เจาะเวลาหาอดีต: รู้จัก RNN โครงข่ายประสาทเทียมที่มี 'ความทรงจำ' สำหรับข้อมูลต่อเนื่อง

1. 🎯 ตอนที่ 30: เจาะเวลาหาอดีต รู้จัก RNN โครงข่ายที่มี “ความทรงจำ”
สวัสดีครับน้องๆ วิศวกรและนักพัฒนา AI ทุกท่าน! กาแฟในมือพร้อมแล้วใช่ไหมครับ? ตลอดหลายบทความที่ผ่านมา เราคุยกันเรื่องสถาปัตยกรรมระดับเทพอย่าง CNN ไม่ว่าจะเป็น ResNet, Inception หรือ SqueezeNet ซึ่งถูกออกแบบมาเพื่อเป็น “ดวงตา” ในการสกัดฟีเจอร์จากภาพ
แต่ข้อจำกัดอย่างหนึ่งของโมเดลกลุ่ม Feedforward Networks (อย่าง MLP หรือ CNN) คือพวกมันมีพฤติกรรมเหมือนคน “ความจำเสื่อม” ครับ! คือมันรับข้อมูลเข้าไปประมวลผลทางเดียว แล้วคายคำตอบออกมา (ไม่มีการวนลูปกลับ) พอมันเห็นภาพใหม่ มันก็ลืมภาพเก่าไปเสียสนิท
แต่ในโลกความจริง ข้อมูลหลายอย่างไม่ได้มาเป็นภาพนิ่งเดี่ยวๆ ครับ ลองนึกถึง “ราคาหุ้น”, “วิดีโอวงจรปิด”, หรือ “ประโยคสนทนา” ข้อมูลเหล่านี้เป็น ข้อมูลเชิงลำดับ (Sequential Data) ที่ความหมายของสิ่งที่เราเห็นใน “วินาทีนี้” มักจะขึ้นอยู่กับสิ่งที่เกิดขึ้นใน “วินาทีที่แล้ว” เสมอ และนี่คือจุดที่สถาปัตยกรรม Recurrent Neural Networks (RNNs) ก้าวเข้ามาพลิกโฉมวงการครับ!
2. 📖 เปิดฉาก (The Hook)
สมมติว่าพี่ให้น้องทายคำที่หายไปในประโยค: “วันนี้ฝนตกหนัก ฉันเลยต้องกาง… “ น้องๆ ตอบได้ทันทีว่า “ร่ม” ใช่ไหมครับ? ที่น้องตอบได้ เพราะสมองของน้องจำคำว่า “ฝนตกหนัก” ที่อยู่ต้นประโยคได้
แต่ถ้าเราเอาประโยคนี้ไปป้อนให้ CNN หรือ MLP ทั่วไป มันจะไม่สามารถจับบริบทข้ามเวลาได้ดีนัก เพราะมันถูกออกแบบมาให้รับข้อมูลที่มีขนาดตายตัว (Fixed-sized inputs) และไม่มีกลไกในการเก็บ “สถานะ (State)” ของอดีตเอาไว้เลย
นักวิจัยจึงได้คิดค้น RNN ขึ้นมา โดยเติม “เส้นทางลัด” ให้เซลล์ประสาทสามารถส่งข้อมูลผลลัพธ์ของตัวเอง วนลูปกลับมาเป็นอินพุตของตัวเองในก้าวเวลาถัดไปได้ (Backward connections หรือ Cycles) กลไกง่ายๆ แค่นี้แหละครับ ที่ทำให้ AI เริ่มมีสิ่งที่เรียกว่า “ความทรงจำ (Memory)”!
