ผ่าตำนาน AlexNet: อุกกาบาตลูกใหญ่ที่พุ่งชนและพลิกโฉมวงการ Deep Learning

1. 🎯 ตอนที่ 24: ผ่าตำนาน AlexNet จุดเริ่มต้นของยุคทองแห่ง Deep Learning
สวัสดีครับน้องๆ วิศวกรและนักพัฒนา AI ทุกคน! เตรียมกาแฟแก้วโปรดมาให้พร้อมครับ เพราะวันนี้พี่จะพาน้องๆ นั่งไทม์แมชชีนย้อนเวลากลับไปดู “สถาปัตยกรรมยอดนิยม (Popular Models)” ระดับตำนาน ที่เปรียบเสมือนอุกกาบาตลูกใหญ่ที่พุ่งชนวงการ Computer Vision จนไดโนเสาร์ยุคเก่าต้องสูญพันธุ์ไป!
โมเดลที่พี่กำลังพูดถึงนี้คือ AlexNet ครับ เรามาดูกันว่าในบริบทที่กว้างขึ้นของโมเดลยอดนิยมนั้น ทำไมผลงานชิ้นนี้ถึงเปลี่ยนผ่านยุคสมัยจากการทำ “Handcrafted Features” ทื่อๆ ให้กลายมาเป็นยุคของ “Deep Learning” อย่างเต็มตัว และความลับเชิงโครงสร้างของมันมีอะไรบ้าง ลุยกันเลยครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการถึงวงการ AI ในปี ค.ศ. 2012 ดูนะครับ ยุคนั้นมีการจัดแข่งขันระดับโลกที่ชื่อว่า ImageNet Large Scale Visual Recognition Challenge (ILSVRC) ซึ่งเป็นโจทย์สุดโหดที่ต้องให้คอมพิวเตอร์แยกแยะรูปภาพความละเอียดสูงกว่า 1.2 ล้านรูป ให้ออกมาเป็น 1,000 หมวดหมู่
ในตอนนั้น อัลกอริทึมคลาสสิกของ Machine Vision ทั่วไปทำผลงานตื้อๆ กันอยู่ที่ Error rate ราวๆ 25.8% ซึ่งถือว่าเก่งแล้วสำหรับยุคนั้น แต่แล้วก็มีทีมวิจัยจากมหาวิทยาลัยโทรอนโต นำโดยคุณ Alex Krizhevsky, Ilya Sutskever และปรมาจารย์ Geoffrey Hinton ได้ส่งโมเดลโครงข่ายประสาทเทียมชื่อว่า “SuperVision” (หรือที่โลกรู้จักในนาม AlexNet) เข้าประกวด,
ผลลัพธ์ที่ได้ทำให้ทั้งโลกต้องตกตะลึง! AlexNet ทำ Error rate ลดฮวบลงมาเหลือเพียง 15.3% ถึง 17.0% ทิ้งห่างอันดับสองที่ใช้เทคนิคคลาสสิกแบบไม่เห็นฝุ่น!, ชัยชนะที่ขาดลอยนี้เองที่เป็นจุดเริ่มต้นที่ทำให้ทุกคนในวงการต้องหันมามอง “Convolutional Neural Networks (CNNs)” อย่างจริงจัง
3. 🧠 แก่นวิชา (Core Concepts)
