ผ่าสถาปัตยกรรม SqueezeNet: จิ๋วแต่แจ๋ว บีบอัด AI ให้เล็กลง 50 เท่า โดยที่ความแม่นยำไม่ลด! (Popular Models)
1. 🎯 ตอนที่ 28: ผ่าสถาปัตยกรรม SqueezeNet จิ๋วแต่แจ๋วระดับตำนาน
สวัสดีครับน้องๆ วิศวกรสาย Vision ทุกคน! ชงกาแฟเข้มๆ แล้วมานั่งคุยกันต่อครับ ในช่วงที่ผ่านมาเราได้ทำความรู้จักกับ “โมเดลยอดนิยม (Popular Models)” รุ่นเดอะอย่าง AlexNet, VGGNet และ ResNet กันไปแล้ว ซึ่งเป้าหมายของโมเดลเหล่านั้นคือการแข่งกันทำความแม่นยำให้สูงที่สุด โดยแลกมากับขนาดไฟล์ที่บวมขึ้นเรื่อยๆ (VGG16 ปาเข้าไปกว่า 500 MB!)
แต่ในโลกของวิศวกรรมหน้างานจริง ถ้าน้องๆ ต้องเอา AI ไปรันบนสมาร์ทโฟน กล้องวงจรปิด แผงวงจรฝังตัว (Embedded Systems) หรือส่งโมเดลอัปเดตผ่านระบบ Cloud ตลอดเวลา การใช้โมเดลยักษ์พวกนั้นคงทำให้ระบบอืดจนค้างไปเลยใช่ไหมครับ?
นี่จึงเป็นที่มาของความพยายามในการสร้าง “โมเดลฉบับกระเป๋า” และในปี 2016 ทีมนักวิจัย (Iandola et al.) ได้เปิดตัว SqueezeNet โมเดลที่ก้าวเข้ามาพลิกวงการด้วยคำเคลมสุดโหดที่ว่า: “เราสามารถทำความแม่นยำได้เท่ากับ AlexNet แต่ออกแบบให้มีจำนวนพารามิเตอร์น้อยลงถึง 50 เท่า! และขนาดไฟล์เล็กไม่ถึง 1 MB!” วันนี้พี่จะพาไปเจาะลึกเวทมนตร์เบื้องหลังความจิ๋วแต่แจ๋วของมันกันครับ!
2. 📖 เปิดฉาก (The Hook)
ลองนึกภาพตามพี่นะครับ สมมติว่าน้องกำลังจัดทีมสืบสวนคดี (Feature Extraction) ในโมเดลยุคเก่าอย่าง VGGNet เหมือนน้องจ้างนักสืบ 100 คน ทุกคนถือแว่นขยายขนาด $3 \times 3$ ไปลงพื้นที่พร้อมกันหมด… แน่นอนว่างานเสร็จไว ได้ข้อมูลครบ แต่ค่าจ้าง (Resource & Parameters) มหาศาลมาก!
SqueezeNet มองต่างออกไปครับ เขาบอกว่า “ก่อนจะส่งนักสืบลงพื้นที่ ทำไมเราไม่ส่ง ‘หัวหน้าทีม’ แค่ไม่กี่คน (แว่นขยาย $1 \times 1$) ไปบีบอัดและสรุปคดีก่อนล่ะ? พอบีบข้อมูลให้เล็กลงแล้ว ค่อยส่งต่อให้นักสืบกลุ่มเล็กๆ (แว่นขยาย $1 \times 1$ ผสม $3 \times 3$) ไปขยายผลต่อ”
กระบวนการ “บีบ (Squeeze)” แล้วค่อย “ขยาย (Expand)” นี่แหละครับ คือหัวใจสำคัญที่ทำให้ SqueezeNet สามารถลดการคำนวณลงได้อย่างน่าเหลือเชื่อ โดยที่ยังคงความสามารถในการสกัดจุดเด่นของภาพ (Features) ไว้ได้อย่างครบถ้วน!
