พัฒนาการดวงตาจักรกล: เมื่อ Kernel มองเห็นจาก 'เส้นขอบ' สู่ 'สุนัขทั้งตัว' ในแต่ละ Layer

1. 🎯 ตอนที่ 23: พัฒนาการดวงตาจักรกล เจาะลึกการทำงานของ Kernel ในแต่ละ Layer
สวัสดีครับน้องๆ วิศวกรและนักพัฒนา AI ทุกคน! กาแฟพร้อมแล้วมาลุยกันต่อเลยครับ ในบทความก่อนหน้านี้ พี่ได้อธิบายไปแล้วว่า Kernel หรือ Filter คือแว่นขยายจิ๋วที่คอยกวาด (Slide) ไปทั่วภาพเพื่อสกัดลักษณะเด่น (Features) ออกมาผ่านกระบวนการทางคณิตศาสตร์
แต่คำถามที่น่าสนใจระดับล้านเหรียญก็คือ… ในโครงข่ายที่ลึกเป็นสิบเป็นร้อยชั้น (Deep Layers) อย่าง VGGNet หรือ ResNet นั้น “แว่นขยาย” ในเลเยอร์แรกสุด มันมองเห็นภาพเหมือนกับ “แว่นขยาย” ในเลเยอร์ลึกๆ หรือเปล่า? คำตอบคือ “ต่างกันโดยสิ้นเชิงครับ!” วันนี้พี่จะพาไปส่องดูความอัจฉริยะของ CNN ว่ามันมีพัฒนาการในการมองโลกตามลำดับชั้น (Hierarchical Compositionality) อย่างไร!
2. 📖 เปิดฉาก (The Hook)
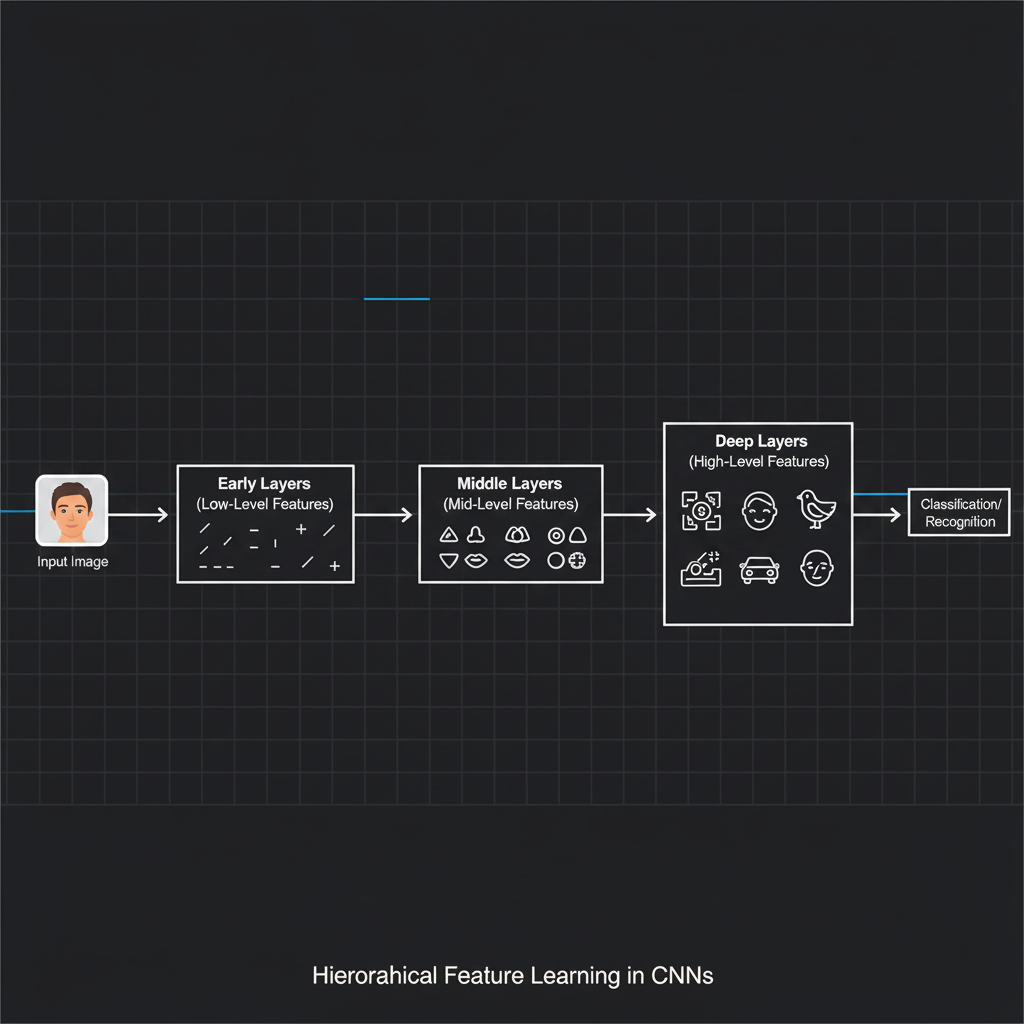
ลองจินตนาการว่าน้องๆ เอาตาส่องแว่นขยายแล้วเอาไปจ่อติดกับภาพวาดสีน้ำมันแบบแนบชิดติดกระดาษดูสิครับ น้องจะมองไม่เห็นหรอกว่าภาพนั้นคือ “บ้าน” หรือ “ต้นไม้” สิ่งเดียวที่น้องจะเห็นคือ “รอยพู่กันลากเป็นเส้นตรง”, “เส้นเฉียง” หรือ “หยดสีแดง” (นี่คือสิ่งที่เลเยอร์แรกของ CNN เห็น)
แต่พอน้องถอยหลังออกมานิดนึง น้องจะเริ่มเห็นว่าเส้นเฉียงเหล่านั้นประกอบกันเป็น “หลังคาสามเหลี่ยม” (นี่คือสิ่งที่เลเยอร์กลางเห็น) และถ้าน้องถอยหลังออกมามองภาพรวมทั้งหมด น้องถึงจะปะติดปะต่อเรื่องราวได้ว่า “อ๋อ! นี่มันคือภาพบ้านที่มีสุนัขนั่งอยู่หน้าบ้านนี่นา!” (นี่คือสิ่งที่เลเยอร์สุดท้ายเห็น)
กระบวนการค่อยๆ สร้างความเข้าใจจากสิ่งที่เล็กที่สุด ไปสู่ความซับซ้อนระดับสูงนี้ คือเวทมนตร์ที่เกิดขึ้นภายในชั้นต่างๆ ของ Convolutional Neural Networks (CNNs) ครับ เรามาแกะรอยการทำงานของมันกันเลย!
3. 🧠 แก่นวิชา (Core Concepts)
แหล่งข้อมูลระดับโลกได้อธิบายพฤติกรรมและการเรียนรู้ของ Kernel (Filters) ในแต่ละ Layer ไว้เป็นลำดับขั้นที่งดงามมากครับ:
- 1. ด่านหน้า: เลเยอร์ระดับล่าง (Low-level Features) ใน Convolutional Layer ชั้นแรกๆ (Early layers) เครือข่ายจะทำหน้าที่เหมือนคนสายตาสั้นครับ Kernel ในชั้นนี้จะเรียนรู้และจับ (Activate) เฉพาะลักษณะพื้นฐานที่เรียบง่ายที่สุด เช่น เส้นตรง (Straight lines), เส้นขอบ (Edges), เส้นมุม (Corners) หรือ จุดสี (Color blobs) กระบวนการนี้เกิดขึ้นจากการเอาค่าใน Kernel ไปคูณกับค่าพิกเซลของภาพ (Element-wise multiplication) แล้วจับบวกกัน ดังสมการ
$$ S(i, j) = \sum_m \sum_n I(i+m, j+n) K(m, n) $$