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทที่กว้างขึ้นของสถาปัตยกรรมโครงข่ายประสาท แหล่งข้อมูลระดับโลกได้อธิบายสถาปัตยกรรมและพฤติกรรมของ RNN ไว้ดังนี้ครับ:
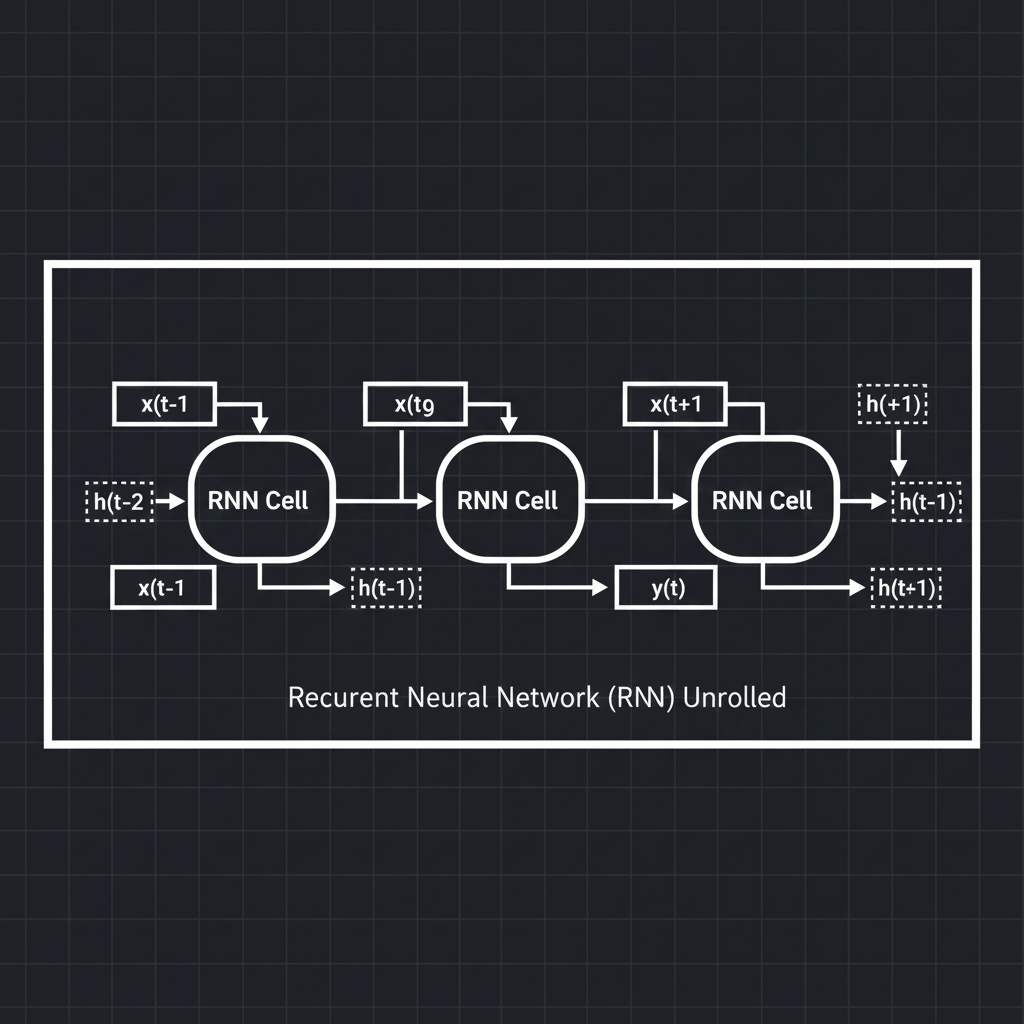
- 1. สถาปัตยกรรมแบบมีลูป (The Recurrent Loop): ในโครงข่ายแบบ Feedforward ข้อมูลจะไหลจากซ้ายไปขวาทางเดียว แต่ใน RNN ที่ก้าวเวลา $t$ (Time step $t$) นิวรอนจะไม่ได้รับแค่อินพุตปัจจุบัน $x(t)$ เท่านั้น แต่มันยังรับ สถานะซ่อนเร้นจากอดีต (Hidden State) $h(t-1)$ เข้ามาคำนวณร่วมกันด้วย
- 2. การคลี่ออกตามเวลา (Unrolling in Time): เพื่อที่จะทำความเข้าใจและใช้คณิตศาสตร์คำนวณได้ง่ายขึ้น เรามักจะวาดภาพ RNN แบบ “คลี่ออกตามแกนเวลา” (Unrolled through time) ซึ่งพอมองแบบนี้ RNN จะหน้าตาเหมือน Feedforward Network ที่มีความลึกเท่ากับจำนวนความยาวของข้อมูล
- 3. เวทมนตร์ของการแชร์น้ำหนัก (Weight Sharing across Time): จุดที่เจ๋งมากคือ CNN แชร์ค่าน้ำหนัก (Weights) ทั่วทั้ง “พื้นที่ (Space)” ของรูปภาพเพื่อให้จับวัตถุได้ไม่ว่ามันจะอยู่มุมไหนของภาพ ส่วน RNN นั้น แชร์ค่าน้ำหนักข้าม “ก้าวเวลา (Time)”! นั่นหมายความว่า เลเยอร์ที่ถูกคลี่ออกในข้อ 2 จะใช้ชุดน้ำหนัก (Matrices) ชุดเดียวกันเป๊ะ ในทุกๆ วินาที ซึ่งช่วยประหยัดพารามิเตอร์และทำให้มันจับแพทเทิร์นได้ไม่ว่าแพทเทิร์นนั้นจะเกิดตอนต้นหรือตอนท้ายของซีเควนซ์