3. 🧠 แก่นวิชา (Core Concepts)
ในจักรวาลของโมเดลยอดนิยม (Popular Models) แหล่งข้อมูลระดับโลกได้จัดให้ SqueezeNet เป็นต้นแบบของการทำ Model Compression โดยมีโครงสร้างและกลยุทธ์หลักๆ ดังนี้ครับ:
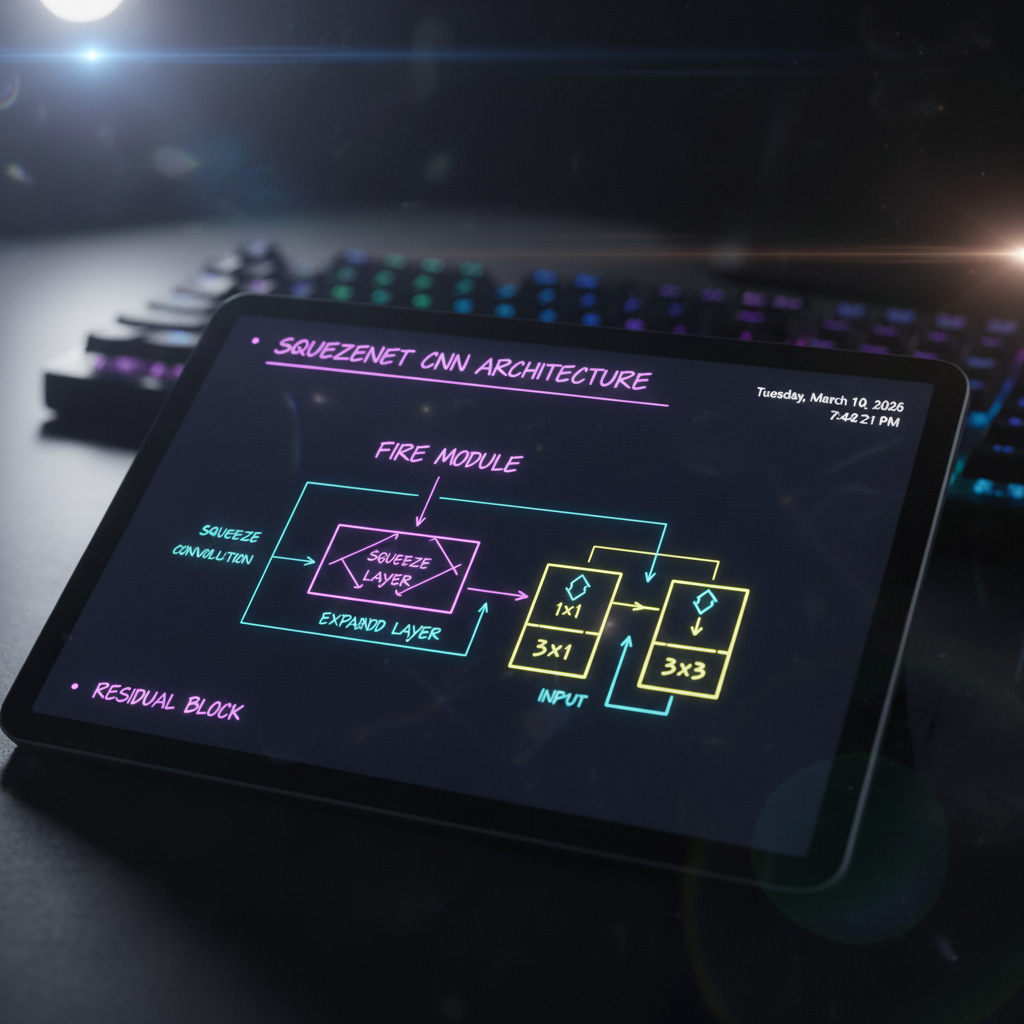
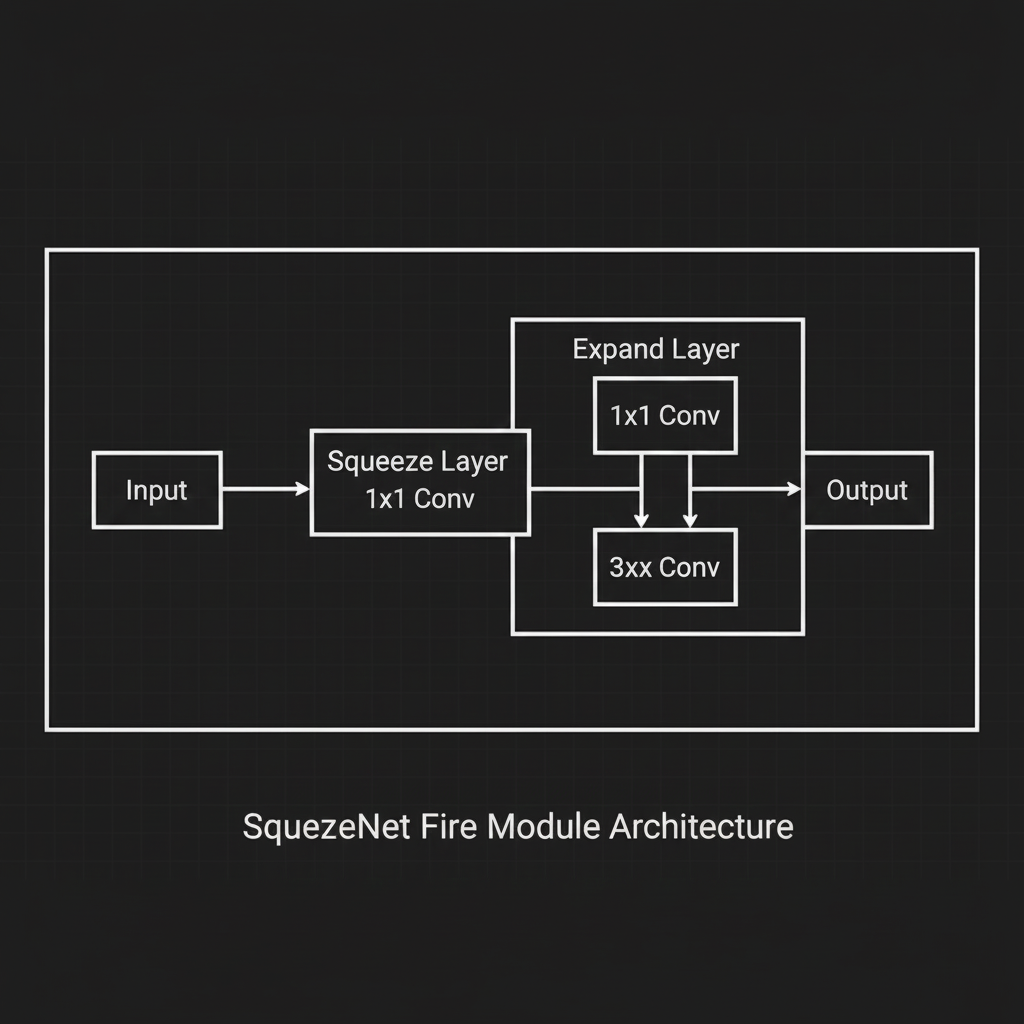
- 1. The Fire Module (บล็อกแห่งเปลวเพลิง):
แทนที่จะใช้ Convolutional Layer แบบทื่อๆ ซ้อนกัน SqueezeNet สร้างบล็อกที่เรียกว่า Fire Module ขึ้นมา โดยภายในประกอบด้วย 2 ขั้นตอนย่อย:
- Squeeze Layer: ใช้ตัวกรอง (Filters) ขนาด $1 \times 1$ เท่านั้น หน้าที่ของมันคือการ “บีบอัดมิติความลึก (Channels)” ของข้อมูลที่เข้ามาให้บางลง (คล้ายๆ คอขวด Bottleneck)
- Expand Layer: รับข้อมูลที่บางลงแล้ว มาเข้าตัวกรองขนาด $1 \times 1$ และ $3 \times 3$ แบบขนานกัน (Parallel) แล้วค่อยนำผลลัพธ์มาต่อกัน (Concatenate) ในตอนท้าย
- 2. ลดภาระพารามิเตอร์ด้วย $1 \times 1$: รู้หรือไม่ครับว่า ตัวกรองขนาด $3 \times 3$ กินพารามิเตอร์มากกว่า $1 \times 1$ ถึง 9 เท่า! SqueezeNet จึงพยายามแทนที่ $3 \times 3$ ด้วย $1 \times 1$ ให้มากที่สุด และในจุดที่จำเป็นต้องใช้ $3 \times 3$ จริงๆ (ใน Expand layer) ข้อมูลก็ถูกบีบให้บางลงจาก Squeeze layer เรียบร้อยแล้ว ทำให้คำนวณคณิตศาสตร์น้อยลงมหาศาล
- 3. โยน Fully Connected ทิ้งไป (Late Downsampling & No FC): เช่นเดียวกับ ResNet และ GoogLeNet ครับ SqueezeNet เลือกที่จะตัดชั้น Fully Connected (Dense Layers) อันหนักอึ้งที่ท้ายเน็ตเวิร์กทิ้งไป แล้วเปลี่ยนมาใช้ Global Average Pooling แทน ช่วยลดจำนวนพารามิเตอร์ลงไปได้อีกหลายล้านตัว! นอกจากนี้ยังใช้วิธีลดขนาดภาพ (Downsampling) ให้ช้าลง เพื่อให้ Feature Maps มีขนาดใหญ่และเก็บรายละเอียดได้นานที่สุด
