แว่นขยายส่องอณูภาพ: เจาะลึก Kernel และ Filters หัวใจแห่งการมองเห็นของ CNN

1. 🎯 ตอนที่ 22: แว่นขยายส่องอณูภาพ เจาะลึก Kernel และ Filters
สวัสดีครับน้องๆ วิศวกรและนักพัฒนา AI สาย Vision ทุกท่าน! กาแฟแก้วโปรดพร้อมแล้วใช่ไหมครับ? ในบทความที่แล้ว พี่ได้พาน้องๆ ไปดูภาพใหญ่ของสถาปัตยกรรม CNN (Convolutional Neural Networks) กันมาแล้ว ว่ามันเกิดมาเพื่อล้มล้างข้อจำกัดของโครงข่ายแบบเดิมๆ อย่างไร
วันนี้เราจะหยิบ “แว่นขยาย” มาส่องดูชิ้นส่วนที่เล็กที่สุด แต่ทำงานหนักที่สุดในระบบ ชิ้นส่วนที่เป็นเสมือน “ดวงตา” ที่คอยสกัดจุดเด่น (Features) ออกมาจากภาพดิบๆ ชิ้นส่วนนั้นมีชื่อเรียกในวงการว่า Kernel หรือ Filter ครับ เรามาเจาะลึกกันว่า ในบริบทที่กว้างขึ้นของ CNN นั้น การเลื่อนหน้าต่างกรอบเล็กๆ ไปบนภาพ มันสร้างเวทมนตร์ให้ AI เข้าใจโลกได้อย่างไร!
2. 📖 เปิดฉาก (The Hook)
ลองนึกย้อนไปในยุคก่อนที่ Deep Learning จะบูมนะครับ เวลาน้องๆ จะทำระบบตรวจจับขอบชิ้นงาน (Edge Detection) น้องต้องเขียนโค้ดเรียกใช้ฟิลเตอร์ที่นักคณิตศาสตร์คิดค้นมาให้แล้ว เช่น เครือข่าย Sobel หรือ Laplacian ฟิลเตอร์พวกนี้คือตารางตัวเลขขนาดเล็ก (เช่น $3 \times 3$) ที่พอเอาไปทาบและคำนวณบนรูปภาพปุ๊บ ภาพที่ออกมาก็จะกลายเป็นเส้นขอบสีขาวบนพื้นดำทันที
ปัญหาคือ ฟิลเตอร์สำเร็จรูปพวกนี้มัน “ตายตัว” ครับ ถ้าน้องอยากให้มันจับรอยร้าวบนผิวน็อต หรือจับใบหน้าคน น้องจะไปหาฟิลเตอร์พวกนี้มาจากไหน? ไม่มีใครบนโลกเขียนสมการคณิตศาสตร์ตายตัวเพื่อหาหน้าคนได้หรอกครับ
และนี่คือความอัจฉริยะของ CNN… แทนที่เราจะไปนั่งกำหนดตัวเลขในฟิลเตอร์เอง CNN บอกว่า “เอาล่ะ ฉันจะสร้างตารางเปล่าๆ ขึ้นมาสัก 1,000 ตาราง (Filters) แล้วเดี๋ยวฉันจะใช้กระบวนการ Training (Backpropagation) เพื่อ ‘เรียนรู้’ ตัวเลขในตารางเหล่านี้เอง ว่าต้องใช้เลขอะไรถึงจะสกัดจุดเด่นของสุนัข แมว หรือน็อตเสีย ออกมาได้!” นี่แหละครับคือการก้าวข้ามขีดจำกัดที่แท้จริง!
