ผ่าสถาปัตยกรรม Inception-V3: โมเดลหลายใจที่ขอเหมาหมดทุก Filter เพื่อความสมบูรณ์แบบ (Popular Models)
1. 🎯 ตอนที่ 26: ผ่าสถาปัตยกรรม Inception-V3 โมเดลหลายใจที่ขอเหมาหมดทุก Filter
สวัสดีครับน้องๆ วิศวกรสาย Vision ทุกคน! มาจิบกาแฟลุยกันต่อครับ หลังจากตอนที่แล้วเราได้พูดถึงโมเดลยอดนิยมอย่าง VGGNet ที่เน้น “ความลึกและความเป็นระเบียบ” ด้วยการใช้ Filter ขนาด 3x3 ซ้อนกันไปเรื่อยๆ จนประสบความสำเร็จอย่างงดงาม
แต่วันนี้ พี่จะพาไปรู้จักกับอีกหนึ่งปรัชญาการออกแบบที่มาจากค่ายยักษ์ใหญ่อย่าง Google ซึ่งฉีกกฎเกณฑ์เดิมๆ ทิ้งไปอย่างสิ้นเชิง สถาปัตยกรรมนี้เริ่มต้นจากชื่อ GoogLeNet (หรือ Inception-V1) และถูกพัฒนาต่อยอดมาจนถึงจุดสูงสุดที่วงการอุตสาหกรรมนิยมใช้กันอย่าง Inception-V3,
ในจักรวาลของโมเดลยอดนิยม (Popular Models) โมเดลตัวนี้เข้ามาแก้ปัญหาความหนักและความอืดของเครือข่ายยุคเก่าได้อย่างน่าทึ่ง เรามาเจาะลึกกันครับว่า “เวทมนตร์” ของมันคืออะไร และทำไมมันถึงกลายมาเป็นหนึ่งใน State-of-the-art CNNs ที่ถูกเตรียมไว้ให้เรียกใช้งานฟรีๆ ใน Keras!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องเป็นนักสืบที่กำลังยืนดูภาพสถานที่เกิดเหตุ… ถ้าน้องใช้ “แว่นขยายวงเล็ก” (Filter ขนาด 1x1 หรือ 3x3) น้องจะเห็นรายละเอียดเล็กๆ น้อยๆ เช่น รอยนิ้วมือหรือเส้นผม แต่ถ้าน้องถอยออกมาก้าวหนึ่งแล้วใช้ “แว่นขยายวงใหญ่” (Filter ขนาด 5x5) น้องจะเห็นภาพรวมของห้องว่าศพอยู่ตรงไหน โต๊ะล้มอย่างไร
ในยุคก่อนหน้านี้ เวลาวิศวกรออกแบบ Convolutional Neural Network (CNN) พวกเขาต้องเจอปัญหาปวดหัวว่า: “ในเลเยอร์นี้ เราควรจะใช้แว่นขยายขนาดเท่าไหร่ดี? จะเอา 3x3 หรือ 5x5 ดี? แล้วจะวาง Pooling ไว้ตรงไหน?” ซึ่งมันเป็นการลองผิดลองถูกที่เสียเวลามาก
จนกระทั่งทีมวิจัยจาก Google ได้ตั้งคำถามสุดกวนว่า: “ทำไมเราต้องเลือกด้วยล่ะ? ในเมื่อภาพหนึ่งภาพมีทั้งจุดเด่นขนาดเล็กและขนาดใหญ่ผสมกัน… งั้นเราก็จับมันรันผ่าน Filter ขนาด 1x1, 3x3, 5x5 และ Max Pooling ไปพร้อมๆ กันแบบขนาน (Parallel) ซะเลยสิ!”,
แนวคิดสุด “หลายใจ” นี้แหละครับที่ก่อกำเนิดสิ่งที่เรียกว่า Inception Module ที่พลิกโฉมวงการ และทำให้ Inception-V3 กลายเป็นหนึ่งในโมเดลที่สกัด Feature ได้ครอบคลุมและฉลาดที่สุดตัวหนึ่งของโลก!