- 4. เล็กระดับ < 1MB: โครงสร้างสถาปัตยกรรมแบบนี้ทำให้โมเดลมีขนาดเริ่มต้นแค่ประมาณ 4.9 MB และเมื่อใช้เทคนิคบีบอัดข้อมูลแบบ Deep Compression (ลด Precision ของตัวเลข) ไฟล์โมเดลสามารถเล็กลงไปได้เหลือน้อยกว่า 0.5 MB เลยทีเดียวครับ!
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
น่าเสียดายที่ใน Keras Core Library มาตรฐาน ไม่ได้มี SqueezeNet มาให้เรียกใช้ตรงๆ เหมือนพวก VGG16 หรือ ResNet50 ครับ แต่ด้วย Functional API ของ Keras เราสามารถเขียน Fire Module ขึ้นมาเองได้ง่ายๆ ตามเปเปอร์ต้นฉบับเลยครับ ลองดูโค้ดนี้:
import tensorflow as tf
from tensorflow.keras import layers, models
# -------------------------------------------------------------
# 📌 ร่ายมนต์สร้าง Fire Module (หัวใจของ SqueezeNet)
# -------------------------------------------------------------
def fire_module(x, squeeze_filters, expand_filters):
# 1. Squeeze Phase: บีบอัดมิติความลึกด้วย 1x1 Convolution
squeezed = layers.Conv2D(squeeze_filters, (1, 1), activation='relu', padding='valid')(x)
# 2. Expand Phase: ขยายข้อมูลด้วย 1x1 และ 3x3 แบบขนานกัน
expand_1x1 = layers.Conv2D(expand_filters, (1, 1), activation='relu', padding='valid')(squeezed)
expand_3x3 = layers.Conv2D(expand_filters, (3, 3), activation='relu', padding='same')(squeezed)
# 3. จับผลลัพธ์มาต่อกัน (Concatenation) ตามแนวแกนความลึก (axis=-1)
output = layers.concatenate([expand_1x1, expand_3x3], axis=-1)
return output
# -------------------------------------------------------------
# 📌 ลองเอา Fire Module มาต่อเป็นโครงสร้างแบบง่ายๆ
# -------------------------------------------------------------
input_img = layers.Input(shape=(224, 224, 3))