ในฐานะ “โมเดลต้นแบบ” ของ CNN ยุคใหม่ แหล่งข้อมูลระดับโลกได้ระบุความล้ำยุคของสถาปัตยกรรม AlexNet ไว้ดังนี้ครับ:
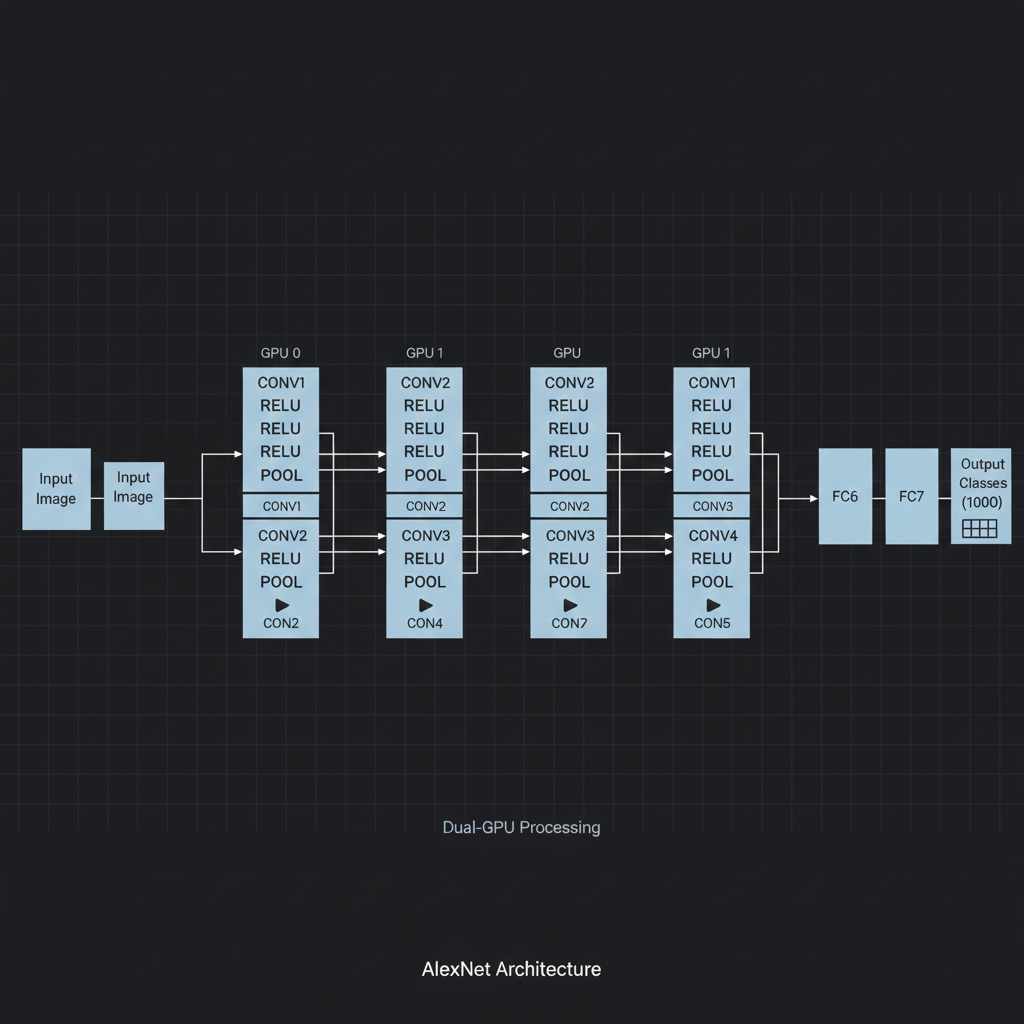
- 1. ใหญ่และลึกกว่าเดิม (Deeper & Bigger): ในขณะที่โมเดลยุคก่อนหน้าอย่าง LeNet-5 มีขนาดเล็กจิ๋ว AlexNet กล้าที่จะสร้างเครือข่ายที่ลึกถึง 8 ชั้น (ประกอบด้วย 5 Convolutional Layers และ 3 Fully Connected Layers) ภายในอัดแน่นไปด้วยพารามิเตอร์กว่า 60 ล้านตัว (60M Parameters) และนิวรอนอีก 650,000 ตัว
- 2. ซ้อน Conv ต่อ Conv (Direct Stacking): เทคนิคเดิมมักจะเอาชั้น Conv สลับกับชั้น Pooling ไปเรื่อยๆ แต่ AlexNet เป็นโมเดลแรกๆ ที่กล้าเอาชั้น Convolutional มา ซ้อนทับกันโดยตรง (Stacked directly) ในชั้นลึกๆ ก่อนที่จะทำการ Pooling (เช่น $CONV \rightarrow CONV \rightarrow CONV$)
- 3. ปฏิวัติวงการด้วย ReLU (The ReLU Revolution): เพื่อแก้ปัญหาความชันจางหาย (Vanishing Gradient) และการคำนวณที่เชื่องช้าของฟังก์ชัน Sigmoid/Tanh ทีมวิจัยได้นำฟังก์ชันกระตุ้นแบบ ReLU (Rectified Linear Unit) มาใช้ใน Hidden Layers ซึ่งช่วยให้โมเดลเรียนรู้ (Train) ได้เร็วกว่าเดิมหลายเท่าตัว
- 4. พลังของ Dual GPU: ด้วยความที่โมเดลมีขนาดใหญ่มาก (60M parameters) การ์ดจอ GTX 580 รุ่นท็อปในสมัยนั้นที่มีแรมแค่ 3GB เอาไม่อยู่ครับ! เขาจึงต้องออกแบบสถาปัตยกรรมให้ “แยกท่อ (Split)” ประมวลผลขนานกันบน GPU 2 ตัว แล้วค่อยเอาข้อมูลมาเชื่อมกันในบางเลเยอร์เท่านั้น
- 5. อาวุธสู้ Overfitting: ยิ่งโมเดลใหญ่ ยิ่งเสี่ยงต่อการจำข้อสอบ (Overfitting) AlexNet จึงจัดหนักด้วยการทำ Data Augmentation (สุ่มตัดภาพและพลิกภาพ) และการใช้เทคนิค Dropout (สุ่มปิดนิวรอน) เพื่อบังคับให้โมเดลมีภูมิต้านทานมากขึ้น,
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้น้องๆ เห็นภาพว่า โครงสร้างระดับตำนานที่เคยพลิกโลกนี้ ถ้าเรามาเขียนด้วย Keras ในยุคปัจจุบัน มันจะหน้าตาเรียบง่ายขนาดไหน ลองดูโค้ดด้านล่างนี้ครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
