ถอดรหัส Adam Optimizer: เครื่องยนต์อัจฉริยะที่พา AI ไต่ลงเขาหาจุดต่ำสุด

1. 🎯 ตอนที่ 20: ถอดรหัส Adam Optimizer เครื่องยนต์อัจฉริยะที่พา AI ไต่ลงเขา
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกคน! ชงกาแฟเข้มๆ แล้วมาล้อมวงกันต่อครับ ในตอนที่แล้วเราได้รู้จักกับไม้เรียวของ AI อย่าง Loss Function กันไปแล้ว ซึ่งมันคอยทำหน้าที่บอกว่าโมเดลของเรา “ทำงานพลาดไปเท่าไหร่”
แต่การจะทำให้ AI เก่งขึ้นได้นั้น เราต้องการ “พาหนะ” หรือ “เครื่องยนต์” ที่จะรับเอาค่าความผิดพลาดนั้นมาปรับแก้ค่าน้ำหนัก (Weights) ของเครือข่ายประสาทเทียม ในบริบทของการฝึกฝนโมเดล (Model Training) เราเรียกเครื่องยนต์เหล่านี้ว่า Optimization Algorithms (อัลกอริทึมการหาค่าเหมาะที่สุด) และวันนี้พี่จะพาไปรู้จักกับสุดยอดเครื่องยนต์ที่วิศวกร AI ทั่วโลกนิยมใช้กันมากที่สุด ซึ่งก็คือ Adam (Adaptive Moment Estimation) ครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องกำลังหลงทางอยู่บนยอดเขาที่สลับซับซ้อนและมีหมอกลงจัดมากๆ น้องมองไม่เห็นทางข้างหน้าเลย แต่เป้าหมายของน้องคือการเดินลงไปให้ถึง “ก้นหุบเขาที่ต่ำที่สุด (Global Minimum)” ซึ่งเปรียบเสมือนจุดที่ Error หรือ Loss Function มีค่าน้อยที่สุด
ถ้าน้องใช้วิธีพื้นฐานอย่าง Gradient Descent น้องก็จะใช้เท้าคลำหาความชันรอบๆ ตัว ถ้ารู้สึกว่าทางไหนลาดลง ก็ก้าวไปทางนั้น 1 ก้าว ปัญหาคือ ถ้าน้องก้าวสั้นไป (Learning rate ต่ำ) น้องอาจจะใช้เวลาเป็นปีกว่าจะถึงก้นหุบเขา หรือถ้าน้องเจอกับหลุมบ่อเล็กๆ (Local minima) ระหว่างทาง น้องก็อาจจะติดอยู่ในนั้นตลอดกาล!
นักวิจัยจึงพยายามคิดค้นวิธีเดินลงเขาที่ฉลาดขึ้นเรื่อยๆ จนกระทั่งกำเนิดอัลกอริทึม Adam ขึ้นมา ซึ่งเปรียบเสมือนน้องมีรองเท้าสเก็ตติดเซนเซอร์ ที่ไม่เพียงแต่จำแรงส่งจากก้าวที่แล้วได้ (ช่วยให้พุ่งทะลุหลุมบ่อ) แต่ยังสามารถปรับความกว้างของก้าวเดินให้เหมาะกับสภาพพื้นผิวแต่ละแบบได้อัตโนมัติ! นี่แหละครับคือเวทมนตร์ที่ทำให้ Adam กลายเป็นฮีโร่ของยุคนี้
3. 🧠 แก่นวิชา (Core Concepts)
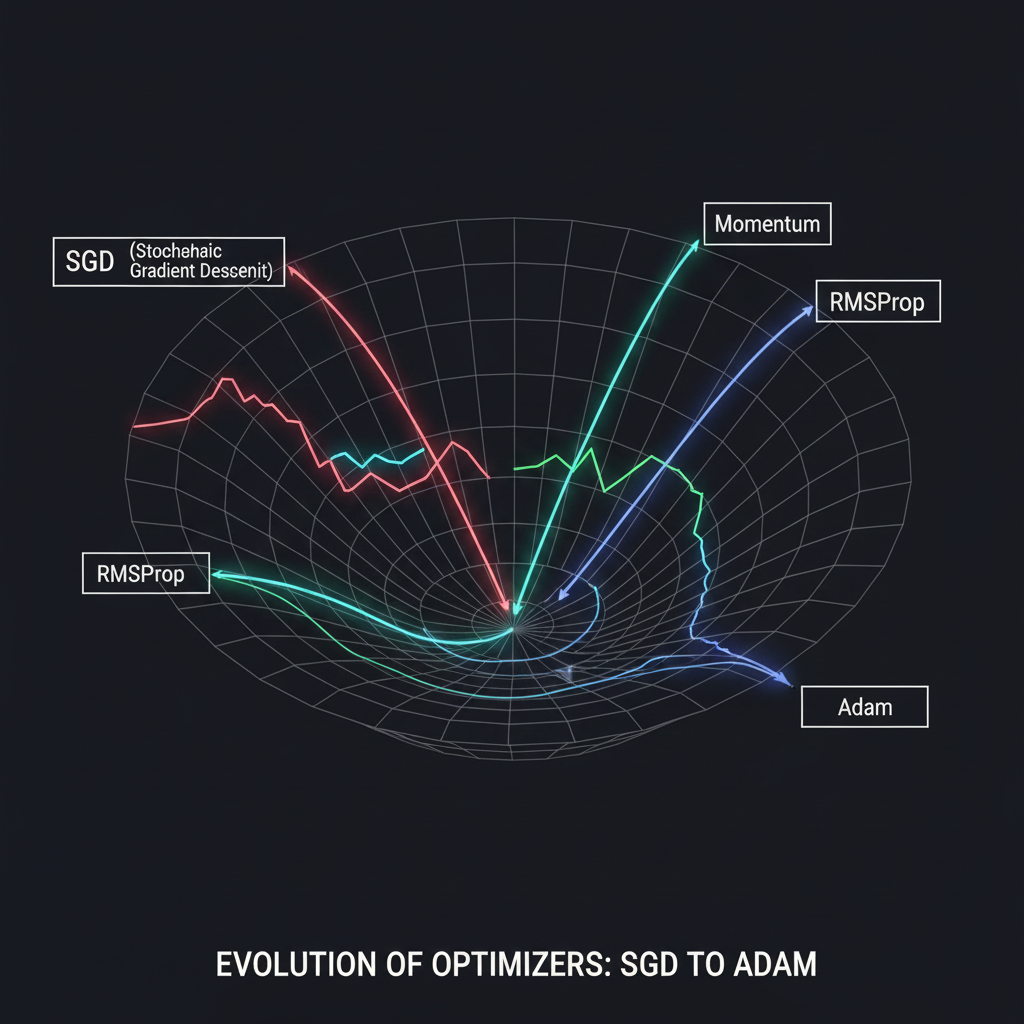
เพื่อให้เข้าใจว่า Adam ทรงพลังแค่ไหน แหล่งข้อมูลระดับโลกได้อธิบายวิวัฒนาการของ Optimizers ในบริบทของการ Training ไว้ดังนี้ครับ:
- 1. ยุคหิน: Stochastic Gradient Descent (SGD): นี่คืออัลกอริทึมพื้นฐานที่สุด โดยมันจะคลำหาความชันแล้วอัปเดตน้ำหนักแบบตรงไปตรงมา แต่เวลาเดินมันมักจะเกิดอาการ “แกว่งไปมาแบบซิกแซก (Noisy/Zigzag)” ทำให้เสียเวลามากเมื่อเจอกับหุบเขาที่มีความชันไม่เท่ากัน