2. ด่านกลาง: เลเยอร์ระดับกลาง (Mid-level Features) เมื่อข้อมูลถูกส่งผ่านไปยังเลเยอร์ลึกขึ้น (เช่น Layer ที่ 3 หรือ 4) โมเดลจะนำ “เส้นขอบและเส้นโค้ง” จากชั้นแรก มาประกอบร่างกันเป็น “รูปทรง (Shapes)” หรือรูปแบบที่เจาะจงกับชุดข้อมูลมากขึ้น ยกตัวอย่างเช่น ถ้าน้องเทรนโมเดลแยกรูปใบหน้าคน Kernel ในชั้นนี้จะเริ่มจับรูปแบบของ ดวงตา, จมูก, หรือใบหู ได้แล้วครับ
3. ด่านลึก: เลเยอร์ระดับสูง (High-level Features) ใน Convolutional Layer ชั้นลึกๆ (Deeper layers) Kernel จะรวบรวมชิ้นส่วนจากเลเยอร์กลางมาปะติดปะต่อเป็น “วัตถุที่ซับซ้อน (Complex objects)” หรือโครงสร้างที่มีความหมายระดับสูง เช่น มันสามารถเรียนรู้ที่จะรวม ตา จมูก ปาก เข้าด้วยกันจนเข้าใจว่านี่คือ “ใบหน้าของมนุษย์” หรือ “ล้อรถยนต์” เป็นต้น
4. มิติที่สามของ Kernel (Channels and Depth) อีกเรื่องที่สำคัญมากคือ สำหรับภาพสี (RGB) Kernel ของเราไม่ได้มีแค่ กว้าง x ยาว แบบ 2 มิตินะครับ แต่มันเป็น 3 มิติ (3D Volume) ที่มีความลึก (Depth) เท่ากับจำนวน Channel ของข้อมูลนำเข้า เช่น ภาพ RGB จะใช้ Kernel ขนาด $3 \times 3 \times 3$ โดยมันจะสไลด์ไปบนภาพแล้วคำนวณผลรวมครอบคลุมทั้ง 3 สีพร้อมๆ กัน เพื่อคายผลลัพธ์ออกมาเป็น 1 Feature Map
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้เห็นภาพว่า การสร้างโครงข่ายให้มีความลึกเพื่อสกัด Feature ระดับต่างๆ ทำได้อย่างไร ลองดูโค้ด Keras แบบง่ายๆ ที่แสดงการเพิ่มขึ้นของจำนวน Filter ตามความลึกของ Layer ครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential()
# -------------------------------------------------------------
# 📌 ด่านหน้า (Low-level Features)
# ใช้ 32 Filters ขนาด 3x3 เพื่อจับเส้นขอบและสีพื้นฐาน
# -------------------------------------------------------------
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(128, 128, 3), name='Conv_Low_Level'))
model.add(layers.MaxPooling2D((2, 2)))
# -------------------------------------------------------------
# 📌 ด่านกลาง (Mid-level Features)
# ขยายความลึกเป็น 64 Filters เพื่อจับรูปทรงและชิ้นส่วนของวัตถุ
# -------------------------------------------------------------
model.add(layers.Conv2D(64, (3, 3), activation='relu', name='Conv_Mid_Level_1'))
model.add(layers.Conv2D(64, (3, 3), activation='relu', name='Conv_Mid_Level_2'))
model.add(layers.MaxPooling2D((2, 2)))
