เครื่องอัดจิ๋วทรงพลัง: เจาะลึก Max Pooling กลไกย่อส่วนและคัดกรองขุมพลังของ CNN

1. 🎯 ตอนที่ 23: เครื่องอัดจิ๋วทรงพลัง เจาะลึก Max Pooling กลไกย่อส่วนของ CNN
สวัสดีครับน้องๆ วิศวกรและนักพัฒนา AI ทุกคน! ล้อมวงจิบกาแฟกันต่อครับ หลังจากที่เราได้พูดถึง “แว่นขยาย” อย่าง Convolutional Layers ที่ทำหน้าที่สกัดจุดเด่น (Features) ออกมาจากภาพกันไปแล้ว วันนี้เราจะมาคุยกันถึงปัญหาโลกแตกที่ตามมาติดๆ ครับ
ปัญหานั้นคือ… ยิ่งเราใช้ฟิลเตอร์ (Filters) กวาดหาจุดเด่นเยอะเท่าไหร่ ข้อมูล Feature Maps ที่ได้มันก็ยิ่ง “บวม” และมหาศาลมากขึ้นเท่านั้น ถ้าน้องๆ ปล่อยข้อมูลก้อนมหึมานี้ไหลเข้าไปสู่ชั้น Fully Connected Layers (FC) โดยตรง แรมคอมพิวเตอร์ของน้องๆ คงระเบิดกระจุยกระจาย (Out of Memory) ตั้งแต่ยังไม่ทันได้เทรนแน่นอนครับ!
และนี่คือที่มาของฮีโร่ประจำวันนี้ของเรา “Max Pooling” หรือชั้นการลดขนาดภาพ ที่จะเข้ามาทำหน้าที่เป็นเครื่องอัดจิ๋ว คอยบีบอัดข้อมูลให้เล็กลง แต่ยังคงรักษา “ใจความสำคัญ” ของภาพไว้ได้อย่างครบถ้วน เรามาดูกันว่าในบริบทของ Convolutional Neural Networks (CNN) นั้น มันทำงานอย่างไรครับ!
2. 📖 เปิดฉาก (The Hook)
ลองนึกภาพตามพี่นะครับ สมมติว่าน้องกำลังดูกล้องวงจรปิดเพื่อหา “ป้ายทะเบียนรถ” Convolutional Layer ของเราจะทำหน้าที่สร้าง Feature Map ออกมาหลายร้อยแผ่น แผ่นนึงบอกว่าเจอเส้นตรง แผ่นนึงบอกว่าเจอตัวเลข แผ่นนึงเจอขอบป้าย