- 2. ยุคเหล็ก: SGD with Momentum (เพิ่มแรงเฉื่อย): เพื่อแก้ปัญหาการแกว่ง นักวิจัยจึงเพิ่ม Momentum เข้าไป ไอเดียนี้เหมือนกับน้องปั้น “ก้อนหิมะ” กลิ้งลงเขาครับ ยิ่งกลิ้งลงทิศทางเดิมนานๆ ก้อนหิมะก็ยิ่งสะสมแรงเฉื่อยและพุ่งเร็วขึ้น ช่วยให้ทะลุผ่านจุดราบเรียบหรือหลุมพรางไปได้สบายๆ
- 3. ยุคทองแดง: RMSProp (ปรับก้าวเดินอัตโนมัติ): บางครั้งทางเดินก็ชันเกินไปจนก้อนหิมะพุ่งตกเหว อัลกอริทึม RMSProp จึงถูกคิดค้นขึ้นมาเพื่อปรับ “อัตราการเรียนรู้ (Learning Rate)” แบบอัตโนมัติ โดยมันจะเก็บข้อมูลความชันในอดีต (Squared gradients) มาหารทอนกำลัง หากมันกำลังเดินบนแกนที่ชันมากๆ มันจะก้าวสั้นลงเพื่อความปลอดภัย และถ้าเป็นแกนที่ราบเรียบ มันจะก้าวให้ยาวขึ้น
- 4. ยุคปัจจุบัน: Adam (สุดยอดการผสมผสาน): Adam (Adaptive Moment Estimation) เกิดจากการเอาข้อดีของ Momentum (การจำทิศทางในอดีต) และ RMSProp (การปรับขนาดก้าวเดินตามสภาพพื้นผิว) มาผสมรวมกันครับ! พฤติกรรมของ Adam จะเหมือนกับ “ลูกเหล็กหนักๆ ที่มีแรงเสียดทานคอยเบรก (Heavy ball with friction)” ทำให้มันพุ่งลงเขาได้อย่างรวดเร็ว แต่ก็ไม่แหกโค้งเมื่อเจอทางลาดชัน ด้วยคุณสมบัตินี้ Adam จึงเป็น Optimizer ที่ทำให้โมเดลลู่เข้าหาคำตอบ (Converge) ได้อย่างรวดเร็วและเสถียรที่สุดในปัจจุบัน
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในการใช้งานจริงผ่าน Keras/TensorFlow การเรียกใช้ Adam นั้นง่ายมากครับ และที่สำคัญคือ “ค่าเริ่มต้น (Default parameters)” ที่ผู้คิดค้นแนะนำมานั้น มักจะใช้งานได้ดีจนเราแทบไม่ต้องไปจูนอะไรเพิ่มเลย (นอกจาก Learning rate) ลองดูโค้ดกันครับ:
import tensorflow as tf
from tensorflow.keras import layers, models, optimizers
# สร้างสถาปัตยกรรมโมเดลแบบง่ายๆ
model = models.Sequential([
layers.Dense(128, activation='relu', input_shape=(784,)),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
# -------------------------------------------------------------
# 📌 การประกาศใช้งาน Adam Optimizer
# - learning_rate: ก้าวเดินเริ่มต้น (ปกติจะเริ่มที่ 0.001 สำหรับ Adam)
# - beta_1 (0.9): ตัวควบคุม Momentum (ความจำทิศทาง)
# - beta_2 (0.999): ตัวควบคุม RMSProp (ความจำความชันเพื่อปรับขนาดก้าว)
# - epsilon (1e-7): ค่าคงที่เล็กๆ เพื่อป้องกันการหารด้วยศูนย์
# -------------------------------------------------------------
adam_opt = optimizers.Adam(learning_rate=0.001,