# เลเยอร์แรกมักจะเป็น Conv ปกติเพื่อรับภาพเข้า
x = layers.Conv2D(96, (7, 7), strides=(2, 2), activation='relu')(input_img)
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
# เรียกใช้ Fire Module! (บีบลงเหลือ 16 filters, แล้วขยายเป็น 64)
x = fire_module(x, squeeze_filters=16, expand_filters=64)
x = fire_module(x, squeeze_filters=16, expand_filters=64)
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
# ใช้ Global Average Pooling ทิ้งท้ายแทนการใช้ Flatten + Dense
x = layers.GlobalAveragePooling2D()(x)
output = layers.Dense(10, activation='softmax')(x) # สมมติแยกชิ้นงาน 10 คลาส
model = models.Model(inputs=input_img, outputs=output)
model.summary()คอมเมนต์: สังเกตบล็อก fire_module นะครับ มันแสดงให้เห็นปรัชญาของ SqueezeNet ได้อย่างชัดเจน คือการใช้ $1 \times 1$ เป็น “คอขวด (Bottleneck)” บีบอัดมิติก่อน แล้วค่อยแยกสายไปคำนวณ วิธีนี้รีดประสิทธิภาพ (Efficiency) ออกมาได้สุดๆ ครับ!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
สำหรับวิศวกรที่กำลังลังเลว่าจะหยิบ SqueezeNet ไปใช้หน้างานดีไหม พี่มีข้อสังเกตและ Best Practices มาฝากครับ:
- SqueezeNet vs. MobileNet: SqueezeNet เกิดในยุคปี 2016 ซึ่งเป็นช่วงเริ่มต้นของการทำโมเดลเล็กครับ แต่หลังจากนั้นไม่นาน (ปี 2017) Google ก็เปิดตัว MobileNet ที่ใช้เทคนิค Depthwise Separable Convolutions ซึ่งทรงประสิทธิภาพและทำงานบนมือถือได้เร็วกว่า SqueezeNet ในหลายๆ กรณี ปัจจุบันนี้ถ้าต้องเลือกระหว่าง 2 ตัวนี้ วิศวกรส่วนใหญ่มักจะเอนเอียงไปทางกลุ่มตระกูล MobileNetV2 หรือ V3 มากกว่าครับ