ถ้าภาพต้นฉบับมีขนาด $224 \times 224$ พิกเซล และเรามี 64 ฟิลเตอร์ ข้อมูลที่ได้คือ $224 \times 224 \times 64 = 3,211,264$ ตัวเลข! เยอะเกินไปใช่ไหมครับ? ในความเป็นจริงแล้ว เวลาเราอยากรู้ว่า “มีป้ายทะเบียนอยู่ไหม?” เราไม่ได้แคร์หรอกครับว่าขอบป้ายมันจะอยู่ที่พิกเซลที่ $(150, 120)$ แบบเป๊ะๆ หรือเปล่า ขอแค่รู้ว่า “มันอยู่ในบริเวณโซนขวาล่าง” ก็พอแล้ว
แนวคิดนี้แหละครับคือการทำ Subsampling (การสุ่มตัวอย่างย่อย) ซึ่งในโลกของ CNN เรามักจะใช้ Pooling Layer เข้ามาคั่นกลางระหว่าง Convolutional Layer เพื่อทำหน้าที่ “สรุปผล” และย่อขนาดข้อมูลลงให้คอมพิวเตอร์ของเราทำงานได้ไหวครับ
3. 🧠 แก่นวิชา (Core Concepts)
ในสถาปัตยกรรม CNN แหล่งข้อมูลระดับโลกได้อธิบายบทบาทและพฤติกรรมของชั้น Max Pooling ไว้ดังนี้ครับ:
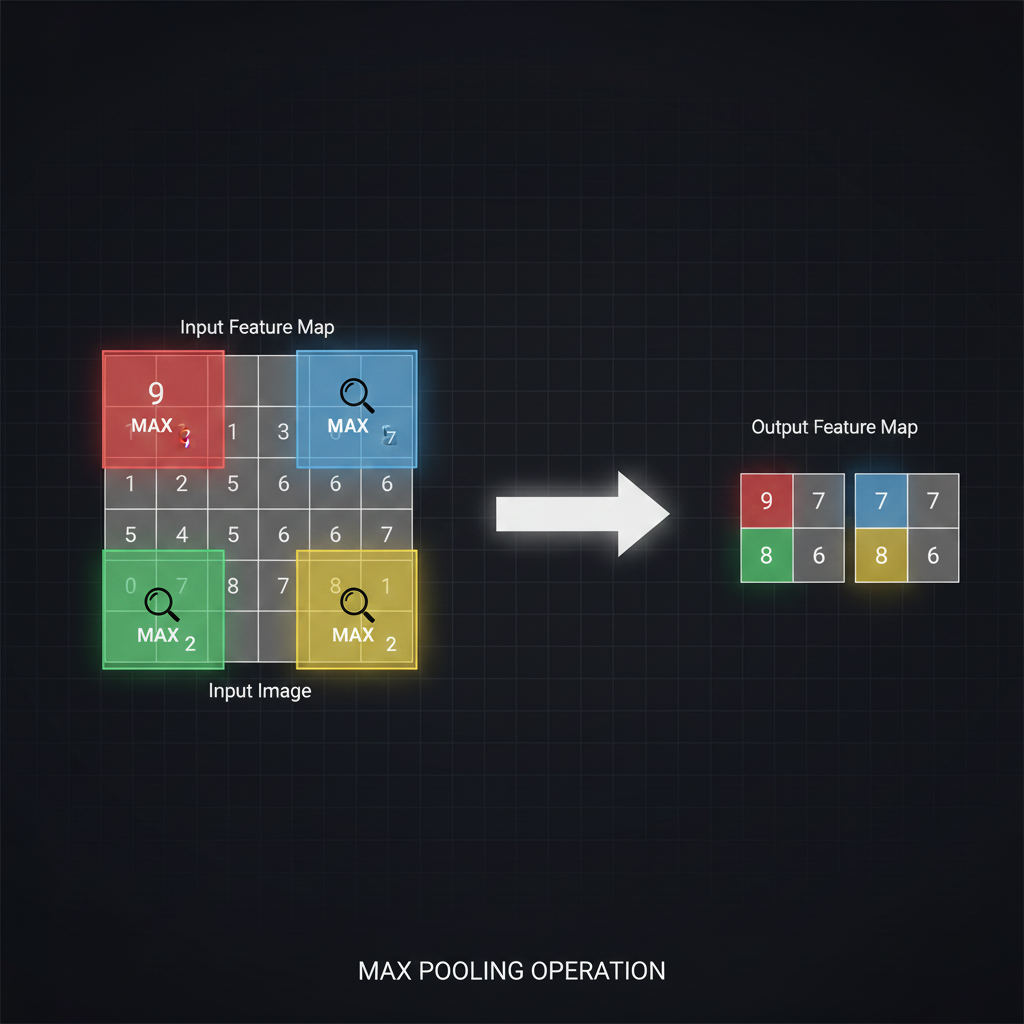
- 1. การทำงานแบบไร้น้ำหนัก (Stateless Sliding Window): ต่างจาก Convolutional Layer ที่มีชุดค่าน้ำหนัก (Weights) ให้โมเดลต้องเรียนรู้ ชั้น Pooling Layer นั้น “ไม่มีพารามิเตอร์ให้ต้องเรียนรู้เลย” มันเป็นเพียงหน้าต่าง (Window) ขนาดเล็ก (เช่น $2 \times 2$) ที่เลื่อนกวาดไปบน Feature Map แล้วทำหน้าที่สรุปผลตัวเลขในหน้าต่างนั้นดื้อๆ เลยครับ
- 2. ทำไมต้องเป็น “Max” (คัดเฉพาะหัวกะทิ): วิธีการสรุปผลยอดฮิตที่สุดคือ Max Pooling (การเลือกค่าสูงสุด) สมมติหน้าต่างขนาด $2 \times 2$ ครอบตัวเลข 4 ตัว (เช่น 1, 5, 3, 2) มันจะดึงแค่เลข “5” ส่งต่อไปยังชั้นถัดไป แล้วทิ้งเลขอื่นหมด เหตุผลที่ใช้วิธีนี้ เพราะค่าพิกเซลที่สูงๆ ใน Feature Map หมายถึง “เซลล์ประสาทกำลังตื่นเต้น (Excited)” หรือตรวจพบแพทเทิร์นบางอย่าง (เช่น เจอเส้นขอบชัดเจน) ดังนั้น Max Pooling จึงเป็นการเลือก “เก็บเฉพาะสัญญาณที่แรงที่สุด” เอาไว้ และทิ้งข้อมูลที่ไม่มีความหมายไป
