เจาะเวลาหา CNN: สถาปัตยกรรมปฏิวัติวงการ ที่ทำให้ AI 'มองเห็น' โลกได้เหมือนมนุษย์

1. 🎯 ตอนที่ 21: เจาะเวลาหา CNN สถาปัตยกรรมเปลี่ยนโลก Machine Vision
สวัสดีครับน้องๆ วิศวกรและนักพัฒนา AI ทุกท่าน! ชงกาแฟเข้มๆ แล้วมานั่งคุยกันต่อครับ ในตอนก่อนๆ เราได้เรียนรู้โครงสร้างพื้นฐานของ Neural Networks แบบดั้งเดิมอย่าง Multilayer Perceptron (MLP) ที่เป็นแบบ Fully Connected กันไปแล้ว
แต่ในโลกของ Computer Vision การใช้ MLP ธรรมดามันเหมือนการเอามือปิดตาแล้วมองโลกผ่านหลอดดูดน้ำครับ! วันนี้พี่จะพาถอยหลังออกมามองภาพใหญ่ของสถาปัตยกรรมเครือข่าย (Network Architectures) เพื่อทำความรู้จักกับพระเอกขี่ม้าขาวที่ชื่อว่า Convolutional Neural Networks (CNNs) เรามาดูกันว่ามันถือกำเนิดขึ้นมาได้อย่างไร และทำไมมันถึงกลายเป็น “แกนสันหลัง” ของงานประมวลผลภาพทั้งหมดในปัจจุบันครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องมีรูปภาพขนาดแค่ 100 x 100 พิกเซล ถ้าน้องเอาภาพนี้ไปป้อนให้ MLP แบบดั้งเดิมที่มีแค่ 1,000 นิวรอน (Neurons) ในชั้นแรก สิ่งที่เกิดขึ้นคือ… น้องจะต้องใช้เส้นเชื่อมต่อ (Connections/Weights) ถึง 10 ล้านเส้นในชั้นเดียว! และถ้าน้องใช้ภาพความละเอียด 5 Megapixels จากกล้องอุตสาหกรรมล่ะ? คอมพิวเตอร์ของน้องคงระเบิด (Out of Memory) ตั้งแต่ยังไม่ได้เริ่มเทรนด้วยซ้ำ
นอกจากเรื่องแรมเต็มแล้ว ปัญหาที่ใหญ่กว่าคือ MLP บังคับให้น้องต้อง “ยืด” ภาพ 2 มิติ ให้กลายเป็นเส้นตรง 1 มิติ (Flattening) ก่อนป้อนเข้าโมเดล ซึ่งทำให้ “มิติเชิงพื้นที่ (Spatial Information)” เช่น พิกเซลซ้ายขวาที่เคยอยู่ติดกัน ถูกทำลายทิ้งไปจนหมดสิ้น
จนกระทั่งนักวิจัยได้ไปศึกษาโครงสร้างการมองเห็นของสิ่งมีชีวิต (Visual Cortex) และพบว่าเซลล์ประสาทตาของมนุษย์ไม่ได้มองเห็นภาพทั้งหมดพร้อมกัน แต่มันมองเป็น “หย่อมๆ” (Receptive Fields) แล้วค่อยๆ ส่งข้อมูลไปประกอบร่างกันในสมอง ไอเดียสุดล้ำนี้ถูกนำมาสร้างเป็นสถาปัตยกรรม CNN ซึ่งได้พลิกโฉมวงการ AI ไปตลอดกาลครับ!