beta_1=0.9,
beta_2=0.999,
epsilon=1e-07)
# สั่งให้โมเดลใช้ Adam ในกระบวนการ Training
model.compile(optimizer=adam_opt,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# เริ่มลูปการฝึกสอน
history = model.fit(X_train, y_train, epochs=20, batch_size=32)5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ถึงแม้พี่จะอวยว่า Adam คือพระเอก แต่ในโลกของวิศวกรหน้างาน เราต้องรู้จุดอ่อนและวิธีเลือกใช้เครื่องมือให้เหมาะสมกับงานครับ:
- Adam คือตัวเลือกแรกเสมอ (The Default Choice): ถ้าน้องเริ่มทำโปรเจกต์ Deep Learning ใหม่ๆ ไม่ว่าจะเป็นงานภาพ หรือ งานประมวลผลภาษา (NLP) ให้เริ่มใช้ Adam ก่อนเสมอครับ เพราะมันมี Adaptive Learning Rate ในตัว ทำให้เราไม่ต้องเสียเวลาจูน Learning rate ให้เหนื่อยมากเหมือนตอนใช้ SGD
- เมื่อไหร่ที่ควรกลับไปซบอก SGD?: มีงานวิจัยบางชิ้นพบว่า แม้ Adam จะเทรนได้เร็วและลู่เข้าหาคำตอบไว แต่ในบาง Dataset (โดยเฉพาะงาน Image Classification แบบซับซ้อน) โมเดลที่ใช้ SGD + Momentum มักจะทำคะแนนตอนเจอข้อมูลจริง (Generalization) ได้ดีกว่า Adam เล็กน้อย! ดังนั้น หากน้องจูน Adam จนสุดทางแล้วแต่รู้สึกว่าโมเดลยังไม่ทะลุขีดจำกัด ให้ลองสลับกลับไปใช้ SGD(momentum=0.9) ควบคู่กับการลด Learning rate ตามรอบ (Learning Rate Scheduling) ดูครับ
- ทายาทของ Adam: ปัจจุบันมีการพัฒนาต่อยอด Adam ออกไปอีก เช่น Nadam (ใส่เทคนิค Nesterov acceleration เข้าไปเพื่อมองข้ามช็อตล่วงหน้า) หรือ AdamW (แยกการคำนวณ Weight Decay ออกมาต่างหากเพื่อลดปัญหา Overfitting) ซึ่งก็เป็นตัวเลือกที่น่าสนใจในไลบรารียุคใหม่ครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Adam (Adaptive Moment Estimation) คือ อัลกอริทึม Optimization ระดับเรือธงในกระบวนการ Training Model มันทำหน้าที่ผสานสุดยอดแนวคิดการปรับแรงเฉื่อย (Momentum) เข้ากับการปรับขนาดก้าวเดินแบบอัตโนมัติ ทำให้ AI ของเราสามารถไต่ลงหุบเขาแห่ง Loss Function ไปหาความแม่นยำสูงสุดได้อย่างรวดเร็วและปลอดภัยที่สุด
เมื่อเรารู้จักเครื่องยนต์ (Adam), ไม้เรียว (Loss Function), และคาถาย้อนเวลา (Backpropagation) ครบถ้วนแล้ว ในตอนต่อไป เราจะมาคุยกันเรื่อง “การจัดเตรียมข้อมูล” ก่อนป้อนเข้าโมเดลกันบ้าง โดยเฉพาะเทคนิคสำคัญอย่าง Batch Normalization ที่จะช่วยให้เครื่องยนต์ Adam ของเราทำงานได้ลื่นไหลยิ่งขึ้นไปอีก! รอติดตามนะครับ
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p