ผ่าสมองส่วนลึก: เมื่อ LSTM มอบ 'ความทรงจำระยะยาว' ก้าวข้ามขีดจำกัดของ RNN

1. 🎯 ตอนที่ 31: ผ่าสมองส่วนลึก เมื่อ LSTM มอบความทรงจำระยะยาว
สวัสดีครับน้องๆ วิศวกร AI และนักพัฒนาทุกท่าน! จิบกาแฟให้ตื่นตัวกันสักนิด เพราะวันนี้เราจะมาเจาะลึกโครงสร้างระดับเซลล์ประสาทกันครับ
ในบทความที่แล้ว พี่ได้พาไปรู้จักกับ Recurrent Neural Networks (RNN) ในฐานะโมเดลที่เข้าใจ “กาลเวลา (Time)” แต่แหล่งข้อมูลระดับโลกได้ชี้ให้เห็นถึง “จุดอ่อนฉกรรจ์” ของสถาปัตยกรรม RNN พื้นฐาน นั่นคือเมื่อมันต้องเจอกับข้อมูลที่ยาวมากๆ มันจะเกิดอาการ “ความจำเสื่อม (Short-Term Memory)” ครับ! วันนี้เราจะมาดูกันว่าในบริบทที่กว้างขึ้นของวงการ AI สถาปัตยกรรมระดับตำนานอย่าง Long Short-Term Memory (LSTM) ก้าวเข้ามาอุดรอยรั่วนี้ และกลายเป็นรากฐานที่ทรงพลังที่สุดในยุคหนึ่งได้อย่างไร!
2. 📖 เปิดฉาก (The Hook)
ลองนึกภาพตามพี่นะครับ ให้น้องๆ อ่านประโยคยาวๆ สัก 1 หน้ากระดาษ แล้วให้ทายคำสุดท้ายของหน้านั้น ถ้าน้องเป็นมนุษย์ น้องจะจำ “ประธาน” หรือ “ใจความสำคัญ” ที่อยู่บรรทัดแรกสุดได้ แล้วเอามาเชื่อมโยงกับบริบทตอนท้าย
แต่ถ้าเป็น RNN ธรรมดาล่ะ? แหล่งข้อมูลเปรียบเทียบมันเหมือนกับ “ปลาความจำสั้นดอรี่ (Dory) ในหนัง Finding Nemo” เลยครับ! เพราะในขณะที่ทำการฝึกสอน (Training) แบบย้อนกลับข้ามเวลาที่เรียกว่า Backpropagation Through Time (BPTT) ค่าความผิดพลาด (Gradient) จะต้องถูกคูณด้วยน้ำหนัก (Weights) ตัวเดิมซ้ำๆ เป็นร้อยๆ รอบ ผลลัพธ์คือ สัญญาณ Gradient จะค่อยๆ หายไปจนกลายเป็นศูนย์ ปรากฏการณ์นี้เรียกว่า Vanishing Gradient ทำให้โมเดลลืมไปสนิทเลยว่าตอนต้นประโยคพูดเรื่องอะไรไว้!