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทที่กว้างขึ้นของสถาปัตยกรรม Deep Learning ข้อมูลระดับโลกได้อธิบายคุณสมบัติที่ทำให้ CNN โดดเด่นกว่าสถาปัตยกรรมอื่นๆ ไว้ดังนี้ครับ:
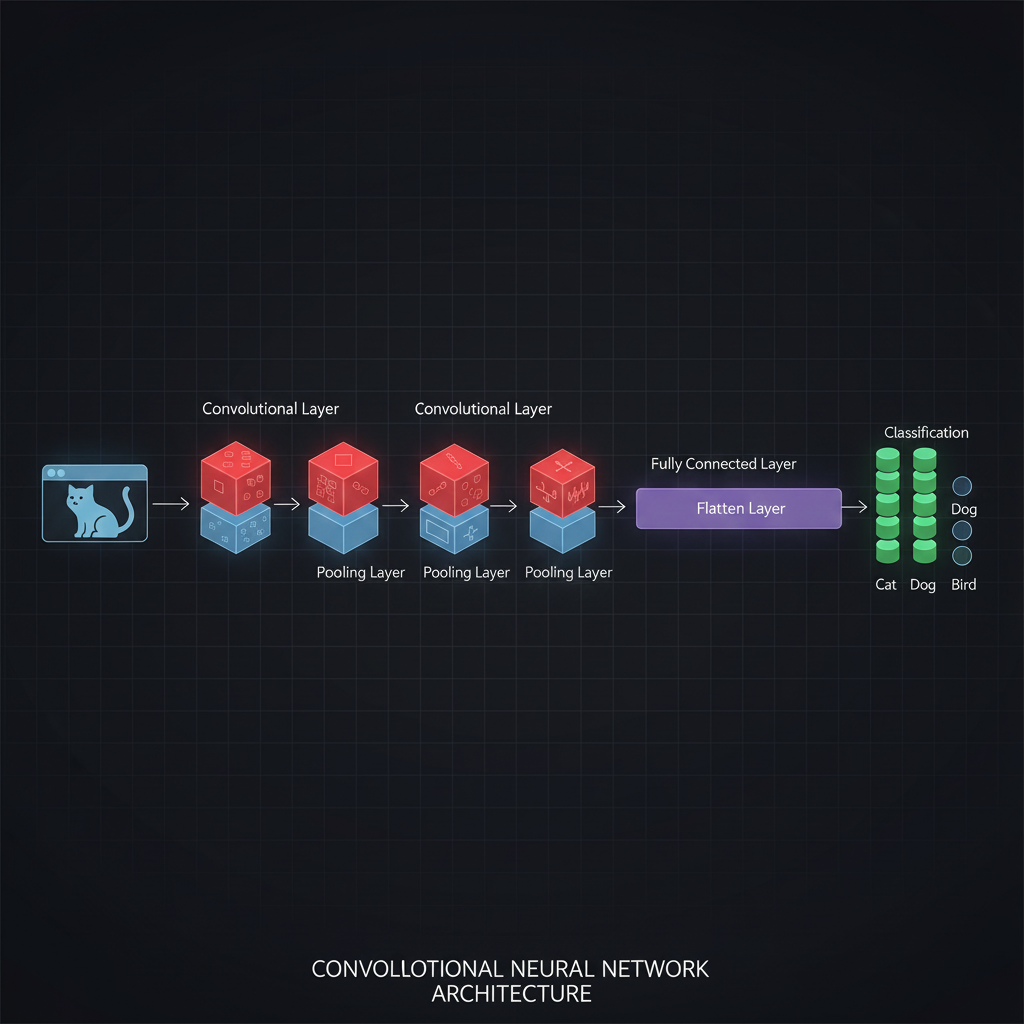
- 1. โครงสร้างแบบ 3 มิติ (3D Volume Structure): ต่างจาก MLP ที่เรียงนิวรอนเป็นเส้นตรงบางๆ ใน CNN เลเยอร์จะถูกจัดเรียงในรูปแบบ 3 มิติ คือ ความกว้าง (Width), ความสูง (Height), และ ความลึก (Depth) โดยความลึกในที่นี้ไม่ได้หมายถึงจำนวนเลเยอร์นะครับ แต่หมายถึง “จำนวนแชนเนล (Channels)” หรือ Feature Maps ที่ใช้สกัดคุณลักษณะต่างๆ จากภาพ
- 2. การเชื่อมต่อเฉพาะที่ (Local Connectivity): นิวรอนใน CNN จะไม่เชื่อมต่อกับทุกพิกเซลในภาพ (Sparse connections) แต่มันจะเชื่อมต่อกับพิกเซลแค่กลุ่มเล็กๆ (เช่น ขนาด 3x3) ที่เรียกว่า Receptive Field เปรียบเหมือนการใช้แว่นขยายกวาดดูรายละเอียดไปทีละส่วนของภาพ ทำให้ลดภาระการคำนวณลงไปได้มหาศาล
- 3. การใช้ค่าน้ำหนักร่วมกัน (Weight Sharing): นิวรอนทั้งหมดที่อยู่ใน Feature Map เดียวกัน จะใช้ “ชุดค่าน้ำหนัก (Weights/Filters)” ชุดเดียวกันเป๊ะกวาดไปทั่วทั้งภาพ สิ่งนี้สร้างเวทมนตร์ที่เรียกว่า Translation Invariance (ความทนทานต่อการเลื่อนตำแหน่ง) นั่นคือ ไม่ว่าหน้าน้องหมาจะอยู่มุมซ้ายหรือมุมขวาของรูป โมเดลก็ยังสามารถตรวจจับได้เสมอ เพราะมันใช้ฟิลเตอร์ตัวเดียวกันกวาดหาจนเจอนั่นเอง
- 4. การเรียนรู้แบบลำดับขั้น (Hierarchical Compositionality): เมื่อเรานำ Convolutional Layers มาซ้อนกันหลายๆ ชั้น โครงสร้างนี้จะทำงานคล้ายสมองมนุษย์ครับ ชั้นแรกๆ จะเรียนรู้แค่เส้นขอบ (Edges) หรือจุดสี ชั้นกลางๆ จะนำเส้นเหล่านั้นมาประกอบเป็นรูปทรง (Shapes) ชั้นลึกๆ จะนำรูปทรงมาประกอบร่างเป็นวัตถุซับซ้อน (Complex objects) เช่น ใบหน้าคน หรือล้อรถยนต์
- 5. รูปแบบการจัดวางเลเยอร์ (Architecture Patterns):
สถาปัตยกรรม CNN มาตรฐาน มักจะเรียงสลับกันเป็นแพทเทิร์นสุดคลาสสิก:
INPUT => [[CONV => RELU]*N => POOL?]*M => [FC => RELU]*K => FCโดยแบ่งเป็น 2 ส่วนหลักคือ Feature Extraction (สกัดจุดเด่นด้วย CONV + POOL) และ Classification (ฟันธงผลลัพธ์ด้วย FC)
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้เห็นภาพว่าสถาปัตยกรรม CNN ที่มีเลเยอร์แบบ 3 มิตินี้ ถูกเขียนออกมาเป็นโค้ดจริงๆ ได้อย่างไร ลองดูตัวอย่างการสร้างโมเดลด้วย Keras/TensorFlow สำหรับจำแนกภาพแบบง่ายๆ กันครับ (อิงจากแพทเทิร์นคลาสสิก):
import tensorflow as tf
from tensorflow.keras import layers, models
# 1. นิยามสถาปัตยกรรมแบบ Sequential (เรียงต่อกันเป็นชั้นๆ)
model = models.Sequential([
# -------------------------------------------------------------
# 📌 ส่วนที่ 1: Feature Extraction (สกัดคุณลักษณะ)
# -------------------------------------------------------------
# เลเยอร์รับข้อมูลภาพ 3 มิติ (เช่น กว้าง 32, สูง 32, ลึก 3 คือ RGB)
# ใช้แว่นขยาย (Kernel) ขนาด 3x3 จำนวน 32 อัน (Filters) กวาดไปทั่วภาพ
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3), name='Conv_1'),
# ย่อขนาดภาพให้เล็กลงครึ่งนึง เพื่อดึงเฉพาะจุดเด่นที่สำคัญ (Spatial reduction)
layers.MaxPooling2D((2, 2), name='Pool_1'),
# เพิ่มความลึกของ Network โดยใช้ 64 Filters เพื่อหาสิ่งที่ซับซ้อนขึ้น
layers.Conv2D(64, (3, 3), activation='relu', name='Conv_2'),
layers.MaxPooling2D((2, 2), name='Pool_2'),
layers.Conv2D(64, (3, 3), activation='relu', name='Conv_3'),
# -------------------------------------------------------------
# 📌 ส่วนที่ 2: Classification (ตัดสินใจแยกแยะประเภท)
# -------------------------------------------------------------
# เมื่อสกัดฟีเจอร์เสร็จ ต้องยืดข้อมูล 3 มิติให้กลับมาเป็น 1 มิติ (Flatten)
layers.Flatten(name='Flatten'),
# ส่งเข้าสู่ Fully Connected Layer (MLP แบบดั้งเดิม)
layers.Dense(64, activation='relu', name='Dense_1'),
# ชั้นตัดสินใจสุดท้าย สมมติว่ามี 10 คลาส (เช่น CIFAR-10)
layers.Dense(10, activation='softmax', name='Output')
])