3. 🧠 แก่นวิชา (Core Concepts)
ในฐานะโมเดลเรือธงที่ผลักดันขีดจำกัดของวงการ แหล่งข้อมูลระดับโลกได้ระบุความโดดเด่นและกลไกการทำงานของ Inception-V3 ไว้ดังนี้ครับ:
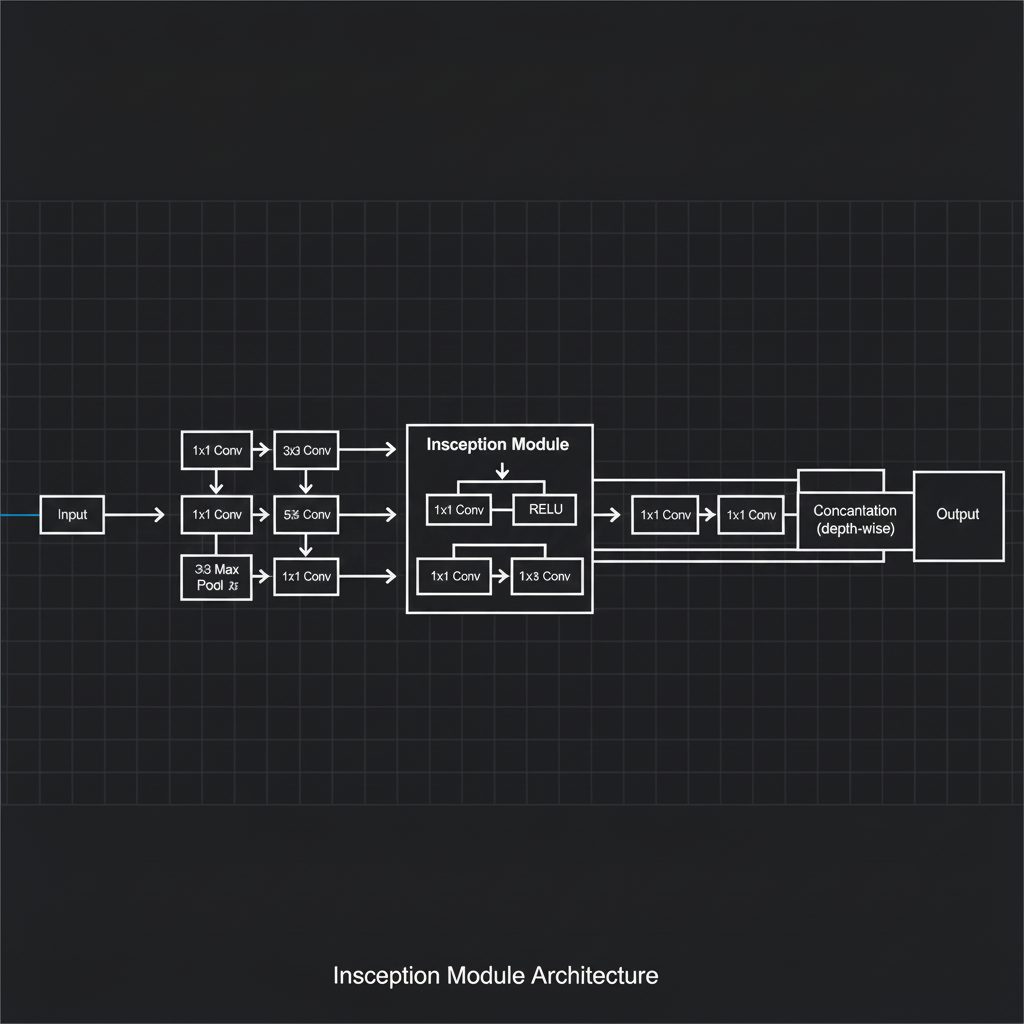
1. โมดูล Inception (The Inception Module): แทนที่จะเรียง Layer เป็นเส้นตรงแบบดั้งเดิม โมเดลนี้ใช้โครงสร้างแบบทำคู่ขนาน โดยใน 1 บล็อก (Module) ข้อมูลภาพจะถูกส่งเข้าไปคำนวณผ่าน Filter ขนาด $1 \times 1$, $3 \times 3$, $5 \times 5$, และชั้น $3 \times 3$ Max Pooling พร้อมๆ กัน จากนั้นผลลัพธ์จากทุกเส้นทางจะถูกนำมาต่อกัน (Depth Concatenation) ในแกนของความลึก (Channel) ก่อนส่งไปเลเยอร์ถัดไป, ทำให้โมเดลมี “ดวงตาหลายขนาด (Multi-level feature extractor)” ที่มองเห็นทั้งรายละเอียดเล็กๆ และโครงสร้างใหญ่ๆ ในคราวเดียว
2. พระเอกตัวจริง: 1x1 Convolution (The Bottleneck): ถ้านำ Filter 3x3 และ 5x5 มาทำงานพร้อมกันเยอะๆ คอมพิวเตอร์คงแรมระเบิดแน่ๆ ครับ ทีมวิจัยจึงแก้ปัญหาด้วยการใส่เลเยอร์ลดขนาดที่เรียกว่า 1x1 Convolution เข้าไปดักหน้า Filter ใหญ่ๆ เหล่านั้น, เลเยอร์นี้ทำหน้าที่เป็น “คอขวด (Bottleneck)” เพื่อบีบอัดมิติความลึก (Dimensionality reduction) ของข้อมูลให้บางลงก่อนเข้าสู่กระบวนการคำนวณที่หนักหน่วง ผลลัพธ์คือ มันช่วยลดจำนวนพารามิเตอร์และภาระการคำนวณลงได้อย่างมหาศาล!,
3. วิวัฒนาการสู่ V3 (The Evolution to V3): Inception-V3 ถูกพัฒนาต่อยอดจากเวอร์ชันแรก (GoogLeNet) โดยมีการปรับปรุงโครงสร้างภายใน Inception module ให้ดียิ่งขึ้น เพื่อดันความแม่นยำในการทายผลบนชุดข้อมูล ImageNet ให้สูงขึ้นไปอีกระดับ
4. จิ๋วแต่แจ๋ว (Efficient and Lightweight): เชื่อไหมครับว่า ถึงแม้ Inception-V3 จะซับซ้อนและลึกกว่า แต่ด้วยเวทมนตร์ของ Bottleneck 1x1 ทำให้มันมีขนาดไฟล์ Weights เพียงแค่ประมาณ 96 MB เท่านั้น! ซึ่งเล็กกว่า VGG-16 ที่ปาเข้าไปกว่า 533 MB อย่างเทียบไม่ติด แต่กลับให้ความแม่นยำที่สูงกว่า,
$$ Output = Concat(F_{1x1}, F_{3x3}, F_{5x5}, F_{pool}) $$