# -------------------------------------------------------------
# 📌 ด่านลึก (High-level Features)
# ขยายความลึกเป็น 128 Filters เพื่อประกอบชิ้นส่วนขึ้นเป็นวัตถุที่ซับซ้อน
# -------------------------------------------------------------
model.add(layers.Conv2D(128, (3, 3), activation='relu', name='Conv_High_Level'))
model.add(layers.MaxPooling2D((2, 2)))
# ส่งเข้าสู่ส่วนจำแนกประเภท (Classification)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
สำหรับวิศวกรที่ต้องดีไซน์โมเดลหน้างาน พี่มีเบื้องหลังของ Kernel มาเล่าให้ฟังเพิ่มเติมครับ:
- เวทมนตร์แห่ง Weight Sharing: การที่นิวรอนทุกตัวใน Feature Map แผ่นเดียวกัน ใช้ Kernel (หรือชุด Weights) ชุดเดียวกันเป๊ะๆ กวาดไปทั่วภาพ ทำให้เกิดคุณสมบัติที่เรียกว่า Translation Invariance (ความทนทานต่อการเลื่อนตำแหน่ง) หมายความว่า ถ้าน้องสอนให้โมเดลจับ “รอยร้าว” ได้แล้ว ไม่ว่ารอยร้าวนั้นจะปรากฏที่มุมซ้ายบน หรือขวาล่างของภาพ Kernel ตัวเก่งของเราก็จะตามไปเจอได้เสมอครับ!
- ระยะการมองเห็น (Receptive Field): ถึงแม้เราจะใช้ Kernel จิ๋วขนาด $3 \times 3$ เหมือนกันหมดทุก Layer แต่รู้ไหมครับว่า ยิ่งเครือข่ายลึกขึ้น พื้นที่บนภาพต้นฉบับที่เซลล์ประสาท 1 ตัวส่งผลถึง (Receptive Field) จะ “กว้างขึ้นเรื่อยๆ” ทวีคูณ! นี่คือเหตุผลทางคณิตศาสตร์ที่ว่าทำไมเลเยอร์ลึกๆ ถึงสามารถตีความภาพรวมระดับ High-level objects ได้ครับ
- อย่าใช้ Kernel ใหญ่เกินไป: ในยุคก่อนอย่าง AlexNet เขาใช้ Kernel ขนาดยักษ์ $11 \times 11$ ในเลเยอร์แรก แต่ยุคใหม่เขาพิสูจน์แล้วว่า การเอา $3 \times 3$ มาซ้อนกันหลายๆ ชั้น ทำงานได้ฉลาดกว่า รีดยากกว่า (Non-linear กว่า) และกินทรัพยากรน้อยกว่าครับ (เว้นแต่จะใช้ Stride มากๆ ในเลเยอร์แรกเพื่อลดขนาดภาพอย่างรวดเร็ว)
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Kernel ใน Convolutional Neural Networks คือผู้ขับเคลื่อนการเรียนรู้แบบ Hierarchical (ลำดับขั้น) อย่างแท้จริงครับ
เลเยอร์แรกๆ ทำหน้าที่เหมือนคนงานแยกแยะเส้นขอบและจุดสี (Low-level) เลเยอร์กลางนำเส้นขอบมาประกอบเป็นรูปทรง (Mid-level) และเลเยอร์ลึกๆ นำรูปทรงมาปะติดปะต่อเป็นวัตถุที่มีความหมาย (High-level) กระบวนการนี้เกิดขึ้นเองแบบอัตโนมัติ (Automated feature extraction) ระหว่างที่เราสั่ง Training โมเดล โดยปราศจากการแทรกแซงของมนุษย์!
ในบทความถัดไป เมื่อเราเข้าใจแก่นของการสกัด Feature แล้ว เราจะมาดูกันว่า แล้ว CNN มันตัดสินใจขั้นเด็ดขาดในตอนสุดท้ายได้อย่างไร ผ่านการทำงานร่วมกับ Fully Connected Layers ห้ามพลาดนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p