# ลองปริ้นท์ดูโครงสร้าง จะเห็นว่ามิติ กว้างxยาว จะเล็กลง แต่มิติ ความลึก จะเพิ่มขึ้นเรื่อยๆ!
model.summary()5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
จากประสบการณ์ของพี่ มีเทคนิคขั้นสูงเกี่ยวกับสถาปัตยกรรม CNN ที่อยากฝากไว้ครับ:
- กฎแห่งมิติภาพ (Depth increases, dimensions decrease): ถ้าน้องออกแบบ CNN ได้ถูกต้อง น้องจะสังเกตเห็นว่ายิ่งเลเยอร์ลึกขึ้น ความกว้างและความสูงของภาพ (Width x Height) จะต้อง “เล็กลงเรื่อยๆ” (ผ่านกระบวนการ Pooling หรือ Stride) แต่ความลึก (Depth หรือจำนวน Feature maps) จะต้อง “เพิ่มขึ้นเรื่อยๆ” (เช่น จาก 32 -> 64 -> 128) เพื่อเปิดพื้นที่ให้มันจำฟีเจอร์ที่ซับซ้อนได้
- ทำลายล้าง Fully Connected (The Fully Convolutional Network - FCN): ในงานขั้นสูงอย่าง Semantic Segmentation (การระบายสีแยกวัตถุทุกพิกเซล) นักวิจัยพบว่าชั้น Fully Connected (Dense) ตอนท้ายมันทำให้สูญเสียตำแหน่งพิกเซล (Spatial details) ไปหมด เขาเลยใช้วิธีเปลี่ยนชั้น Dense ทิ้ง แล้วยัด
Conv2Dที่มีขนาด 1x1 เข้าไปแทน! สถาปัตยกรรมแบบนี้เรียกว่า FCN ซึ่งฉลาดกว่าและคำนวณเร็วกว่ามากครับ - 1x1 Convolutions (The Bottleneck): บางครั้งในสถาปัตยกรรมลึกๆ อย่าง GoogLeNet น้องจะเห็นการใช้ Convolution ขนาด 1x1… ฟังดูแปลกใช่ไหมครับ แว่นขยายขนาด 1x1 จะไปมองเห็นอะไร? ความจริงคือมันไม่ได้ใช้ดูภาพครับ แต่มันใช้เพื่อ “บีบอัดความลึก (Depth)” (ลดมิติแชนเนลข้ามเลเยอร์) เพื่อลดจำนวนพารามิเตอร์และการคำนวณลงอย่างมหาศาล เรียกว่าเทคนิค Bottleneck ครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Convolutional Neural Networks (CNN) คือสถาปัตยกรรมที่ก้าวเข้ามาปฏิวัติวงการ AI ให้มีความสามารถในการมองเห็นโลกทัศน์แบบเดียวกับมนุษย์ ด้วยกลไกการสกัดจุดเด่นผ่าน Local Connectivity, การประหยัดทรัพยากรด้วย Weight Sharing, และการเรียนรู้แบบสร้างลำดับชั้นจากความเรียบง่ายสู่ความซับซ้อน (Compositionality) ทำให้มันกลายเป็นมาตรฐาน (Standard) ของงาน Computer Vision ไปโดยปริยาย
เมื่อน้องๆ เข้าใจโครงสร้างภาพรวมของ CNN แล้ว ในบทความถัดไป พี่จะพาน้องๆ ไปแกะกล่องดูเครื่องมือชิ้นสำคัญภายใน CNN แบบเจาะลึก นั่นก็คือ Convolutional Layers ว่าคณิตศาสตร์เบื้องหลังการกวาดฟิลเตอร์และการทำ Zero-padding มันทำงานอย่างไร รอติดตามความสนุกได้เลยครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p