก
- Faster R-CNN (2016): ถึงขั้นเปลี่ยนวงการ! เพราะโยน Selective Search ทิ้งไป แล้วสร้าง Region Proposal Network (RPN) ซึ่งเป็น AI ตัวเล็กๆ มาทำหน้าที่ “ชี้เป้า” (Attention) แทน ทำให้โมเดลทำงานแบบ End-to-End บน GPU ได้เต็มตัว แม่นยำสูงมาก (มักใช้ในงานการแพทย์ หรือระบบที่ต้องการความชัวร์สูง)
2. สำนัก Single-Stage Detectors (ตาดูดาว เท้าก้าวไว): YOLO และ SSD ทำงานรวดเดียวจบ (One-shot) มองภาพครั้งเดียวตอบได้เลยว่าของอยู่ไหนและคืออะไร
- YOLO (You Only Look Once): โมเดลสายซิ่งที่หั่นภาพออกเป็นตาราง (Grid) เช่น 13x13 ช่อง แล้วให้แต่ละช่องรับผิดชอบในการทายผลและตีกรอบไปพร้อมๆ กัน มันเร็วขนาดที่รันบนวิดีโอสดแบบ Real-time ได้สบายๆ (มักใช้ในงานรถยนต์ไร้คนขับ หรือกล้องวงจรปิด)
- SSD (Single Shot MultiBox Detector): เกิดมาเพื่ออุดจุดอ่อนของ YOLO ยุคแรกที่มองไม่เห็นของชิ้นเล็กๆ SSD จะดึง Feature Maps จาก “หลายๆ เลเยอร์ (Multi-scale feature layers)” ที่ความละเอียดต่างกันมาทายผล ทำให้มันตีกรอบจับวัตถุได้ทั้งชิ้นเล็กและชิ้นใหญ่ได้อย่างแม่นยำ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในหน้างานจริง วิศวกรเรานิยมนำโมเดลยอดฮิตอย่าง YOLOv3 (หรือเวอร์ชันใหม่ๆ) ที่พรีเทรนแล้ว (Pre-trained) มาประยุกต์ใช้งานทันทีผ่านไลบรารี OpenCV ซึ่งเขียนได้สั้นและทรงพลังมาก ลองดูตัวอย่างนี้ครับ:
import cv2
import numpy as np
# -------------------------------------------------------------
# 📌 โหลดโมเดล YOLOv3 (ผ่าน OpenCV DNN Module)
# ต้องการไฟล์ weights (น้ำหนัก) และ cfg (โครงสร้างสถาปัตยกรรม)
# -------------------------------------------------------------
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
classes = open("coco.names").read().strip().split("\n")
# -------------------------------------------------------------
# 📌 เตรียมภาพและส่งเข้าเครือข่าย YOLO
# -------------------------------------------------------------
image = cv2.imread("factory_floor.jpg")
height, width = image.shape[:2]
# แปลงภาพเป็น Blob (ทำ Image Preprocessing) ก่อนส่งให้ YOLO
blob = cv2.dnn.blobFromImage(image, 1/255.0, (416, 416), swapRB=True, crop=False)
net.setInput(blob)
# สั่งให้โมเดลประมวลผล (มองภาพรอบเดียว!)
layer_names = net.getLayerNames()
output_layers = [layer_names[i - 1] for i in net.getUnconnectedOutLayers()]
detections = net.forward(output_layers)
# หลังจากนี้คือการเขียน Loop วนอ่านค่า Bounding Box, Confidence Score
# และทำ Non-Maximum Suppression (NMS) เพื่อวาดกรอบลงบนภาพต่อไป...คอมเมนต์: สังเกตบรรทัด cv2.dnn.blobFromImage นะครับ นี่คือท่ามาตรฐานในการย่อภาพให้เหลือ 416x416 (ขนาดที่ YOLO ชอบ) พร้อมกับปรับค่าสเกลพิกเซลก่อนป้อนเข้า “สมอง” ของมันครับ
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
สำหรับวิศวกรที่ต้องเอา Object Detection ไป Deploy บน Edge Devices หรือ IoT พี่มีวิชาลับและมาตรวัดผลที่น้องต้องรู้มาฝากครับ:
- เวทมนตร์ของ NMS (Non-Maximum Suppression): เวลาน้องรัน YOLO หรือ SSD ตอนแรกมันจะพ่นกรอบสี่เหลี่ยมซ้อนๆ กันออกมาเต็มไปหมด (สมมติว่าเจอกรอบล้อมหมา 5 กรอบ) เราต้องใช้ NMS เพื่อเลือก “กรอบที่ดีที่สุดแค่กรอบเดียว” โดยอิงจากค่า Confidence Score สูงสุด แล้วลบกรอบที่ซ้อนทับกันเกินเกณฑ์ทิ้งไป
- IoU (Intersection over Union) คือไม้บรรทัดวัดใจ: เวลาเราจะรู้ว่า AI ตีกรอบได้แม่นแค่ไหน เราจะคำนวณค่า IoU ครับ มันคือการเอา “พื้นที่กรอบที่ AI ทาย (Prediction)” มาหาพื้นที่ทับซ้อนกับ “พื้นที่กรอบที่มนุษย์ขีดไว้ (Ground Truth)” สมการคือ: $IoU = \frac{Area_of_Overlap}{Area_of_Union}$ ถ้า IoU > 0.5 ถือว่าจับภาพได้ (True Positive) ครับ
- mAP (mean Average Precision): ในการแข่งขันระดับโลกอย่าง MS COCO เราไม่ได้วัดผลกันที่ Accuracy ธรรมดาแบบงาน Classification นะครับ แต่เราใช้ mAP ซึ่งเกิดจากการเอาค่า Precision สูงสุดของทุกๆ คลาสมาหาค่าเฉลี่ย ถือเป็นดัชนีชี้วัด “ความเก่ง” ของ Object Detector ที่แท้จริงครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว งาน Object Detection คือการผสานศาสตร์ของการทายภาพ (Classification) และการวาดกรอบ (Localization/Regression) เข้าด้วยกันอย่างลงตัว
หากโปรเจกต์ของน้องต้องการความแม่นยำระดับหยดน้ำ (เช่น งานวิเคราะห์ภาพทางการแพทย์) ตระกูล Faster R-CNN คือพระเอก แต่ถ้าน้องต้องการให้ระบบทำงานเรียลไทม์บนกล้องวงจรปิดหรือหุ่นยนต์เคลื่อนที่ตระกูล YOLO หรือ SSD คือทางเลือกที่กินขาดในด้านความเร็วและสามารถนำไปยัดลง Edge IoT Devices ได้อย่างสมบูรณ์แบบ!
แต่ความฝันของมนุษยชาติยังไม่หยุดแค่นี้ครับ… ถ้าน้องเจอโจทย์ที่บอกว่า “ฉันไม่ได้อยากได้แค่กรอบสี่เหลี่ยมทื่อๆ แต่อยากได้การระบายสีแยกวัตถุแนบไปตามขอบโค้งเว้าของมันแบบพิกเซลต่อพิกเซลล่ะ?” เตรียมตัวพบกับสุดยอดเทคนิค Semantic & Instance Segmentation (อย่าง Mask R-CNN หรือ U-Net) ในบทความตอนถัดไปได้เลยครับ สนุกแน่นอน!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p