ผ่าสถาปัตยกรรม ResNet-50: ทลายกำแพงความลึก ด้วยเวทมนตร์แห่ง Skip Connection (Popular Models)

1. 🎯 ตอนที่ 27: ผ่าสถาปัตยกรรม ResNet-50 ทลายกำแพงความลึก
สวัสดีครับน้องๆ วิศวกรสาย Vision ทุกท่าน! เติมกาแฟให้เต็มแก้วแล้วมาลุยกันต่อครับ ในบทความที่ผ่านๆ มา เราได้เห็นวิวัฒนาการของ “โมเดลยอดนิยม (Popular Models)” อย่าง VGGNet ที่เน้นความเป็นระเบียบ และ Inception (GoogLeNet) ที่เน้นการทำงานแบบขนานกันไปแล้ว
แต่ในจักรวาลของ Deep Learning ทุกคนต่างรู้ดีว่า “ยิ่งโมเดลมีความลึก (Deeper) มันยิ่งฉลาดและเรียนรู้ฟีเจอร์ที่ซับซ้อนได้ดีขึ้น” ทว่าเมื่อนักวิจัยพยายามซ้อนเลเยอร์ให้ลึกเกิน 20-30 ชั้น โมเดลกลับ “โง่ลง” ซะงั้น! จนกระทั่งในปี 2015 ทีมนักวิจัยจาก Microsoft Research ได้เปิดตัวสถาปัตยกรรม ResNet (Residual Neural Network) ที่มาพร้อมกับความลึกระดับ 50 ไปจนถึง 152 ชั้น! แถมยังคว้าแชมป์โลกเวที ILSVRC 2015 ไปด้วย Error rate ที่ต่ำเพียง 3.57%
วันนี้พี่จะพาไปเจาะลึกว่า ในบริบทของโมเดลยอดฮิตระดับตำนาน ResNet-50 เข้ามาแก้ปัญหาความลึกนี้ได้อย่างไร และทำไมมันถึงกลายมาเป็น “กระดูกสันหลัง (Backbone)” มาตรฐานอุตสาหกรรมที่เราใช้กันจนถึงทุกวันนี้ครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่า การส่งข้อมูลความผิดพลาด (Error) กลับไปปรับปรุงน้ำหนักโมเดล (Backpropagation) เหมือนกับการกระซิบส่งต่อข้อความในแถวเรียงหนึ่งที่มีคนยืนอยู่ 50 คนดูสิครับ
เมื่อคนที่ 50 (เลเยอร์สุดท้าย) กระซิบบอกคนที่ 49 ต่อกันไปเรื่อยๆ พอข้อความไปถึงคนที่ 1 (เลเยอร์แรกๆ) สัญญาณเสียงมันก็เบาบางจนแทบไม่ได้ยิน หรือผิดเพี้ยนไปหมดแล้ว! ปรากฏการณ์นี้แหละครับที่ทำให้นักพัฒนา AI ยุคก่อนหัวเสียกันมาก เราเรียกมันว่า “ปัญหาความชันจางหาย (Vanishing Gradient Problem)” ซึ่งเป็นกำแพงที่ทำให้เราสร้างโมเดลลึกๆ ไม่ได้
แต่ Kaiming He และทีมงานจาก Microsoft ปิ๊งไอเดียสุดล้ำว่า: “อ้าว… ถ้างั้นทำไมเราไม่สร้าง ‘ทางลัด (Shortcut)’ ให้สัญญาณมันกระโดดข้ามหัวคนกลางๆ ไปเลยล่ะ?” แนวคิดง่ายๆ แต่ทรงพลังนี้ก่อให้เกิดสิ่งที่เรียกว่า Skip Connection ซึ่งเปรียบเสมือนถนนบายพาสเลี่ยงเมืองที่ช่วยให้สัญญาณ Gradient ไหลย้อนกลับไปถึงจุดเริ่มต้นได้แบบเต็มเม็ดเต็มหน่วย ทำให้เครือข่ายสามารถเรียนรู้ได้ลึกระดับ 100+ ชั้นโดยไม่พังพินาศครับ!