จนกระทั่งในปี 1997 สองนักวิจัย Hochreiter และ Schmidhuber ได้นำเสนอ LSTM ที่เปรียบเสมือนการ “ผ่าตัดฝังชิปความจำ” ให้กับ AI เพื่อให้มันสามารถเลือกได้ว่า “เรื่องไหนควรจำไปนานๆ และเรื่องไหนควรทิ้งไป” สถาปัตยกรรมนี้กลายมาเป็นหัวใจสำคัญของงานแปลภาษา (Machine Translation), การบรรยายภาพ (Image Captioning), และวิเคราะห์วิดีโอ (Video Analysis) ครับ
3. 🧠 แก่นวิชา (Core Concepts)
ในมุมมองของสถาปัตยกรรมโครงข่ายประสาท แหล่งข้อมูลได้อธิบายการทำงานของ LSTM โดยแยกองค์ประกอบสำคัญที่ทำให้มันเหนือกว่า RNN ธรรมดาไว้ดังนี้ครับ:
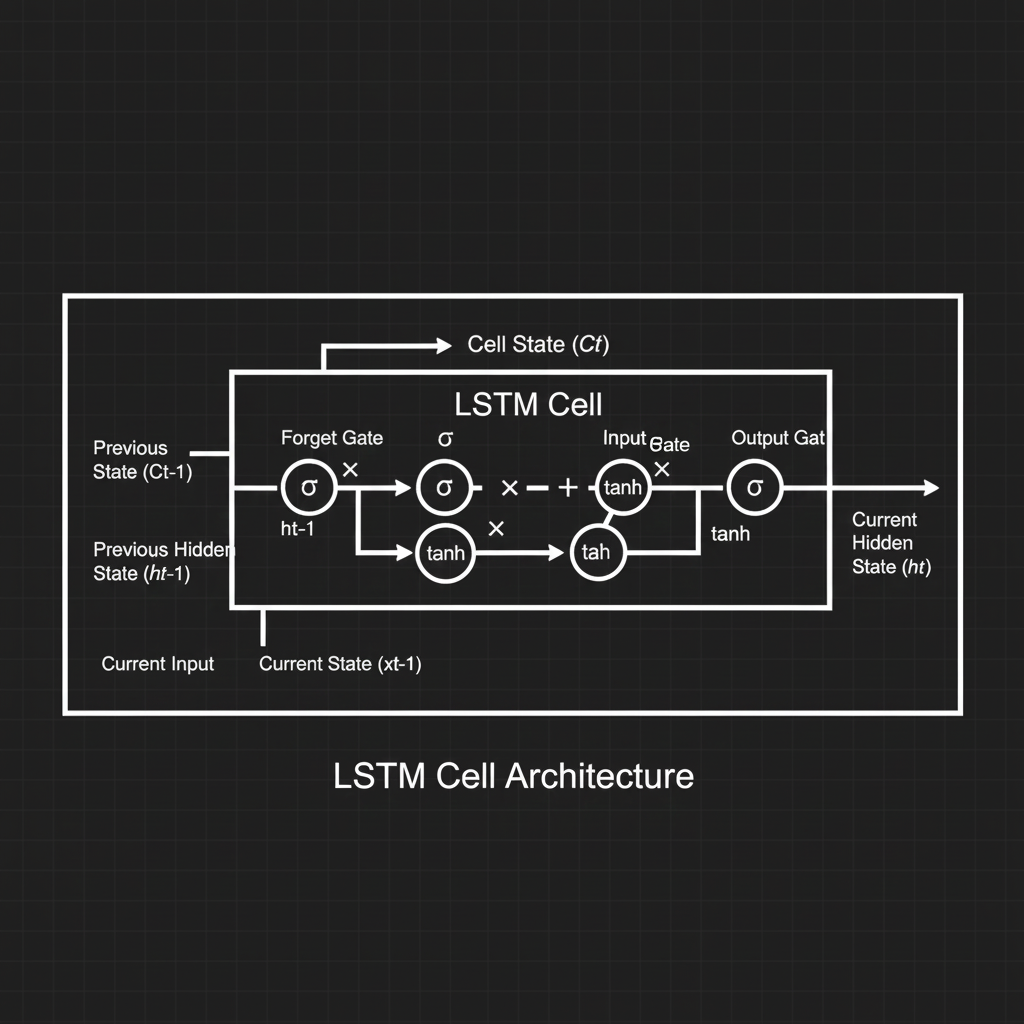
- 1. สายพานแห่งความจำ (The Cell State & Hidden State):
ในขณะที่ RNN พื้นฐานมีแค่สถานะเดียวคือ $h_t$ (Short-term state) แต่ LSTM ฉลาดกว่านั้นครับ มันแบ่งหน่วยความจำออกเป็น 2 เส้นทาง:
- Cell State ($c_t$): เป็นเสมือน “สายพานหลัก” ที่วิ่งทะลุผ่านเซลล์ไปตรงๆ (Long-term state) ข้อมูลบนสายพานนี้จะถูกแก้ไขน้อยมาก ทำให้ความจำระยะยาวไหลผ่านไปได้โดยไม่สูญหาย
- Hidden State ($h_t$): เป็นความจำระยะสั้นและเป็น Output ของเซลล์ในก้าวเวลานั้นๆ
- 2. กลไก Constant Error Carousel (CEC): นี่คือเวทมนตร์ทางคณิตศาสตร์ครับ! บนเส้นทางของ Cell State นั้น การไหลของข้อมูลและ Gradient จะใช้สมการที่มีสัดส่วนบวกทับลงไปตรงๆ (Identity mapping) คล้ายกับการเอาตัวเลขคูณ 1 ไปเรื่อยๆ การทำ CEC ทำให้ปัญหา Vanishing / Exploding Gradient หายไปเกือบหมดเกลี้ยง!
