ผ่าโครงสร้าง VGGNet: ความเรียบง่ายที่ทรงพลัง เมื่อความลึกของเครือข่ายคือคำตอบ (Popular Models)

1. 🎯 ตอนที่ 25: ผ่าโครงสร้าง VGGNet ความเรียบง่ายที่ทรงพลัง
สวัสดีครับน้องๆ วิศวกรสาย Vision ทุกท่าน! จิบกาแฟให้ตาสว่างกันครับ เพราะวันนี้พี่จะพาไปรู้จักกับสถาปัตยกรรมระดับตำนานที่ทุกคนในวงการต้องเคยเรียกใช้ มันคือโมเดลที่สานต่อความยิ่งใหญ่จาก AlexNet แต่มาพร้อมกับปรัชญาการออกแบบที่ “เรียบง่ายและเป็นระเบียบ” จนกลายมาเป็นรากฐานของงาน Computer Vision ในยุคปัจจุบัน
ในจักรวาลของ โมเดลยอดนิยม (Popular Models) สถาปัตยกรรมที่เรากำลังจะพูดถึงคือ VGGNet (VGG-16 และ VGG-19) ซึ่งถูกคิดค้นโดยทีม Visual Geometry Group จากมหาวิทยาลัย Oxford เรามาเจาะลึกกันครับว่า ทำไมการใช้แค่แว่นขยายขนาดจิ๋วมาเรียงซ้อนกัน ถึงสามารถเอาชนะความท้าทายระดับโลก และทำไมโมเดลนี้ถึงยังถูกนำมาใช้เป็น “กระดูกสันหลัง (Backbone)” ในงาน AI จนถึงทุกวันนี้!
2. 📖 เปิดฉาก (The Hook)
หลังจากการมาถึงของ AlexNet ในปี 2012 วงการ AI ก็ตื่นตัวกับพลังของ Convolutional Neural Networks (CNNs) อย่างมาก แต่ถ้าน้องๆ ลองไปดูโค้ดของ AlexNet น้องจะพบว่ามันมีความ “ยุ่งเหยิง” อยู่พอสมควร เลเยอร์แรกใช้ Filter ขนาดยักษ์ $11 \times 11$ เลเยอร์ต่อมาใช้ $5 \times 5$ สลับกับการทำ Pooling แบบแปลกๆ
จนกระทั่งในปี 2014 คุณ Karen Simonyan และ Andrew Zisserman ได้ตั้งคำถามที่ทรงพลังมากว่า: “เราจำเป็นต้องใช้ Filter ขนาดใหญ่แบบนั้นจริงๆ หรือ? จะเกิดอะไรขึ้นถ้าเราใช้แค่ Filter ขนาดเล็กจิ๋ว $3 \times 3$ เหมือนกันหมดทั้งเน็ตเวิร์ก แต่เพิ่ม ‘ความลึก (Depth)’ ของจำนวนเลเยอร์ให้มากขึ้นแทน?”
ผลลัพธ์ที่ได้คือ VGGNet ซึ่งคว้ารางวัลรองชนะเลิศในงาน ILSVRC 2014 ด้วยสถาปัตยกรรมที่ดูสะอาดตาเป็นระเบียบเหมือนตัวต่อเลโก้ และที่สำคัญ มันทำ Error rate ลดลงเหลือเพียง 7.3% พิสูจน์ให้โลกเห็นว่า “ความลึกของเครือข่าย (Network Depth)” คือกุญแจสำคัญที่แท้จริงของ Deep Learning!