3. 🧠 แก่นวิชา (Core Concepts)
ในโลกของ CNN แหล่งข้อมูลได้อธิบายพฤติกรรมและหน้าที่ของ Kernel / Filters ไว้อย่างน่าสนใจดังนี้ครับ:
- 1. Matrix จิ๋ว ปะทะ Matrix ยักษ์: รูปภาพของเราคือ Matrix ยักษ์ (เช่น ขนาด $256 \times 256$ พิกเซล) ส่วน Kernel (หรือ Filter) คือ Matrix จิ๋ว (มักจะเป็นจัตุรัสขนาดคี่ เช่น $3 \times 3$ หรือ $5 \times 5$) ที่มีน้ำหนัก (Weights) ซ่อนอยู่ข้างใน
- 2. กลไกการเลื่อนกวาด (The Sliding Window & Convolution): กระบวนการ Convolution คือการนำ Kernel จิ๋วนี้ ไป “วางทาบ” บนมุมซ้ายบนของรูปภาพ จากนั้นจับตัวเลขที่ตรงกันมาคูณกันทีละคู่ (Element-wise multiplication) แล้วเอาผลลัพธ์ทั้งหมดมา “บวกกัน” ให้กลายเป็นตัวเลข 1 ตัว พื้นที่บนรูปภาพที่ถูก Kernel ทาบทับอยู่ในขณะนั้น เราเรียกว่า Receptive Field จากนั้นมันจะค่อยๆ ขยับ (Slide) กวาดไปจนทั่วทั้งภาพ เพื่อสร้างภาพใหม่ที่เรียกว่า Feature Map
- 3. การเรียนรู้แบบลำดับขั้น (Hierarchical Compositionality):
การใช้ Filters ซ้อนกันหลายๆ เลเยอร์ คือกุญแจความฉลาดครับ
- Layer แรกๆ: Filters จะเรียนรู้รูปแบบง่ายๆ เช่น เส้นตรง เส้นเฉียง หรือจุดสี (Low-level features)
- Layer กลางๆ: นำเส้นเหล่านั้นมาประกอบเป็นรูปทรง (Shapes)
- Layer ท้ายๆ: นำรูปทรงมาประกอบเป็นโครงสร้างซับซ้อน เช่น ดวงตา, ล้อรถ, หรือชิ้นงานอุตสาหกรรม
- 4. เวทมนตร์แห่งการใช้ซ้ำ (Weight Sharing): นิวรอนทุกตัวที่ทำหน้าที่สร้าง Feature Map แผ่นเดียวกัน จะใช้ “Kernel ตัวเดียวกัน (ชุด Weights เดียวกัน)” กวาดไปทั่วทั้งภาพ การทำแบบนี้ช่วยลดจำนวนพารามิเตอร์ (Weights) ลงได้มหาศาล ทำให้เราไม่ต้องใช้แรมคอมพิวเตอร์เยอะเหมือน Neural Network แบบดั้งเดิม (MLP)
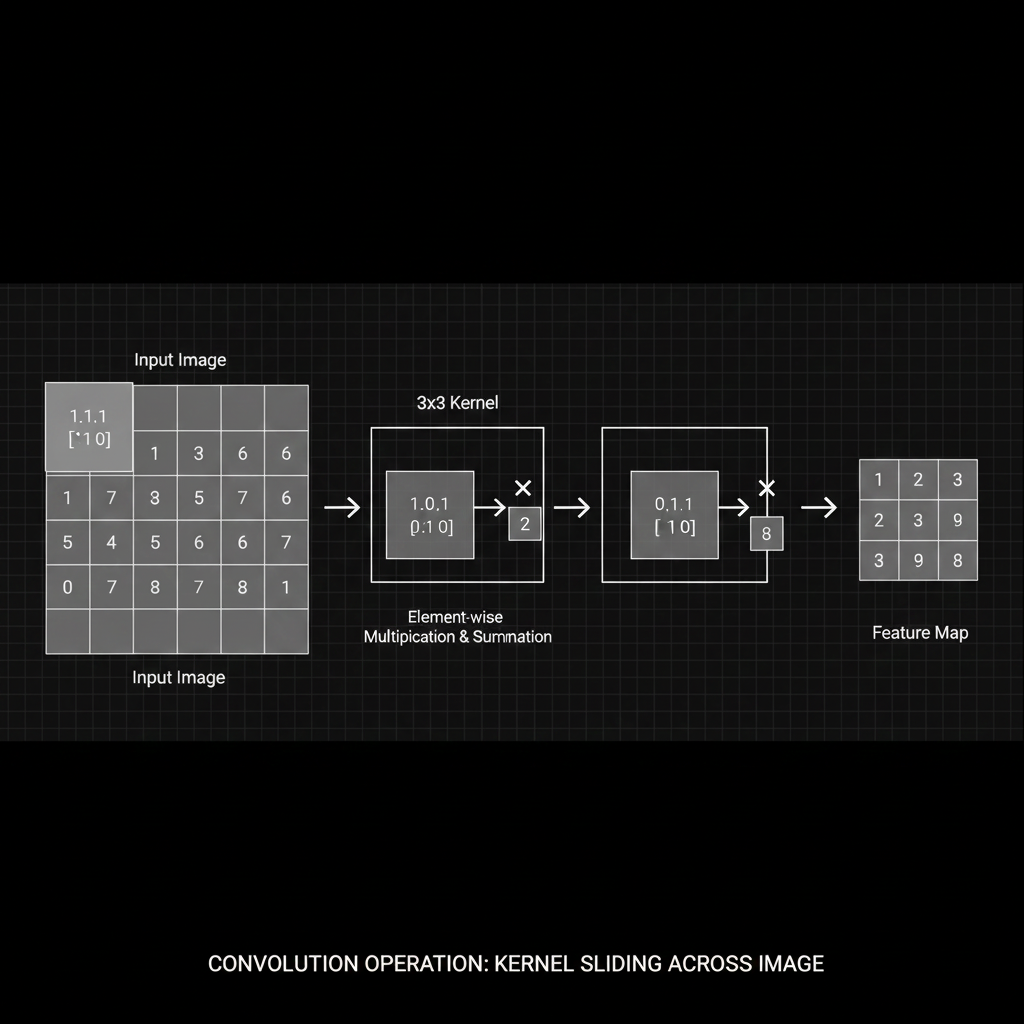