- 3. ลดภาระการคำนวณและกันจำข้อสอบ (Dimensionality Reduction & Overfitting): เมื่อเราตั้งค่า Stride (ระยะก้าว) ให้เท่ากับขนาดของหน้าต่าง (เช่น หน้าต่าง $2 \times 2$ เดินทีละ 2 ก้าว) ขนาดของภาพจะถูกหาร 2 ทันที (กว้างลดครึ่งนึง สูงลดครึ่งนึง) ทำให้ข้อมูลหายไปถึง 75% ต่อหนึ่งเลเยอร์! การทำเช่นนี้ช่วยลดภาระการคำนวณ (Computational load) ประหยัดเมมโมรี่ และเมื่อพารามิเตอร์ลดลง ก็ยังช่วยป้องกันปัญหา Overfitting (การท่องจำข้อสอบ) ได้โดยปริยายครับ
- 4. ความทนทานต่อการขยับตำแหน่ง (Translation Invariance): นี่คือผลพลอยได้ที่ยอดเยี่ยมมากครับ! สมมติว่าภาพรอยร้าวบนชิ้นงานขยับไปทางขวา 1 พิกเซล ในหน้าต่าง Max Pooling ขนาด $2 \times 2$ ค่าที่สูงที่สุดก็ยังคงอยู่ในกรอบเดิม (หรือถูกส่งออกไปเป็นค่าเดิม) ทำให้โมเดลของเรามีความทนทาน (Invariance) ต่อการขยับ การหมุน หรือการยืดหดของภาพได้ในระดับหนึ่งครับ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในการทำงานจริงด้วย Keras / TensorFlow การใส่ Max Pooling เป็นเรื่องที่ง่ายมากครับ เรามักจะวางมันประกบต่อท้ายชั้น Convolutional เสมอ ลองดูโครงสร้างคลาสสิกนี้ครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential()
# 📌 ชั้นที่ 1: Convolution เพื่อสกัด Features
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu',
padding='same', input_shape=(224, 224, 3)))