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในชีวิตจริงของการทำงานหน้างาน วิศวกรแทบจะไม่ได้เขียนบล็อก Inception-V3 ขึ้นมาใหม่จากศูนย์ครับ เพราะสถาปัตยกรรมมันยาวและซับซ้อนมาก เรามักจะใช้วิธี Transfer Learning โดยการโหลดโมเดลที่ถูก Pre-trained ด้วยชุดข้อมูล ImageNet มาใช้งานผ่าน Keras ยอดฮิตแทนครับ:
import tensorflow as tf
from tensorflow.keras.applications import InceptionV3
from tensorflow.keras import layers, models
from tensorflow.keras import backend as K
# ปิดโหมด Learning Phase ชั่วคราว (ใช้ในงานแบบ DeepDream หรือตอนดึง Feature)
K.set_learning_phase(0)
# -------------------------------------------------------------
# 📌 โหลด Inception-V3 (พร้อมค่าน้ำหนักที่ฉลาดสุดๆ จาก ImageNet)
# - weights='imagenet': โหลดความรู้ที่โมเดลเคยเรียนรู้มาแล้ว
# - include_top=False: ตัดส่วนหัว (Classifier) ทิ้งไป เพื่อเอา Feature Extractor ไปต่อกับงานของเรา
# -------------------------------------------------------------
base_model = InceptionV3(weights='imagenet', include_top=False)
# ลองปริ้นท์ดูรายชื่อ Layer ข้างใน (น้องจะเห็น layer ที่ชื่อขึ้นต้นด้วย mixed เช่น mixed2, mixed3)
base_model.summary()
# สั่ง Freeze ค่าน้ำหนักในส่วน Feature Extractor ไม่ให้พังตอนเราเทรนใหม่
for layer in base_model.layers:
layer.trainable = False
# -------------------------------------------------------------
# 📌 สร้างหัวสมองใหม่ (Custom Classifier) สำหรับแยกชิ้นงานในโรงงาน
# -------------------------------------------------------------
model = models.Sequential([
base_model,
# ใช้ GlobalAveragePooling2D เพื่อรวบรวม Feature ก่อนตัดสินใจ
layers.GlobalAveragePooling2D(),
layers.Dense(256, activation='relu'),
layers.Dropout(0.5),
layers.Dense(5, activation='softmax') # สมมติว่าต้องการแยกของ 5 ประเภท
