ผ่าความลับ Gradient Descent (SGD): อัลกอริทึมไต่เขาที่ขับเคลื่อนโลก Deep Learning

1. 🎯 ตอนที่ 18: ผ่าความลับ Gradient Descent (SGD) อัลกอริทึมไต่เขาที่ขับเคลื่อนโลก
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกคน! มาล้อมวงจิบกาแฟกันต่อครับ หลังจากที่เราได้พูดถึงภาพรวมของ “การฝึกฝนโมเดล (Model Training)” และกลไกย้อนกลับอย่าง Backpropagation กันไปแล้ว วันนี้พี่จะพามาเจาะลึกพระเอกตัวจริงที่เป็น “เครื่องยนต์ (Engine)” คอยขับเคลื่อนให้โครงข่ายประสาทเทียมเรียนรู้และฉลาดขึ้นได้จริง อัลกอริทึมนี้มีชื่อว่า Gradient Descent หรือที่ในยุคนี้เรามักจะคุ้นเคยกันในชื่อ Stochastic Gradient Descent (SGD) ครับ
เรามาดูกันว่า ในจักรวาลอันกว้างใหญ่ของการปรับจูนโมเดล (Optimization) อัลกอริทึมนี้ทำงานอย่างไร ทำไมมันถึงถูกเปรียบเทียบว่าเหมือน “คนตาบอดเดินลงเขา” และทำไม SGD ถึงเอาชนะข้อจำกัดเดิมๆ จนกลายเป็นมาตรฐานของวงการ Machine Vision!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการตามพี่นะครับ สมมติว่าน้องกำลังหลงทางอยู่บนยอดเขาที่หมอกลงจัดมากๆ มองไม่เห็นอะไรเลยแม้แต่มือตัวเอง แต่น้องรู้ว่าหมู่บ้านที่ปลอดภัยอยู่ตรง “หุบเขาที่ต่ำที่สุด (Global Minimum)” น้องจะทำอย่างไรเพื่อเดินลงไปให้ถึงจุดนั้นครับ?