- เหมาะสุดๆ กับ Edge Computing สายแข็ง: จุดแข็งที่สุดของ SqueezeNet ไม่ใช่เรื่องความเร็ว (Latency) แต่เป็นเรื่อง “ขนาดไฟล์ที่โคตรเล็ก (Footprint)” ครับ! ถ้าน้องทำอุปกรณ์ IoT หรือ FPGA ที่มีหน่วยความจำบนบอร์ดจำกัดมากๆ (เช่น มี Flash memory แค่ไม่กี่ MB) การยัด SqueezeNet ลงไปคือคำตอบที่ตรงจุดที่สุดครับ!
- Transfer Learning ยังคงเวิร์ก:
ถึงแม้ Keras จะไม่มีโมเดลนี้ติดมาให้ แต่ใน Community (เช่น บน GitHub หรือ PyTorch
torchvision) มี SqueezeNet ที่ Pre-trained กับ ImageNet มาให้โหลดเพียบครับ น้องสามารถตัดหัวมันออกแล้วนำมันมาเป็น Feature Extractor ยัดเข้าโมเดลตรวจจับวัตถุ (Object Detection) แบบเบาๆ ได้สบายมาก
6. 🏁 บทสรุป (To be continued…)
สรุปส่งท้ายครับ SqueezeNet คือจุดเปลี่ยนสำคัญที่พิสูจน์ให้โลก AI เห็นว่า “ความแม่นยำสูง ไม่จำเป็นต้องมาพร้อมกับโมเดลที่อ้วนเสมอไป!” ด้วยการใช้ชั้น Fire Module ที่ผสานกลยุทธ์การบีบ (Squeeze) ด้วยคอขวด $1 \times 1$ และการขยาย (Expand) แบบขนาน ทำให้มันสามารถสกัด Feature ได้เทียบเท่า AlexNet แต่หดขนาดไฟล์ลงได้ถึง 50 เท่า!
ในโลกของ Popular Models เราได้เห็นวิวัฒนาการตั้งแต่การทำให้ลึกขึ้น (VGG, ResNet), ทำงานขนานกัน (Inception), มาจนถึงการทำให้เล็กลง (SqueezeNet, MobileNet) ถือว่าตอนนี้คลังแสงอาวุธสำหรับงาน Image Classification ของน้องๆ จัดเต็มแล้วครับ!
ในซีรีส์บทความถัดๆ ไป พี่จะพาน้องๆ ก้าวข้ามจากการแค่บอกว่า “ภาพนี้คืออะไร” ไปสู่การตีกรอบสี่เหลี่ยมหาตำแหน่งเป้าหมาย หรือ Object Detection กันเต็มรูปแบบครับ (พวก YOLO, SSD, Faster R-CNN มาแน่!) ฝากติดตามด้วยนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p