# 📌 โครงสร้างจำลองของ AlexNet (ปรับแต่งให้เขียนง่ายในยุคปัจจุบัน)
model = models.Sequential(name="AlexNet_Modern")
# --- ส่วนที่ 1: Feature Extraction (5 Convolutional Layers) ---
# Layer 1: ใช้ Filter ใหญ่ยักษ์ (11x11) ก้าวเดินทีละ 4 (Stride=4)
model.add(layers.Conv2D(96, (11, 11), strides=(4, 4), activation='relu', input_shape=(227, 227, 3)))
model.add(layers.MaxPooling2D((3, 3), strides=(2, 2)))
# สมัยก่อนใช้ Local Response Normalization ปัจจุบันเรามักใช้ Batch Normalization แทน
model.add(layers.BatchNormalization())
# Layer 2: Filter เล็กลง (5x5)
model.add(layers.Conv2D(256, (5, 5), padding='same', activation='relu'))
model.add(layers.MaxPooling2D((3, 3), strides=(2, 2)))
model.add(layers.BatchNormalization())
# Layer 3, 4, 5: ซ้อน Conv ต่อ Conv ตรงๆ (จุดเด่นของ AlexNet)
model.add(layers.Conv2D(384, (3, 3), padding='same', activation='relu'))
model.add(layers.Conv2D(384, (3, 3), padding='same', activation='relu'))
model.add(layers.Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(layers.MaxPooling2D((3, 3), strides=(2, 2)))
# --- ส่วนที่ 2: Classification (3 Fully Connected Layers) ---
model.add(layers.Flatten())
# Layer 6 & 7: Dense ขนาดมโหฬาร (4096 นิวรอน) พร้อมใช้ Dropout กันจำข้อสอบ
model.add(layers.Dense(4096, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(4096, activation='relu'))
model.add(layers.Dropout(0.5))
# Layer 8: Output (สมมติ ImageNet 1000 คลาส ใช้ Softmax เป็นผู้พิพากษา)
model.add(layers.Dense(1000, activation='softmax'))
model.summary()คอมเมนต์: สังเกตการใช้ Conv2D ขนาด 11x11 ด้วย strides=4 ในเลเยอร์แรกนะครับ นี่คือเอกลักษณ์ของ AlexNet ที่ต้องการรวบรายละเอียดของภาพขนาดใหญ่ให้เล็กลงอย่างรวดเร็วตั้งแต่ด่านแรกครับ