คำตอบคือ น้องก็ต้องใช้เท้า “คลำหาความชัน” ของพื้นดินรอบๆ ตัวใช่ไหมครับ? ถ้ารู้สึกว่าหันหน้าไปทางไหนแล้วพื้นมันลาดลงชันที่สุด น้องก็จะก้าวเท้าไปในทิศทางนั้น พอก้าวไปแล้วก็คลำใหม่ แล้วก็ก้าวต่อ ค่อยๆ ไต่ระดับลงไปเรื่อยๆ จนกว่าจะไปถึงพื้นราบที่ไม่มีความชันหลงเหลืออยู่ นั่นแปลว่าน้องถึงก้นหุบเขาแล้ว!
ในโลกของ Deep Learning ยอดเขาที่สลับซับซ้อนนั้นก็คือ Loss Function (ฟังก์ชันความสูญเสีย) ที่บอกว่าโมเดลของเราทำงานผิดพลาดแค่ไหน ส่วนพิกัดที่เรายืนอยู่ก็คือ “ค่าน้ำหนัก (Weights)” ของเครือข่ายประสาทเทียม กระบวนการ “คลำหาความชันแล้วก้าวลงทีละก้าว” นี่แหละครับ คือปรัชญาการทำงานที่งดงามและเรียบง่ายของ Gradient Descent
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทที่กว้างขึ้นของการฝึกฝนโมเดล (Model Training) แหล่งข้อมูลระดับโลกได้แบ่งสไตล์การเดินลงเขา (Optimization Algorithms) ของตระกูล Gradient Descent ออกเป็น 3 รูปแบบหลักๆ ดังนี้ครับ:
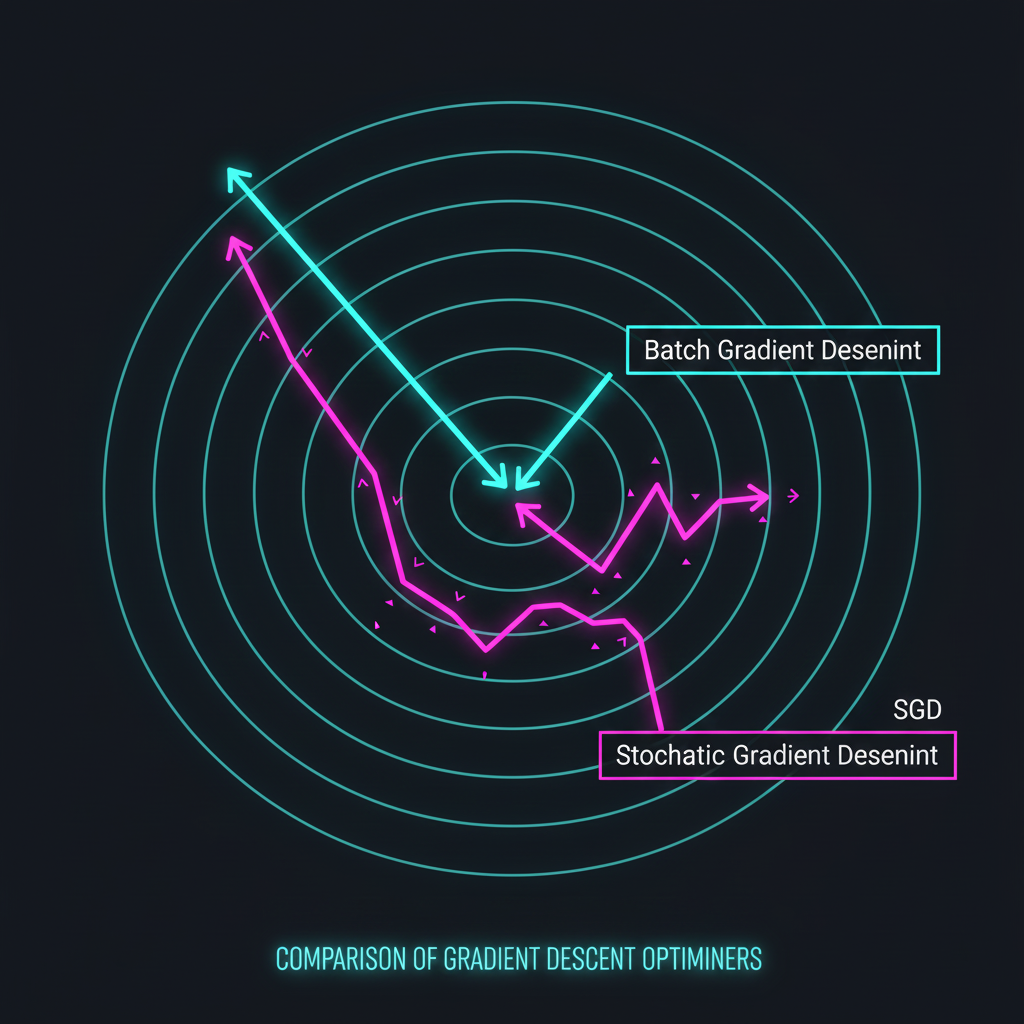
1. Batch Gradient Descent (BGD) - คนระมัดระวังตัว: วิธีนี้คือการนำข้อมูลภาพที่เรามี “ทั้งหมด (Entire Training Set)” มาคำนวณหาความผิดพลาดพร้อมๆ กัน เพื่อหาว่าทิศทางลาดลงที่แม่นยำที่สุดคือทางไหน แล้วจึงก้าว 1 ก้าว (อัปเดต Weights 1 ครั้ง) ข้อดี: ทางเดินจะสมูทมาก พุ่งตรงสู่เป้าหมาย ข้อเสีย: ถ้าน้องมีรูปภาพหมาแมวสัก 1 ล้านรูป กว่าคอมพิวเตอร์จะคำนวณครบ 1 ล้านรูปเพื่อขยับก้าวเดียว มันกินทรัพยากร (Memory) มหาศาลและช้าจนแทบขาดใจตายครับ!