3. 🧠 แก่นวิชา (Core Concepts)
แหล่งข้อมูลระดับโลกได้จัดให้ VGGNet เป็นหนึ่งในสถาปัตยกรรมทรงอิทธิพล โดยมีแนวคิดหลักๆ ดังนี้ครับ:
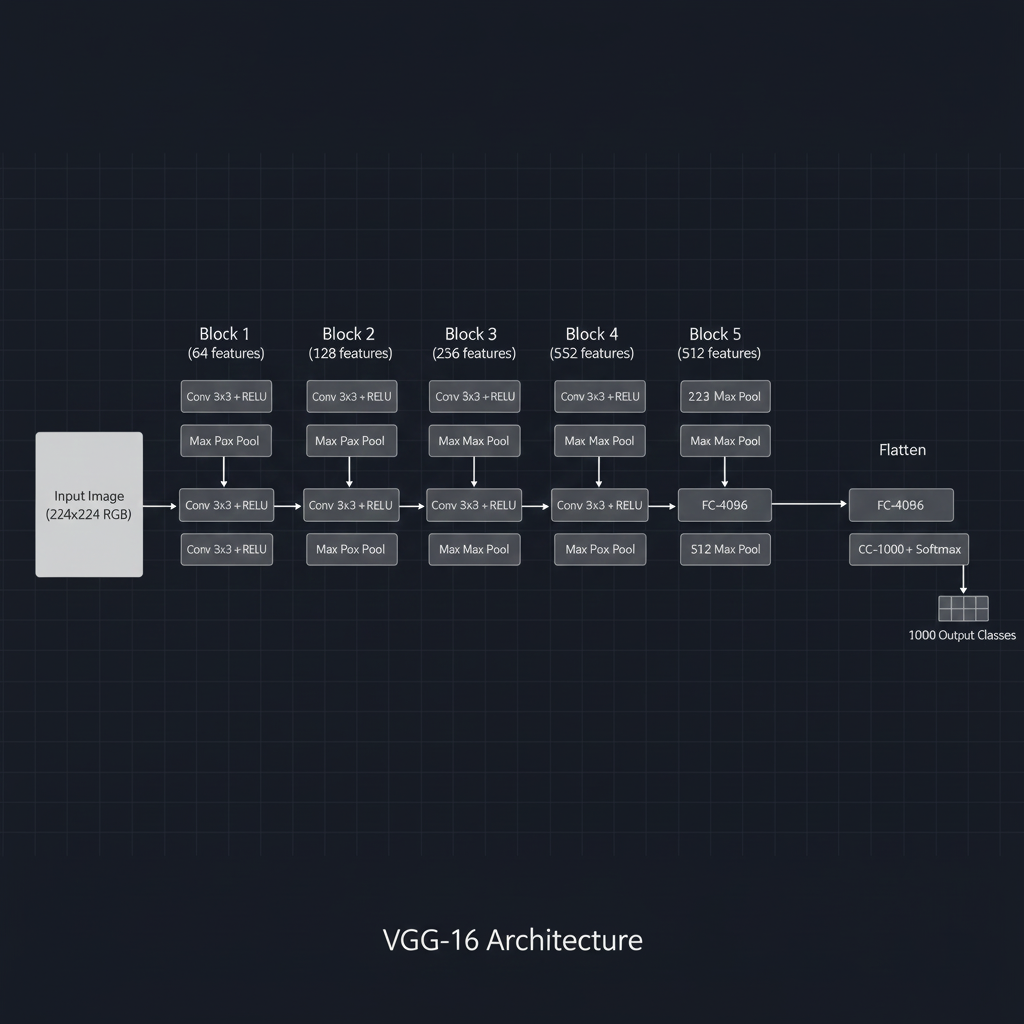
- 1. กฎเหล็กของฟิลเตอร์ $3 \times 3$ (The $3 \times 3$ Rule): เอกลักษณ์ที่สำคัญที่สุดของ VGGNet คือการ ใช้เฉพาะ Filter ขนาด $3 \times 3$ (พร้อมกับ Stride = 1 และ Padding = same) ในทุกๆ Convolutional Layer เลยครับ ทำไมถึงดีกว่า? เพราะการนำ Filter $3 \times 3$ มาซ้อนกัน 2 ชั้น จะมีพื้นที่การมองเห็น (Receptive Field) เท่ากับ Filter $5 \times 5$ พอดี และถ้าซ้อนกัน 3 ชั้นจะเท่ากับ $7 \times 7$ แต่ข้อดีคือ เราจะได้จำนวนพารามิเตอร์ (Weights) ที่ “น้อยกว่า” และการผ่านชั้น Activation Function (ReLU) ที่ “มากกว่า” ทำให้โมเดลสามารถเรียนรู้ความซับซ้อน (Non-linearity) ได้ฉลาดขึ้นครับ
- 2. VGG-16 vs VGG-19:
VGGNet มีการออกแบบไว้หลาย Configuration ตั้งแต่แบบ A ถึง E แต่ตัวที่ฮิตที่สุดคือ:
- VGG-16 (Configuration D): ประกอบด้วย Weight Layers ทั้งหมด 16 ชั้น (13 Convolutional + 3 Fully Connected) มีพารามิเตอร์รวมประมาณ 138 ล้านตัว
- VGG-19 (Configuration E): เป็นเวอร์ชันที่ลึกกว่า โดยเพิ่มเลเยอร์ Conv เข้าไปในบล็อกหลังๆ รวมเป็น 19 ชั้น มีพารามิเตอร์รวมประมาณ 144 ล้านตัว
- 3. บล็อกที่สวยงาม (Uniform Architecture): การจัดเรียงของมันเป็นแพทเทิร์นที่จำง่ายมาก คือทำ $CONV \rightarrow RELU$ ซ้อนกันหลายๆ รอบ (2 หรือ 3 รอบ) แล้วค่อยตบด้วย Max Pooling $2 \times 2$ (Stride = 2) เพื่อลดขนาดภาพลงครึ่งหนึ่ง ทำแบบนี้วนไปเรื่อยๆ จนข้อมูลถูกบีบอัด แล้วจึงส่งเข้า Fully Connected Layers (ขนาด 4096 โหนด) ในตอนท้าย
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ด้วยความที่มันเป็นโมเดลยอดฮิต เราแทบจะไม่ต้องมานั่งต่อบล็อก VGGNet เองทีละชั้นแล้วครับ (ยกเว้นอยากฝึกฝีมือ) ในชีวิตจริงของวิศวกร AI เรามักจะโหลด VGG16 ที่ถูก Pre-trained ด้วยภาพจาก ImageNet มาใช้งานแบบสวยๆ ผ่าน Keras ได้เลยครับ:
import tensorflow as tf
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras import layers, models
# -------------------------------------------------------------
# 📌 โหลดโมเดล VGG16 เพื่อใช้เป็น Feature Extractor (Transfer Learning)
# - weights="imagenet": โหลดค่าน้ำหนักที่คนอื่นเทรนมาแล้วให้ฉลาดสุดๆ
# - include_top=False: ตัดหัวทิ้ง! (ตัด 3 ชั้น Fully Connected ตอนท้ายออก)
# เพราะเราจะเอามาต่อกับหัวสมองใหม่ที่ใช้ทายชิ้นงานในโรงงานของเราเอง
# -------------------------------------------------------------
base_model = VGG16(weights="imagenet",
include_top=False,
input_shape=(224, 224, 3))
# สั่งแช่แข็ง (Freeze) น้ำหนักใน base_model ไม่ให้มันอัปเดตตอนเทรน
for layer in base_model.layers:
layer.trainable = False
# -------------------------------------------------------------
# 📌 สร้างหัวสมองใหม่ (Classifier) มาต่อท้าย
# -------------------------------------------------------------
model = models.Sequential([
base_model,
layers.Flatten(),
layers.Dense(256, activation='relu'),
layers.Dropout(0.5), # กันจำข้อสอบ
layers.Dense(1, activation='sigmoid') # ทายผล: น็อตดี / น็อตเสีย
])
model.summary()คอมเมนต์: สังเกตการตั้งค่า include_top=False นะครับ นี่คือท่ามาตรฐานที่เรียกว่า Transfer Learning ซึ่ง VGG-16 เป็นหนึ่งในโมเดลที่ทำงานนี้ได้ดีเยี่ยมและใช้งานง่ายที่สุด!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
แม้ว่า VGGNet จะดูเรียบง่ายและเป็นอาจารย์ใหญ่ของวงการ แต่ในฐานะคนลุยหน้างานจริง พี่มี “ข้อควรระวัง” ที่ต้องรู้ไว้ครับ:
- คำสาปแห่งความอ้วน (The Weight Problem): ถึงแม้มันจะจัดเรียงสวยงาม แต่ VGGNet เป็นโมเดลที่ “อ้วนและช้ามาก” ครับ! VGG-16 มีไฟล์น้ำหนัก (Weights) ใหญ่ถึง 533 MB และ VGG-19 ใหญ่ถึง 574 MB กินพื้นที่ฮาร์ดดิสก์และแบนด์วิดท์มหาศาล แถมยังใช้เวลาเทรนช้ากว่าโมเดลยุคใหม่อย่างชัดเจน