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในมุมมองของวิศวกรยุคใหม่ที่มองย้อนกลับไป พี่มี Best Practices เกี่ยวกับสิ่งที่ AlexNet ทำไว้ และสิ่งที่ “ตกรุ่น” ไปแล้วมาเล่าให้ฟังครับ:
- หลุมศพของ LRN (Local Response Normalization): ในเปเปอร์ต้นฉบับ AlexNet ภูมิใจนำเสนอเลเยอร์ประหลาดที่เรียกว่า LRN โดยหวังว่ามันจะสร้างพฤติกรรม “ยับยั้งด้านข้าง (Lateral inhibition)” เลียนแบบเซลล์ประสาทชีวภาพ เพื่อบีบให้ Feature maps โดดเด่นแข่งขันกัน แต่กาลเวลาพิสูจน์แล้วว่า LRN กินทรัพยากรมากแต่ให้ผลลัพธ์ไม่คุ้มค่า ปัจจุบันนี้วิศวกรทั่วโลกจึงโยน LRN ทิ้ง และหันมาใช้ Batch Normalization (BN) แทนกันหมดแล้วครับ
- คำสาปของ Kernel ยักษ์ (The Big Kernel Myth): เลเยอร์แรกของ AlexNet ใช้ Kernel มหึมาขนาด $11 \times 11$ เพื่อกวาดหาแพทเทิร์นระดับกว้าง แต่จากการทดลองของสถาปัตยกรรมรุ่นน้องอย่าง VGGNet ทำให้เรารู้ว่า การใช้แว่นขยายจิ๋ว $3 \times 3$ มาซ้อนกันหลายๆ ชั้น ทำงานได้ ฉลาดกว่า และมีจำนวน Parameter น้อยกว่า การใช้แว่นขยายยักษ์อันเดียวครับ!
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว AlexNet คือโมเดลที่ก้าวเข้ามา “พิสูจน์” ให้โลกเห็นว่า ถ้าเรามีข้อมูลมหาศาล (ImageNet) พลังคำนวณที่เหนือชั้น (GPU) และโครงสร้างที่เหมาะสม (ReLU, Dropout) โครงข่ายประสาทเทียมแบบ Deep Learning สามารถโอบกอดความซับซ้อนของโลกแห่งความเป็นจริงได้ดีกว่าสมการคณิตศาสตร์ที่มนุษย์เขียนขึ้นเองหลายขุม!
ความสำเร็จของ AlexNet ไม่ได้เป็นเพียงจุดจบ แต่มันคือ “บรรทัดฐานแรก” ที่จุดประกายให้เกิดการแข่งขันค้นหาสถาปัตยกรรมที่ ลึกขึ้น, เล็กลง, และฉลาดกว่าเดิม ในบทความต่อไป พี่จะพาน้องๆ ไปรู้จักกับลูกหลานของ AlexNet อย่าง VGGNet และ GoogLeNet (Inception) กันครับ ว่าพวกเขาเอาชนะขีดจำกัดเดิมๆ ได้อย่างไร ห้ามพลาดเลยนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p