- 3. ประตูควบคุมทั้ง 3 (The 3 Gates):
การจะเอาของเข้าหรือออกจากสายพาน $c_t$ ต้องผ่าน “ประตู (Gates)” ซึ่งใช้ฟังก์ชัน Sigmoid ($\sigma$) ที่ให้ค่าตั้งแต่ 0 (ปิดประตูสนิท ทิ้งไป) ถึง 1 (เปิดประตูรับเต็มๆ) ประตูเหล่านี้คือหัวใจของความฉลาดครับ:
- Forget Gate ($f_t$): ดูข้อมูลอินพุตปัจจุบัน ($x_t$) และอดีต ($h_{t-1}$) แล้วตัดสินใจว่า “ความจำเก่าเรื่องไหนบนสายพาน $c_{t-1}$ ที่หมดประโยชน์และควร ‘ลบทิ้ง’ (Forget) บ้าง?”
- Input Gate ($i_t$): ตัดสินใจว่า “ข้อมูลใหม่ ($g_t$) จากอินพุตปัจจุบัน มีอะไรสำคัญพอที่จะ ‘บวกเพิ่ม’ เข้าไปบนสายพานความจำไหม?”
- Output Gate ($o_t$): เมื่อได้ความจำใหม่บนสายพานแล้ว ประตูนี้จะตัดสินใจว่า “จะคัดกรองเอาส่วนไหนของสายพาน ($c_t$) ออกไปเป็นผลลัพธ์ ($h_t$) ให้เลเยอร์ถัดไปดูดี?”
สมการคณิตศาสตร์ที่ขับเคลื่อนประตูและสายพานของ LSTM คือความงดงามของการออกแบบสถาปัตยกรรมครับ:
$$ c_t = (f_t \otimes c_{t-1}) + (i_t \otimes g_t) $$ (โดยที่ $\otimes$ คือการคูณทีละตำแหน่ง Element-wise multiplication)
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในอดีต การเขียนสมการ LSTM จากศูนย์เป็นเรื่องที่ปวดหัวมาก แต่ใน Keras ยุคปัจจุบัน น้องๆ สามารถเปลี่ยนโครงข่ายความจำสั้นเป็น “ความจำยาว” ได้ด้วยการเปลี่ยนชื่อคลาสแค่คำเดียวครับ! ลองดูตัวอย่างนี้:
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential()
# -------------------------------------------------------------
# 📌 สถาปัตยกรรม LSTM (แทนที่ SimpleRNN แบบดั้งเดิม)
# - units=128: ขนาดของหน่วยความจำ (ความกว้างของสายพาน Cell State และ Hidden State)
# - return_sequences=True: สั่งให้คาย Output (h_t) ออกมาทุกๆ ก้าวเวลา
# เพื่อส่งต่อให้ LSTM ชั้นถัดไป (สร้าง Deep LSTM)
# -------------------------------------------------------------
model.add(layers.LSTM(units=128, return_sequences=True, input_shape=(None, 10)))
# 📌 ชั้นที่ 2 ของ LSTM
# ค่าเริ่มต้น return_sequences=False มันจะประมวลผลจนจบประโยค
# แล้วคายเฉพาะ "บทสรุปตอนท้าย" ออกมาเป็น Vector ก้อนเดียว
model.add(layers.LSTM(units=64))
# -------------------------------------------------------------
# 📌 ส่งเข้า Fully Connected Layer เพื่อตัดสินใจ
# -------------------------------------------------------------
model.add(layers.Dense(32, activation='relu'))
