ผ่าไม้เรียวของ AI: เข้าใจ Cross-Entropy Loss กลไกชี้วัดความผิดพลาดเพื่อฝึกฝนสมองกล

1. 🎯 ตอนที่ 19: ผ่าไม้เรียวของ AI ทำความรู้จัก Cross-Entropy Loss
สวัสดีครับน้องๆ วิศวกรและนักพัฒนา AI ทุกคน! มาล้อมวงจิบกาแฟกันต่อครับ หลังจากที่เราได้สร้างสถาปัตยกรรม (Architecture) และใส่ประตูกล (Activation Functions) ให้กับโครงข่ายประสาทเทียมของเราแล้ว คำถามถัดมาคือ… “เราจะสอนให้มันฉลาดขึ้นได้อย่างไร?”
ในการทำงานหน้างานจริง สมมติเราให้ AI ทายว่าชิ้นงานบนสายพานคือ “น็อตดี” หรือ “น็อตเสีย” ถ้ายิ่งทายผิด AI ก็ต้องยิ่งถูกทำโทษแรงๆ เพื่อให้มันปรับปรุงตัวใช่ไหมครับ? สิ่งที่ทำหน้าที่เป็น “ไม้เรียว” คอยตีกรอบและวัดระดับความผิดพลาดนี้ เราเรียกว่า Loss Function (ฟังก์ชันความสูญเสีย) ครับ และในบทความนี้ พี่จะพาไปเจาะลึกฮีโร่ของฝั่งงาน Classification ที่ชื่อว่า Cross-Entropy ว่ามันเข้ามาขับเคลื่อนกระบวนการ Model Training (การฝึกฝนโมเดล) ได้อย่างไร!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องกำลังเป็นหัวหน้างาน (Supervisor) คอยฝึกพนักงาน QC คนใหม่ (สมองกลของเรา) พนักงานหยิบน็อตเสียขึ้นมา 1 ตัว แล้วบอกน้องว่า “พี่ครับ ผมมั่นใจ 80% ว่านี่คือน็อตดี!”
ในฐานะหัวหน้า น้องจะทำแค่บอกว่า “ผิด!” เฉยๆ ไม่ได้ครับ น้องต้องมี “มาตรวัด” ว่าเขาตอบห่างไกลจากความเป็นจริงแค่ไหน (ความจริงคือ น็อตดี = 0%, น็อตเสีย = 100%) ยิ่งพนักงานมั่นใจในคำตอบที่ผิดมากเท่าไหร่ น้องยิ่งต้องลงโทษหนักขึ้นเท่านั้น เพื่อให้รอบหน้าเขาไปปรับจูนสายตา (ปรับ Weights) ของตัวเองใหม่
ในโลกของ Deep Learning กระบวนการฝึกฝนโมเดล (Model Training) ขับเคลื่อนด้วยวัฏจักร 4 ขั้นตอนครับ:
- Forward Pass: โมเดลรับรูปภาพเข้ามา แล้วทำนายผลออกมาเป็นเปอร์เซ็นต์ (เช่น มั่นใจ 80% ว่าเป็นน็อตดี)
- Loss Calculation: นำเปอร์เซ็นต์นั้นมาเทียบกับ “เฉลย (Ground Truth)” แล้วคำนวณออกมาเป็นตัวเลขความผิดพลาดผ่าน Loss Function
- Backward Pass (Backpropagation): นำค่าความผิดพลาดนั้น ส่งย้อนกลับไปในเครือข่ายเพื่อหาความชัน (Gradients)
- Weight Update: ใช้อัลกอริทึม Optimization เพื่ออัปเดตค่าน้ำหนัก (Weights) ให้รอบหน้าทายแม่นยำขึ้น
คำถามคือ เราจะใช้สมการคณิตศาสตร์อะไรมาเป็น Loss Function ดี? สำหรับงานภาพ (Computer Vision) ที่ต้องจัดหมวดหมู่ คำตอบระดับมาตรฐานอุตสาหกรรมก็คือ Cross-Entropy Loss นั่นเองครับ!