- หลุมดำของพารามิเตอร์ (The Fully Connected Bottleneck): รู้หรือไม่ครับว่า พารามิเตอร์ 138 ล้านตัวนั้น กว่า 80% มากองรวมกันอยู่ที่ชั้น Fully Connected 3 ชั้นสุดท้าย! (จาก
Flattenไปหาโหนด4096ตัว) นี่คือเหตุผลหลักที่ทำให้มันหนัก ซึ่งในโมเดลยุคหลังๆ (เช่น GoogLeNet หรือ ResNet) เขาจึงแก้ปัญหานี้ด้วยการโยนชั้น FC ทิ้ง แล้วใช้ Global Average Pooling แทนครับ - เกิดมาเพื่อเป็น “แกนหลัง (Backbone)”: ปัจจุบันเราอาจจะไม่ค่อยเอา VGG16 มาจัดหมวดหมู่ภาพทั้งดุ้นแล้ว แต่มันยังคงถูกใช้อย่างแพร่หลายในฐานะ “ตัวสกัดจุดเด่น (Feature Extractor)” สำหรับสถาปัตยกรรมระดับเทพตัวอื่นๆ เช่น นำไปใช้เป็น Backbone ให้กับระบบตรวจจับวัตถุ Faster R-CNN หรือระบบ SSD (Single-shot detector) รวมถึงงานศิลปะ AI อย่าง Neural Style Transfer (การทำภาพสไตล์แวนโก๊ะ) ที่มักจะดึง Feature Map จากชั้นลึกๆ ของ VGG ไปใช้งานเสมอครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว สถาปัตยกรรม VGGNet คือจุดเปลี่ยนสำคัญที่สอนให้โลกรู้ว่า “ความลึก (Depth) มีความสำคัญมากกว่าขนาดของแว่นขยาย (Filter size)”
ด้วยการยึดมั่นในกฎการใช้ Filter จิ๋ว $3 \times 3$ ทำให้มันกลายเป็นโมเดลที่มีความเป็นระเบียบ ใช้งานง่าย และเป็นฮีโร่ตัวจริงที่คอยอยู่เบื้องหลังความสำเร็จของระบบ Transfer Learning, Object Detection และงานสกัด Features อื่นๆ มาจนถึงทุกวันนี้
แต่แน่นอนครับ เมื่อเครือข่ายลึกถึง 19 ชั้น วิศวกรก็เริ่มเจอปัญหาใหม่ที่เรียกว่า “Gradient หาย (Vanishing Gradient)” ทำให้เทรนยากขึ้น ในบทความหน้า พี่จะพาน้องๆ ไปพบกับสถาปัตยกรรมที่มาทลายขีดจำกัดนี้ ด้วยการสร้างเน็ตเวิร์กลึกถึง 150 ชั้น! นั่นคือโมเดล ResNet ห้ามพลาดเด็ดขาดครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p