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทที่กว้างขึ้นของสถาปัตยกรรมระดับโลก แหล่งข้อมูลได้อธิบายความสำเร็จและโครงสร้างอันเป็นเอกลักษณ์ของ ResNet ไว้ดังนี้ครับ:
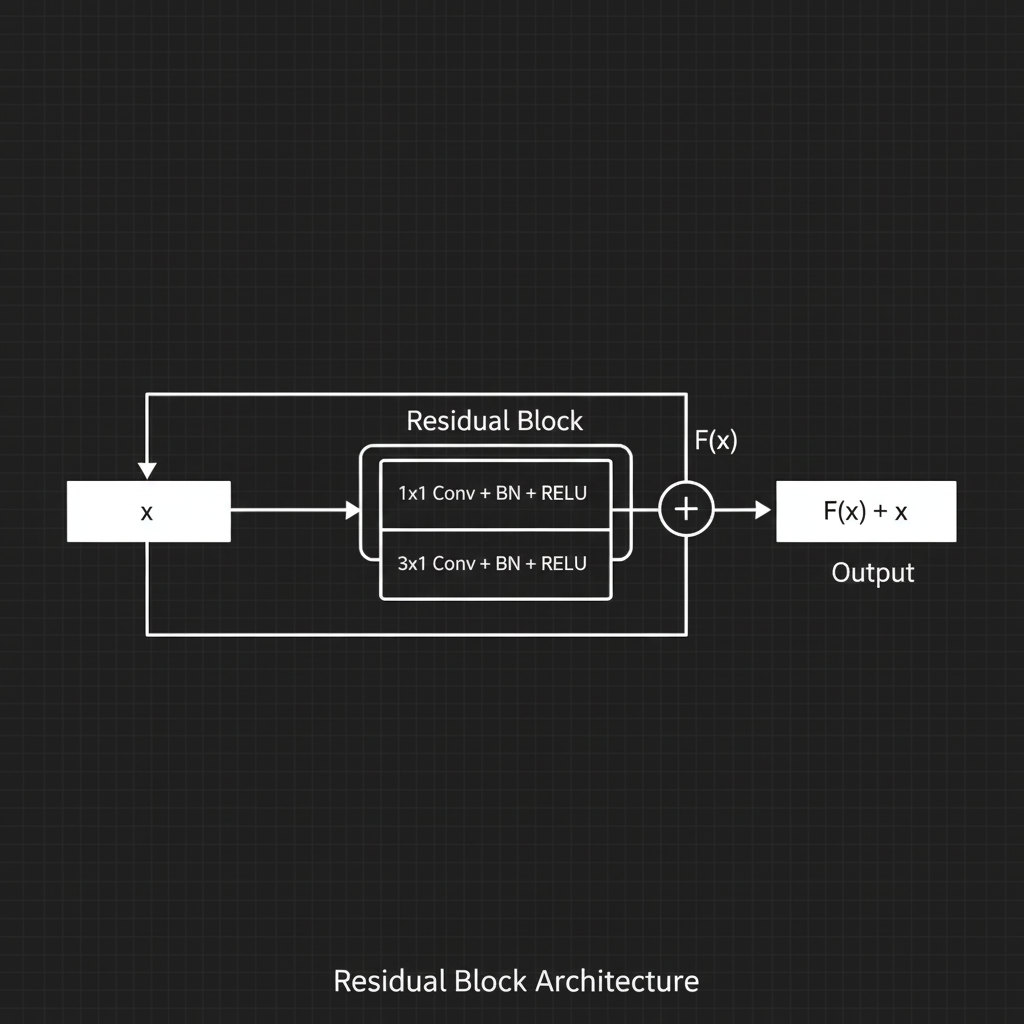
1. The Residual Block (บล็อกแห่งเวทมนตร์): ในเครือข่ายแบบดั้งเดิม (เช่น VGG) ข้อมูล $x$ จะไหลผ่านเลเยอร์ต่างๆ แล้วออกมาเป็น $F(x)$ แบบตรงๆ แต่ใน ResNet โมเดลจะจับข้อมูล $x$ ต้นฉบับ “กระโดดข้าม (Skip connection)” เลเยอร์กลุ่มหนึ่ง แล้วเอามา “บวก” เข้ากับผลลัพธ์ $F(x)$ ที่ปลายทาง ทำให้สมการของเลเยอร์นั้นกลายเป็น:
$$ Output = F(x) + x $$
การบวกตัวตนเดิม (Identity mapping) กลับเข้าไป ช่วยรับประกันว่า “อย่างน้อยที่สุด เลเยอร์ใหม่ที่เพิ่มเข้ามาก็จะไม่ทำให้ผลลัพธ์แย่ลงไปกว่าเดิม” และยังเป็นท่อส่ง Gradient ตรงๆ ในช่วง Backpropagation อีกด้วยครับ
2. ทำไมต้อง ResNet-50? (The Sweet Spot): เปเปอร์ต้นฉบับนำเสนอโมเดลตั้งแต่ 18, 34, 50, 101 ไปจนถึง 152 ชั้น แม้ตัว 152 ชั้นจะแม่นยำที่สุด แต่ในทางปฏิบัติ (Production) วิศวกรส่วนใหญ่มักจะลงเอยด้วย ResNet-50 ครับ เพราะมันเป็น “จุดสมดุล” ระหว่างความแม่นยำที่สูงมาก กับขนาดไฟล์ที่ไม่ใหญ่เกินไป (ประมาณ 102 MB) ทำให้โหลดขึ้นแรมและทำงานบน Edge Device หรือ Server ทั่วไปได้สบายๆ