# 📌 ชั้นที่ 2: พระเอกของเรา Max Pooling!
# pool_size=(2, 2) หมายถึงใช้หน้าต่างขนาด 2x2
# strides=2 (ค่าเริ่มต้นมักจะเท่ากับ pool_size) ทำให้ภาพขนาด 224x224 หดเหลือ 112x112 ทันที!
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 📌 ทำซ้ำกระบวนการ: สกัด Feature ต่อ แล้วก็ย่อขนาดอีก
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.MaxPooling2D(pool_size=(2, 2))) # ตอนนี้ภาพจะเหลือแค่ 56x56
# ส่งเข้าสู่ Fully Connected Layer สบายๆ แรมไม่พังแล้ว
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในโลกของสถาปัตยกรรมระดับลึก พี่มีเกร็ดความรู้และเทรนด์ใหม่ๆ ของ Pooling มากระซิบบอกครับ:
- Max Pooling vs. Average Pooling: ในอดีตอย่างเครือข่าย LeNet-5 เขาฮิตใช้ Average Pooling (หาค่าเฉลี่ยในหน้าต่าง) กันครับ แต่ปัจจุบันเราพบว่า Max Pooling ทำงานได้ดีกว่ามาก เพราะการหาค่าเฉลี่ยมันทำให้สัญญาณที่ชัดเจน (Strong features) ถูกเจือจางด้วยค่าศูนย์รอบๆ ทำให้ภาพเบลอและโมเดลเรียนรู้ได้ยากกว่าครับ
- กฎเหล็ก 2x2: ในทางปฏิบัติ เราแทบจะไม่เห็นใครใช้ Max Pooling ขนาดใหญ่เกิน $3 \times 3$ เลยครับ ขนาดมาตรฐานอุตสาหกรรมคือ F=2, S=2 (ไม่ทับซ้อนกัน) หรือ F=3, S=2 (แบบทับซ้อนกันเหมือนใน AlexNet) เพราะถ้าใช้ขนาดใหญ่กว่านี้ ข้อมูลเชิงพื้นที่ (Spatial information) จะพังพินาศจนโมเดลไม่รู้เรื่องเลยล่ะครับ
- เทรนด์ใหม่… ทิ้ง Pooling ไปซะ! (The All Convolutional Net): ในเปเปอร์วิจัยยุคใหม่ๆ (เช่น สถาปัตยกรรม ResNet) เริ่มมีกระแส “ไม่ใช้ Pooling Layer” ในระหว่างทางแล้วนะครับ! แต่เขาจะใช้วิธี เพิ่มค่า Stride ในชั้น Convolutional เป็น 2 แทน เพื่อให้มันสกัด Feature ไปด้วยและลดขนาดภาพไปด้วยในขั้นตอนเดียว ซึ่งพบว่าได้ผลลัพธ์ที่ดีและโครงสร้างดูสะอาดตากว่ามากครับ แต่ในชั้นสุดท้ายเพื่อทิ้งมิติภาพก่อนเข้า FC เรามักจะใช้ Global Average Pooling แทนครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Max Pooling คือกลไกสำคัญที่ทำให้ CNN แตกต่างและเหนือกว่า Neural Network แบบดั้งเดิม มันคือ “เครื่องลดทอนความซับซ้อน” ที่ช่วยบีบอัด Feature Maps ให้เล็กลง ประหยัดหน่วยความจำ ลดพารามิเตอร์ และช่วยให้โมเดลของเราโฟกัสเฉพาะ “จุดเด่นที่สำคัญที่สุด” ของภาพ โดยไม่สนใจว่าวัตถุนั้นจะขยับเขยื้อนไปจากตำแหน่งเดิมเล็กน้อยก็ตาม
ตอนนี้เราได้เรียนรู้ชิ้นส่วนหลักของ CNN ครบแล้ว ทั้งแกนสกัดภาพ (CONV), แกนบีบอัด (POOL), และแกนตัดสินใจ (FC) ในบทความต่อไป พี่จะพาน้องๆ ไปดูวิธีการ “ต่อเลโก้” ชิ้นส่วนเหล่านี้ ให้ออกมาเป็นสถาปัตยกรรมระดับตำนานอย่าง LeNet, AlexNet, และ VGGNet ที่เคยคว้าแชมป์โลกมาแล้ว! เตรียมตัวให้พร้อมนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p