- 4. ความยืดหยุ่นในการรับส่งข้อมูล (Input/Output Sequences):
RNN สามารถปรับโครงสร้างได้หลากหลายมาก เช่น:
- Sequence-to-Sequence: รับข้อมูลยาวๆ แล้วคายข้อมูลยาวๆ (เช่น เครื่องแปลภาษา หรือ พยากรณ์หุ้น)
- Sequence-to-Vector: รับข้อมูลยาวๆ แล้วคายคำตอบเดียว (เช่น อ่านรีวิวหนังแล้ววิเคราะห์ว่าดีหรือแย่)
- Vector-to-Sequence: รับข้อมูลเดียว แล้วคายออกมาเป็นซีเควนซ์ (เช่น ป้อนรูปภาพ 1 รูป แล้วให้ AI แต่งประโยคอธิบายภาพ Image Captioning)
สมการคณิตศาสตร์ที่อธิบายการทำงานของชั้น Recurrent แบบพื้นฐาน (มีฟังก์ชันกระตุ้นเป็น tanh) คือ:
$$ h(t) = \tanh(W x(t) + U h(t-1) + b) $$
(เมื่อ $W$ คือน้ำหนักของอินพุตปัจจุบัน, $U$ คือน้ำหนักของความจำอดีต, และ $b$ คือค่า Bias)
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในไลบรารีอย่าง Keras การสร้างโมเดล RNN นั้นง่ายจนน่าตกใจครับ ลองดูตัวอย่างการสร้างโมเดล SimpleRNN สำหรับรับข้อมูลที่มีความยาวไม่จำกัด (เช่น อนุกรมเวลา) กันครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
# สร้างโมเดลแบบ Sequential
model = models.Sequential()