3. การบีบอัดด้วย Bottleneck Architecture: ในเวอร์ชัน ResNet-50 เป็นต้นไป เขาไม่ได้ใช้ Convolution ขนาด $3 \times 3$ สองชั้นซ้อนกันแบบปกติแล้วนะครับ แต่เขาเปลี่ยนไปใช้โครงสร้างแบบ Bottleneck (คอขวด) โดยใช้ Filter ขนาด $1 \times 1$ บีบอัดความลึก (Channels) ให้เล็กลงก่อน $\rightarrow$ ตามด้วย $3 \times 3$ $\rightarrow$ แล้วใช้ $1 \times 1$ ขยายกลับให้เท่าเดิม เทคนิคนี้ช่วยประหยัดการคำนวณและลด Parameter ลงไปได้มหาศาล!
4. สังหาร Fully Connected ด้วย Global Average Pooling (GAP): จำ VGG-16 ที่อ้วนเพราะชั้น Dense Layers ตอนท้ายได้ไหมครับ? ResNet ฉลาดกว่านั้น มันโยนชั้น Dense ทิ้งไปเกือบหมด แล้วใช้ท่า Global Average Pooling (หาค่าเฉลี่ยของ Feature Map ทั้งแผ่นให้เหลือตัวเลขเดียว) ก่อนส่งเข้าชั้น Softmax ท่านี้ทำให้ ResNet-50 ลึกกว่า VGG16 ถึง 3 เท่า แต่กลับมีจำนวน Parameter น้อยกว่าและเบากว่ามาก!
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ด้วยความที่ ResNet-50 คือ “พระเอกตัวจริง” ของวงการ พี่แทบจะไม่เคยเห็นใครต้องมานั่งเขียน Residual Block เองทีละชั้นครับ การโหลดโมเดลที่พรีเทรนมาแล้ว (Pre-trained on ImageNet) จาก Keras เพื่อทำ Transfer Learning คือมาตรฐานการทำงานของวิศวกรยุคนี้ครับ:
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras import layers, models
# -------------------------------------------------------------
# 📌 1. โหลด ResNet-50 (ยอดศัสตราแห่งวงการ)
# - weights="imagenet": ดึงสมองที่เรียนรู้จากรูปภาพ 1.2 ล้านรูปมาใช้
# - include_top=False: ตัดหัว Classifier 1,000 คลาสทิ้งไป เราจะต่อหัวใหม่เอง!
# -------------------------------------------------------------
base_model = ResNet50(weights="imagenet",
include_top=False,
input_shape=(224, 224, 3))
# แช่แข็ง (Freeze) ความรู้ดั้งเดิม ไม่ให้มันถูกพังทลายตอนที่เราสอนงานใหม่
for layer in base_model.layers:
layer.trainable = False
# -------------------------------------------------------------
# 📌 2. สร้างหัวสมองใหม่ (Classifier) สำหรับงานเฉพาะทางในโรงงาน
# -------------------------------------------------------------
model = models.Sequential([
base_model,
# นี่ไงครับ! Global Average Pooling ที่ช่วยให้ไม่ต้องใช้ Flatten แรมไม่บวม
layers.GlobalAveragePooling2D(),
layers.Dense(256, activation='relu'),
layers.Dropout(0.5), # กันโมเดลจำข้อสอบ
layers.Dense(3, activation='softmax') # สมมติว่าต้องการแยกชิ้นงาน 3 เกรด
])
model.summary()คอมเมนต์: สังเกตไหมครับว่าแค่เราเปลี่ยนมาใช้ ResNet50() เราก็ได้สุดยอดสถาปัตยกรรมที่แก้ปัญหา Vanishing Gradient มาครอบครอง และการใช้ GlobalAveragePooling2D() ก็เป็น Best Practice ที่ดึงมาจากเปเปอร์ของ ResNet โดยตรงเลยล่ะครับ!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
สำหรับน้องๆ ที่อยากเอา ResNet ไปใช้ในระบบจริง พี่มีสัจธรรมจากหน้างานมาฝากครับ:
- กระดูกสันหลังอมตะ (The Ultimate Backbone): ถ้าน้องไปเปิดเปเปอร์หรืองานวิจัยเกี่ยวกับ Object Detection ยอดฮิตอย่าง Faster R-CNN, Mask R-CNN, หรือ RetinaNet น้องจะพบว่าโมเดลพวกนี้ล้วนใช้ ResNet-50 (หรือ ResNet-101) เป็น “Backbone (ตัวสกัดฟีเจอร์หลัก)” ก่อนส่งต่อให้ระบบตีกรอบแทบทั้งสิ้น! มันคือโครงสร้างพื้นฐานที่เสถียรที่สุดในวงการตอนนี้ครับ
- Identity Mapping: ในเปเปอร์รุ่นแรก (ปี 2015) ฟังก์ชัน ReLU จะอยู่ หลังจากการบวก (Addition) ครับ แต่ในเปเปอร์อัปเดตถัดมา (ปี 2016) ทีมวิจัยพบว่าการย้าย ReLU ไปอยู่ ข้างใน Residual Block แล้วปล่อยให้การส่งผ่านค่า $x$ บนสายบายพาสเป็น True Identity Mapping (ส่งไปเพียวๆ ไม่มี Activation กั้น) จะช่วยให้การเทรนเน็ตเวิร์กที่ลึกระดับ 1000 ชั้น ทำได้ง่ายและเสถียรขึ้นไปอีกครับ!
- เมื่อไหร่ควร Unfreeze?:
ถ้าน้องทำ Transfer Learning แล้วพบว่า Accuracy ไม่ยอมขึ้น ให้ลองปลดล็อก (Unfreeze) เลเยอร์หลังๆ ของ ResNet (ประมาณลึกๆ หรือบล็อกสุดท้าย) แล้วใช้ Learning rate ต่ำมากๆ (เช่น
1e-5) ค่อยๆ จูน (Fine-tuning) ดูครับ การทำแบบนี้จะทำให้เวทมนตร์ของ Residual Block ปรับตัวเข้ากับข้อมูลโรงงานของน้องได้แนบเนียนยิ่งขึ้น
6. 🏁 บทสรุป (To be continued…)
สรุปส่งท้ายกันครับ ResNet-50 คือโมเดลระดับตำนานที่ทลายกำแพงความจำกัดเรื่อง “ความลึก” ของโครงข่ายประสาทเทียม ด้วยนวัตกรรมที่เรียบง่ายแต่งดงามอย่าง Skip Connection ($F(x) + x$) ทำให้โมเดลรอดพ้นจากปัญหาความชันจางหาย (Vanishing Gradient) ส่งผลให้มันกลายเป็นรากฐานและ “Backbone มาตรฐาน” สำหรับงานประมวลผลภาพขั้นสูงทั่วโลกมาจนถึงทุกวันนี้ครับ
ตอนนี้เราได้เรียนรู้สุดยอดโมเดลสำหรับงาน “จัดหมวดหมู่ภาพ (Image Classification)” กันไปครบถ้วนแล้ว แต่ในโลกของวิศวกรรม บางครั้งเราไม่ได้อยากรู้แค่ว่า “ภาพนี้คืออะไร” แต่เราอยากรู้ว่า “ของชิ้นนั้นอยู่ที่ตำแหน่งไหนในภาพ!?” ในซีรีส์ตอนถัดๆ ไป พี่จะพาน้องๆ ข้ามพรมแดนเข้าสู่วงการ Object Detection (การตรวจจับวัตถุ) อย่างตระกูล R-CNN และ YOLO กันบ้างครับ รับประกันความเดือดแน่นอน!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p