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทที่กว้างขึ้นของการฝึกฝนโมเดล แหล่งข้อมูลระดับโลกได้อธิบายบทบาทของ Loss Functions ไว้ดังนี้ครับ:
1. หน้าที่ของ Loss Function: เป้าหมายสูงสุดของการ Training คือการแก้ปัญหา Optimization (การหาค่าต่ำสุด) เราต้องการหาชุดค่าน้ำหนัก (Weights) ที่ทำให้ผลลัพธ์ของฟังก์ชันความสูญเสีย (Loss Function) มีค่าเข้าใกล้ 0 มากที่สุด ค่า Loss ที่สูงแปลว่าโมเดลทำงานแย่ ค่า Loss ที่ต่ำแปลว่าโมเดลทำนายได้ใกล้เคียงความจริง
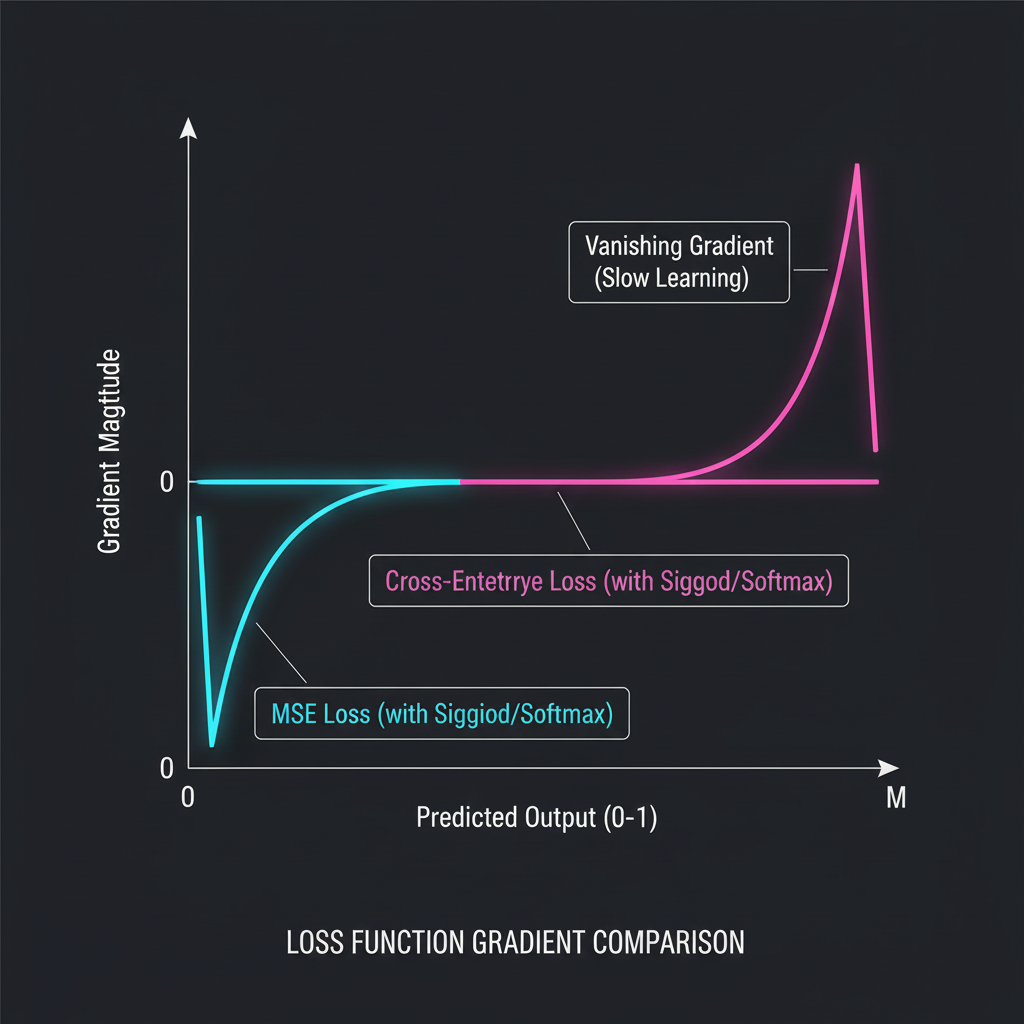
2. ทำไมถึงไม่ใช้ Mean Squared Error (MSE)? หลายคนอาจจะคุ้นเคยกับ MSE (การเอาค่าทำนายมาลบค่าจริงแล้วยกกำลังสอง) จากงาน Linear Regression แต่ถ้านำ MSE มาใช้กับเครือข่ายประสาทที่มีเอาต์พุตเป็น Sigmoid หรือ Softmax จะเกิดหายนะที่เรียกว่า Vanishing Gradient (ความชันจางหาย) ครับ! เพราะเวลาที่นิวรอนตอบผิดแบบสุดกู่ ค่าของมันจะไปตกอยู่ในขอบที่แบนราบ (Saturation region) ของกราฟ Sigmoid ทำให้ค่าอนุพันธ์ (Derivative) มีค่าเข้าใกล้ 0… พอ Error ส่งกลับไปหา Backpropagation เจอเลข 0 คูณเข้าไป โมเดลเลย “หยุดเรียนรู้” ดื้อๆ ซะอย่างงั้น!