# -------------------------------------------------------------
# 📌 เพิ่มชั้น Recurrent (SimpleRNN)
# - units=128: จำนวนนิวรอนในชั้นนี้ (ขนาดของสมอง/ความจำ)
# - input_shape=(None, 2): ข้อมูลเข้ามีก้าวเวลาไม่จำกัด (None) และแต่ละก้าวมี 2 ตัวแปร
# - return_sequences=True: สั่งให้คาย Output ออกมา "ทุกๆ ก้าวเวลา"
# (จำเป็นมากถ้าเราจะต่อกับ RNN ชั้นถัดไป!)
# -------------------------------------------------------------
model.add(layers.SimpleRNN(128, activation='tanh', return_sequences=True, input_shape=(None, 2)))
# สามารถต่อ RNN เข้าด้วยกันเป็น Deep RNN ได้
model.add(layers.SimpleRNN(64, activation='tanh', return_sequences=False))
# -------------------------------------------------------------
# 📌 ชั้นตัดสินใจ (Output Layer)
# คายผลลัพธ์สุดท้ายออกมา 1 ตัว (เช่น ทายราคาหุ้นวันพรุ่งนี้)
# -------------------------------------------------------------
model.add(layers.Dense(1))
model.compile(optimizer='adam', loss='mse')
model.summary()คอมเมนต์: สังเกตพารามิเตอร์ return_sequences นะครับ ถ้าน้องๆ ตั้งเป็น False (ซึ่งเป็นค่า Default) มันจะทำตัวเป็น Sequence-to-Vector (สนใจแค่คำตอบตอนจบ) แต่ถ้าตั้งเป็น True มันจะส่งออกค่า $h(t)$ ในทุกๆ เวลาครับ
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ถึงแม้คอนเซปต์ของ RNN จะดูเท่มาก แต่ในทางปฏิบัตินั้น “ดุเดือด” มากครับ พี่มีเรื่องจากหน้างานมาเตือนกัน:
- BPTT (Backpropagation Through Time): เวลาเราจะอัปเดตน้ำหนักของโมเดล เราต้องใช้กระบวนการ BPTT ซึ่งเป็นการย้อน Error กลับไปตามเส้นทางของกาลเวลา ลองคิดดูว่าถ้าประโยคของน้องยาว 1,000 คำ โมเดลที่ถูกคลี่ออกก็จะมีความลึกถึง 1,000 ชั้น!
- คำสาปของความทรงจำสั้น (The Short-Term Memory Problem): เพราะความลึกมหาศาลจากการทำ BPTT ผสมกับการคูณด้วยเมทริกซ์น้ำหนักตัวเดิมซ้ำๆ ทำให้เกิดปัญหาโลกแตกที่เรียกว่า Vanishing / Exploding Gradients (ความชันจางหายหรือระเบิด) ซึ่งทำให้ RNN แบบธรรมดา “ลืม” สิ่งที่เกิดขึ้นในช่วงต้นของข้อมูลไปเสียสนิท (เหมือนปลาความจำสั้น Dory ในเรื่อง Finding Nemo เลยครับ!)
- ทางออกด้วย LSTM และ GRU: ด้วยข้อจำกัดของ Simple RNN วิศวกรยุคปัจจุบันจึงแทบไม่ใช้มันแล้วครับ! แต่เราเปลี่ยนไปใช้เซลล์ที่อัปเกรดแล้วอย่าง LSTM (Long Short-Term Memory) หรือ GRU (Gated Recurrent Unit) แทน ซึ่งภายในเซลล์พวกนี้จะมี “ประตู (Gates)” คอยทำหน้าที่เลือกว่า “ข้อมูลไหนควรจำ” และ “ข้อมูลไหนควรลืม” ทำให้มันสามารถแก้ปัญหา Vanishing Gradient และจำข้อมูลได้ยาวนานขึ้นอย่างมากครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Recurrent Neural Networks (RNN) คือสถาปัตยกรรมที่เข้ามาเติมเต็มสิ่งที่ CNN และ MLP ขาดหายไป นั่นคือการทำความเข้าใจกับบริบทของ “เวลาและลำดับ (Time & Sequence)” ด้วยกลไกการส่งสถานะซ่อนเร้นวนลูปกลับมาให้ตัวเอง ทำให้มันเป็นรากฐานสำคัญของงาน Natural Language Processing (NLP), การแปลภาษา, และการวิเคราะห์ Time Series
แต่อย่างที่พี่เกริ่นไปครับ โครงสร้างภายในของมันยังมีปัญหาเรื่องลืมของเก่า ในบทความหน้า พี่จะพาน้องๆ มุดเข้าไปดูข้างในเซลล์ระดับตำนานอย่าง LSTM และ GRU ว่า “ประตูเวทมนตร์” ที่ช่วยให้มันมีความทรงจำระยะยาวนั้น ทำงานอย่างไร… และแอบสปอยล์นิดนึงว่า ยุคนี้มีโครงสร้างที่ทรงพลังกว่า RNN มาก นั่นคือ Transformer รอติดตามกันให้ดีนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p