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในการทำงานจริงกับ Keras / TensorFlow เราไม่ต้องมานั่งเขียนลูปคูณเมทริกซ์เองเลยครับ โค้ดสำหรับสร้าง Convolutional Layer นั้นสั้นและทรงพลังมาก ลองมาดูความหมายของตัวแปรแต่ละตัวกันครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential()
# 📌 การสร้าง Convolutional Layer เพื่อสกัด Features
model.add(layers.Conv2D(
filters=32, # จำนวน Kernel (ความลึก) ที่ต้องการให้ AI สกัด (เช่น หา 32 รูปแบบ)
kernel_size=(3, 3), # ขนาดของแว่นขยาย (กว้าง x ยาว) ยอดฮิตคือ 3x3
strides=(1, 1), # ก้าวเดิน (เลื่อนทีละ 1 พิกเซล)
padding='same', # 'same' คือการเติมขอบ 0 (Zero-padding) เพื่อให้ภาพผลลัพธ์มีขนาดเท่าเดิม
activation='relu', # ใส่ความไม่เป็นเชิงเส้น ทิ้งค่าติดลบ
input_shape=(224, 224, 3) # ขนาดภาพดิบ (กว้าง, ยาว, สี RGB 3 แชนเนล)
))
# 📌 ยิ่งลึก ยิ่งเพิ่มจำนวนแว่นขยาย (Filters) เพื่อหาฟีเจอร์ที่ซับซ้อนขึ้น
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(layers.Conv2D(filters=128, kernel_size=(3, 3), activation='relu'))
model.summary()คอมเมนต์: สังเกตว่าตัวแปร filters คือการบอกว่าเลเยอร์นี้ต้องการหา “กี่จุดเด่น” (กลายเป็นจำนวน Feature Maps) ส่วน kernel_size คือ “ขนาดของหน้าต่าง” ที่ใช้กวาดภาพครับ
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในฐานะวิศวกรหน้างาน พี่มี Best Practices เกี่ยวกับการใช้งาน Kernel/Filters มาเตือนกันครับ:
- จงใช้ 3x3 เสมอ (The Power of Small Kernels): ในยุคแรกอย่าง AlexNet เรามักเห็นการใช้ Kernel ขนาดใหญ่บิ๊กเบิ้มอย่าง $11 \times 11$ หรือ $7 \times 7$ เพื่อสกัดภาพรวม แต่ในยุคปัจจุบัน สถาปัตยกรรมระดับโลกอย่าง VGGNet พิสูจน์แล้วว่า การใช้ Kernel $3 \times 3$ ซ้อนกันหลายๆ ชั้น ดีกว่าการใช้ Kernel ใหญ่ๆ ชั้นเดียว! เพราะมันช่วยเพิ่ม Non-linearity (เพิ่มความฉลาด) และลดจำนวน Parameter ลงได้เยอะมากครับ