3. ฮีโร่นามว่า Cross-Entropy (Log Loss): เพื่อแก้ปัญหาเซลล์ประสาทหยุดเรียนรู้ เราจึงใช้ Cross-Entropy ครับ แนวคิดนี้มาจากทฤษฎีข้อมูล (Information Theory) ที่ใช้วัดว่า การแจกแจงความน่าจะเป็นของการทำนาย (Predicted probabilities) นั้น แตกต่างจากการแจกแจงที่แท้จริง (True distribution) มากน้อยแค่ไหน สมการพื้นฐานสำหรับ Multiclass Classification สำหรับ 1 ข้อมูล คือ:
$$ L = - \sum_{j} y_j \log(\hat{y}_j) $$
โดยที่ $y_j$ คือเฉลยความน่าจะเป็น (มักจะเป็น 0 หรือ 1) และ $\hat{y}_j$ คือความน่าจะเป็นที่โมเดลทำนายได้
4. พลังเวทมนตร์ของ Logarithm: ความเจ๋งของ Cross-Entropy คือมันใช้ฟังก์ชันลอการิทึม ($\log$) ครับ ถ้าน้องทายผิดแบบหลงทิศ (ทำนายเข้าใกล้ 0 ในขณะที่เฉลยคือ 1) ค่า $\log(0)$ จะพุ่งดิ่งติดลบมหาศาล (-Infinity) และเมื่อเจอกับเครื่องหมายลบด้านหน้า ค่า Loss จึง สูงปรี๊ด! เป็นการทำโทษโมเดลอย่างรุนแรง ทำให้ความชัน (Gradient) ชันขึ้น และเจาะทะลุภาวะสมองตีบตัน (Saturation) ของ Sigmoid/Softmax ไปได้ ทำให้กระบวนการฝึก (Training) กลับมารวดเร็วและมีประสิทธิภาพอีกครั้งครับ!
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในการทำงานจริงด้วย Keras/TensorFlow เราไม่ต้องมานั่งเขียนสมการ Log หรือดิฟสมการเองให้ปวดหัวครับ ระบบได้รวม Loss Function นี้ไว้ให้พร้อมเรียกใช้งานตอนที่เรา compile โมเดลเพื่อเข้าสู่ Training Loop:
import tensorflow as tf
from tensorflow.keras import layers, models
# 1. สร้างโมเดล (สมมติว่าเป็น CNN สำหรับแยกประเภทของเสีย 5 หมวดหมู่)
model = models.Sequential([
layers.Flatten(input_shape=(64, 64, 3)),
layers.Dense(128, activation='relu'),
# ชั้น Output ชี้ขาด ใช้ Softmax เพื่อให้ออกมาเป็นความน่าจะเป็น
layers.Dense(5, activation='softmax')
])