# สมมติใช้ทำ Sentiment Analysis (ทายอารมณ์บวก/ลบ)
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()คอมเมนต์: สังเกตไหมครับ? แค่เราใช้ layers.LSTM กลไกการรัน Backpropagation ของ TensorFlow ก็จะจัดการเรื่อง 3 ประตู และ CEC ให้เราทั้งหมดภายในกล่องดำ (Black box) เรียบร้อยแล้ว!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในระดับวิศวกรที่นำ LSTM ไปประยุกต์ใช้งานจริง มีความลับเชิงโครงสร้างที่ซ่อนอยู่อีกครับ:
- Peephole Connections: ในปี 2000 Felix Gers และ Jürgen Schmidhuber ได้ปรับปรุง LSTM โดยเจาะช่องให้เกตต่างๆ (Gates) สามารถ “แอบดู” สถานะสายพาน $c_{t-1}$ ได้ด้วย แทนที่จะดูแค่ $x_t$ กับ $h_{t-1}$ อย่างเดียว ซึ่งช่วยให้โมเดลทำงานกับจังหวะเวลา (Timing) ที่แม่นยำขึ้นได้ (ใน Keras ทดลองใช้ท่านี้ผ่าน
tf.keras.experimental.PeepholeLSTMCellได้ครับ) - พารามิเตอร์ที่มหาศาล: ถ้าเทียบกับ Simple RNN แล้ว LSTM ควบคุมเส้นทางเยอะมาก ส่งผลให้ มีพารามิเตอร์ (Weights) มากกว่า RNN ธรรมดาถึง 4 เท่า! (เพราะมี 3 ประตู + 1 กลไกรับอินพุต) ทำให้มันเทรนช้ากว่าและกินแรมมากกว่าอย่างชัดเจน
- ทางเลือกที่เบากว่า (GRU): หากโปรเจกต์ของน้องมีข้อจำกัดเรื่องเวลาและแรม แหล่งข้อมูลแนะนำให้รู้จักกับ GRU (Gated Recurrent Unit) ซึ่งเป็นญาติผู้น้องของ LSTM ครับ GRU รวมเอา Cell state กับ Hidden state เข้าด้วยกัน ยุบประตูรวบกันให้เหลือพารามิเตอร์น้อยลง (เร็วกว่า) แต่ทำงานได้ทรงพลังใกล้เคียงกันกับ LSTM จนเป็นที่นิยมมากๆ ในปัจจุบัน!
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว LSTM (Long Short-Term Memory) คือฮีโร่ที่เข้ามาทลายกำแพงความจำกัดของโครงข่ายประสาทแบบ Recurrent อย่างแท้จริงครับ
ด้วยกลไกอัจฉริยะที่แบ่งข้อมูลเป็น สายพานความจำระยะยาว (Cell state) และการใช้ ประตูควบคุม (Gates) ทำให้ AI ไม่เพียงแต่เข้าใจบริบทแบบเรียงลำดับเวลา (Sequential data) ได้เท่านั้น แต่มันยังสามารถแก้ปัญหา Gradient จางหาย (Vanishing Gradient) และรักษาความทรงจำจากการเริ่มต้นประโยคไปจนถึงท้ายประโยคยาวๆ ได้อย่างมีประสิทธิภาพ
แต่ความฝันในการประมวลผลภาษายังไม่จบแค่นี้ครับ! เมื่อเราเอา LSTM มาต่อกัน 2 ก้อน (ก้อนหนึ่งอ่านข้อมูล ก้อนหนึ่งแปลภาษา) มันจะเกิดสถาปัตยกรรมระดับโลกที่เรียกว่า Encoder-Decoder ขึ้นมา ในตอนถัดไป พี่จะพาน้องๆ ไปดูว่า AI เริ่มทำ Machine Translation แบบ Google Translate ยุคแรกๆ ได้อย่างไร ห้ามพลาดนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p