- ภูมิต้านทานต่อการเลื่อนตำแหน่ง (Translation Invariance): ข้อดีที่สุดอย่างหนึ่งของการที่ Kernel เลื่อนกวาดไปทั่วภาพ คือโมเดลจะมีคุณสมบัติ Translation Invariance หมายความว่า ถ้าน้องสอนให้มันรู้จัก “รอยร้าว” ไม่ว่ารอยร้าวนั้นจะเลื่อนไปอยู่มุมซ้าย มุมขวา หรือตรงกลางภาพ โมเดลก็จะยังตรวจจับได้เสมอ เพราะ Kernel ตัวเก่งของเรากวาดไปเจอเข้าจนได้นั่นเองครับ!
- เวทมนตร์ของ 1x1 Convolution (The Bottleneck): บางครั้งน้องอาจไปเปิดดูเปเปอร์โมเดลล้ำๆ อย่าง GoogLeNet (Inception) หรือ ResNet แล้วเจอเขาใช้ Kernel ขนาด $1 \times 1$… ฟังดูแปลกใช่ไหมครับ? แว่นขยาย 1 พิกเซลจะไปเห็นรูปทรงอะไรได้? ความจริงคือ เขาไม่ได้ใช้มันหาโครงสร้างภาพครับ แต่ใช้เพื่อ “บีบอัดมิติความลึก (Channels)” ข้ามเลเยอร์ เพื่อลดภาระการคำนวณและประหยัดแรม (เรียกว่า Bottleneck layer) อย่างชาญฉลาดนั่นเองครับ!
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Kernel หรือ Filters คือหัวใจสำคัญของการประมวลผลภาพในยุค Deep Learning มันเปลี่ยนแนวคิดจากการที่มนุษย์ต้องมานั่งคิดค้นสูตรจับเส้นขอบภาพเอง ไปเป็นการปล่อยให้เครือข่ายประจุประสาท (CNN) “เรียนรู้ค่าน้ำหนัก (Weights)” ใน Matrix จิ๋วเหล่านี้เอาเองผ่านการฝึกฝน
และด้วยกระบวนการเลื่อนกวาด (Sliding) ผสมผสานกับการใช้ค่าน้ำหนักซ้ำ (Weight Sharing) มันจึงสามารถสกัดคุณลักษณะ (Features) จากระดับพื้นฐานไปจนถึงวัตถุที่ซับซ้อนได้อย่างมีประสิทธิภาพและประหยัดทรัพยากรเครื่องครับ
แต่อย่างที่เราเห็นในโค้ด ยิ่งเราสกัดฟีเจอร์ มิติข้อมูลก็จะยิ่งหนาขึ้นเรื่อยๆ (Depth) เพื่อไม่ให้คอมพิวเตอร์ของเราแรมระเบิด ในตอนถัดไป พี่จะพาน้องๆ ไปพบกับกลไกการ “บีบอัดข้อมูล” ที่มักจะตามหลัง Convolutional Layer เสมอ นั่นก็คือ Pooling Layer (การลดขนาดภาพ) ห้ามพลาดเด็ดขาดครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p