# 2. เตรียมเข้าห้องฝึกสอน (Training Phase)
# 📌 หัวใจสำคัญ: เลือก Optimizer และ Loss Function ให้เหมาะสม!
model.compile(optimizer='adam',
# งานแยกหลายคลาส ต้องจับคู่กับ Categorical Crossentropy!
loss='categorical_crossentropy',
metrics=['accuracy'])
# 3. เริ่มลูปการเรียนรู้ (Training Loop)
history = model.fit(X_train, y_train,
epochs=20,
batch_size=32,
validation_split=0.2)คอมเมนต์: สังเกตว่าในตอนเรา .compile() การประกาศ loss='categorical_crossentropy' นี่แหละครับคือการสั่งให้ Framework คำนวณความผิดพลาดด้วย Log Loss ก่อนจะส่งผลลัพธ์ย้อนกลับ (Backpropagate) ไปปรับน้ำหนักโมเดล
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในฐานะคนทำระบบหน้างานจริง พี่มีกฎเหล็กเกี่ยวกับการเลือกใช้ Loss Function ในช่วง Training มาฝากครับ จำให้ขึ้นใจเลยนะ:
- คู่สร้างคู่สม (The Dynamic Duos): เราไม่สามารถเลือก Activation Function ฝั่ง Output กับ Loss Function มั่วซั่วได้ครับ มันต้องจับคู่กันตามหลักคณิตศาสตร์:
- Binary Classification (แยกแค่ 2 อย่าง เช่น ผ่าน/ไม่ผ่าน): ใช้
Sigmoidควบคู่กับbinary_crossentropy - Multiclass Classification (แยกของหลายประเภท): ใช้
Softmaxควบคู่กับcategorical_crossentropy(ถ้า label เป็น One-hot) หรือsparse_categorical_crossentropy(ถ้า label เป็นตัวเลข Integer) - Regression (ทายค่าตัวเลขต่อเนื่อง เช่น ทายราคา หรือขนาด): ใช้
Linear(ไม่มี Activation) ควบคู่กับMean Squared Error (MSE)หรือMAE
- Binary Classification (แยกแค่ 2 อย่าง เช่น ผ่าน/ไม่ผ่าน): ใช้
- อาการ Loss ไม่ยอมลง: ถ้าน้องๆ Train โมเดลไปแล้ว ค่า Loss นิ่งสนิท ไม่ยอมขยับลงตั้งแต่ Epoch แรกๆ ให้รีบเช็คเลยครับว่าน้องเผลอเอา Output แบบ Softmax ไปจับคู่กับ Loss แบบ MSE หรือเปล่า เพราะถ้าจับคู่ผิด โมเดลน้องจะเจอคำสาป Vanishing Gradient ทันที!
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Loss Function เปรียบเสมือน “เข็มทิศและไม้เรียว” ในวัฏจักรการฝึกฝน (Model Training) หากไม่มีมัน อัลกอริทึม Backpropagation ก็จะไม่รู้เลยว่าต้องปรับค่าน้ำหนัก (Weights) ไปในทิศทางไหน
และสำหรับงานประมวลผลภาพที่เป็นการแยกหมวดหมู่ (Classification) Cross-Entropy ได้รับการพิสูจน์แล้วว่าเป็นสมการที่สมบูรณ์แบบที่สุด เพราะคุณสมบัติของ Logarithm ช่วยทำโทษข้อผิดพลาดได้อย่างเด็ดขาด ทำให้เครือข่ายประสาทสามารถหลุดพ้นจากหลุมพรางความชันหาย (Vanishing Gradient) และเรียนรู้ได้อย่างรวดเร็วครับ
ในตอนถัดไป เมื่อเรารู้เป้าหมาย (Loss) และรู้ทิศทาง (Backprop) แล้ว เราจะมาเจาะลึกที่ “พาหนะ” ที่พาเราพุ่งชนเป้าหมายกันบ้าง ซึ่งก็คือ Optimization Algorithms (เช่น SGD และ Adam) ว่าพวกมันมีเทคนิคการก้าวเดินลงเขาอย่างไรให้ไปถึงจุดต่ำสุดได้ไวและเสถียรที่สุด ห้ามพลาดเด็ดขาดครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p