])คอมเมนต์: โค้ดชุดนี้คือท่ามาตรฐานเลยครับ สังเกตว่าเราแค่เรียก InceptionV3(...) บรรทัดเดียว เราก็จะได้สุดยอดสถาปัตยกรรมที่คอยสกัด Feature ทั้งขนาดเล็กและใหญ่ส่งมาให้เราใช้งานต่อได้ทันที
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
พี่มี “วิชาลับ” จากการเอา Inception-V3 ไปลงสนามจริงมาเล่าให้น้องๆ ฟังครับ:
- ราชาแห่งภาพหลอน (The Backbone of DeepDream): ถ้าน้องๆ เคยเห็นภาพศิลปะแนวหลอนๆ คล้ายภาพความฝันที่ AI สร้างขึ้น (ที่มีหน้าสุนัขหรือตานกโผล่มาเต็มไปหมด) โปรเจกต์นั้นชื่อว่า DeepDream ครับ และรู้ไหมครับว่า โมเดลเบื้องหลังที่ Google เลือกใช้ก็คือ Inception-V3 นี่เอง!, เหตุผลที่ต้องเป็นโมเดลนี้ เพราะโครงสร้างการดึง Feature หลายระดับชั้น (Multi-scale) ของมัน เหมาะกับการนำไปคำนวณ Gradient ย้อนกลับเพื่อกระตุ้น (Maximize activations) รูปแบบทางเรขาคณิตและลวดลายซับซ้อนบนภาพต้นฉบับได้ดีที่สุดครับ,
- เมื่อไหร่ควรเลือกใช้ Inception-V3?: ถ้าน้องๆ ทำระบบ Machine Vision ที่ต้องการความแม่นยำสูง (สูงกว่า VGG) แต่มีข้อจำกัดเรื่องพื้นที่จัดเก็บโมเดลบนฮาร์ดแวร์ หรือต้องการโมเดลที่โหลดขึ้นแรม (RAM) ได้รวดเร็ว Inception-V3 ที่มีขนาดเพียง 96MB ถือเป็นทางเลือก “คลาสสิก” ที่ไว้ใจได้เสมอครับ
6. 🏁 บทสรุป (To be continued…)
สรุปสั้นๆ ให้เห็นภาพนะครับ: Inception-V3 คือสถาปัตยกรรมที่สอนให้โลกรู้ว่า “เราสามารถออกแบบโครงสร้างภายใน (Micro-architecture) ให้ทำงานขนานกันเพื่อเก็บ Feature หลายสเกล และใช้ 1x1 Bottleneck เป็นคอขวดเพื่อลดการคำนวณ ทำให้โมเดลทำงานได้อย่างทรงประสิทธิภาพและล้ำลึกมากขึ้น”,
การมาถึงของตระกูล Inception เป็นตัวเร่งปฏิกิริยาให้เกิดการออกแบบโครงสร้าง Deep Learning ที่ไม่ยึดติดกับการเรียงเป็นเส้นตรง (Sequential) แบบเดิมๆ อีกต่อไป
ในบทความหน้า พี่จะพาไปพบกับสุดยอดโมเดลยอดนิยมอีกตัวหนึ่ง ที่เข้ามาทลายกำแพงของความลึกระดับ 100+ ชั้น ด้วยการใช้เทคนิค “ทางลัด (Skip Connections)” โมเดลระดับตำนานนั้นก็คือ ResNet นั่นเองครับ! เตรียมตัวรับความสนุกได้เลย!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p