2. Stochastic Gradient Descent (SGD) - คนใจร้อน: เมื่อ BGD มันช้า นักวิจัยจึงพลิกแพลงด้วย SGD คือแทนที่จะดูรูปทั้งหมด ก็ “สุ่มหยิบรูปมาแค่ 1 รูป (Single random instance)” มาคำนวณความชันแล้วอัปเดตน้ำหนักทันทีเลย! ผลลัพธ์: เร็วปรื๊ด! ทำให้อัปเดต Weights ได้ถี่มาก แต่ด้วยความที่ดูข้อมูลทีละรูป ทิศทางในการก้าวลงเขาจึงมีอาการ “แกว่งไปมาแบบซิกแซก (Noisy/Zigzag)” แต่มันก็ยังค่อยๆ ไหลลงไปถึงก้นหุบเขาได้ในที่สุด แถมความแกว่งนี้ยังช่วยให้มันกระโดดหลุดจากหลุมพราง (Local Minima) ได้ดีอีกด้วยครับ
3. Mini-batch Gradient Descent - ทางสายกลางแห่งอุตสาหกรรม: ในโลกการทำงานจริง (รวมถึงงาน Computer Vision) เราใช้วิธีนี้กันแทบจะ 100% ครับ มันคือจุดสมดุลระหว่าง BGD และ SGD โดยเราจะหยิบข้อมูลภาพมาเป็นกลุ่มเล็กๆ เรียกว่า Mini-batch (เช่น ทีละ 32, 64 หรือ 128 รูป) มาคำนวณแล้วก้าวทีละก้าว ทำไมถึงฮิต?: เพราะเราสามารถยัดภาพกลุ่มเล็กๆ เหล่านี้เข้า GPU เพื่อคำนวณคณิตศาสตร์เมทริกซ์ (Matrix Multiplication) แบบขนาน (Parallel) ได้อย่างมีประสิทธิภาพ ทำให้เดินได้เร็วและทิศทางไม่แกว่งจนเกินไปครับ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในการใช้ Framework อย่าง Keras/TensorFlow เราไม่ต้องมานั่งเขียนสมการหาอนุพันธ์ให้เหนื่อยเลยครับ การเรียกใช้ SGD และการกำหนดขนาด Mini-batch ทำได้ง่ายๆ ตอนที่เราเรียกใช้คำสั่ง compile และ fit ครับ:
import tensorflow as tf
from tensorflow.keras import layers, models, optimizers
# สร้างสถาปัตยกรรมโมเดลสำหรับแยกแยะของเสีย 2 คลาส
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(100,)),
layers.Dense(1, activation='sigmoid') # ออก Output เป็น ใช่/ไม่ใช่
])
# -------------------------------------------------------------
# 📌 หัวใจของการ Optimization: การประกาศเรียกใช้ SGD
# -------------------------------------------------------------
# - learning_rate (alpha): ขนาดของก้าวเดิน (Step size) สมมติเราตั้งไว้ที่ 0.01
# - momentum: เพิ่มแรงเฉื่อยให้ก้าวได้เร็วขึ้น (เทคนิคเสริม)
sgd_optimizer = optimizers.SGD(learning_rate=0.01, momentum=0.9)
# จับคู่ Optimizer กับ Loss Function (เช่น Binary Cross-entropy)
model.compile(optimizer=sgd_optimizer,
loss='binary_crossentropy',
metrics=['accuracy'])
# -------------------------------------------------------------
# 📌 กำหนดขนาด Mini-batch ในขั้นตอนการฝึกฝน
# -------------------------------------------------------------
# - batch_size=64 คือการดึงภาพมาวิเคราะห์ทีละ 64 ภาพ แล้วทำการอัปเดต Weight 1 ครั้ง
history = model.fit(X_train, y_train,
epochs=50,
batch_size=64,
validation_split=0.2)5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในการปั้นโมเดล Machine Vision จริงๆ พี่มีหลุมพรางที่อยากเตือนให้น้องๆ ระวังเมื่อใช้งาน SGD ครับ:
- กับดัก Learning Rate (ก้าวใหญ่ไป หรือ ก้าวเล็กไป):
ตัวแปรที่สำคัญที่สุดในอัลกอริทึมนี้คือ Learning Rate (ขนาดก้าวเดิน) ครับ ถ้าน้องก้าวใหญ่ไป (Learning rate สูง) โมเดลจะกระโดดข้ามก้นหุบเขาไปมา (Diverge) และหาจุดที่ Error ต่ำสุดไม่เจอ แต่ถ้าก้าวเล็กไป (Learning rate ต่ำมาก) โมเดลจะเดินช้าเป็นเต่าคลาน กินเวลาเทรนข้ามวันข้ามคืน
เคล็ดลับ: ให้เริ่มต้นด้วยค่าประมาณ
0.01หรือ0.001แล้วค่อยๆ หรี่ขนาดก้าวลงเรื่อยๆ เมื่อใกล้ถึงเป้าหมาย (Learning Rate Scheduling) - เพิ่มแรงเฉื่อยด้วย Momentum: SGD เพียวๆ อาจจะเดินติดขัดในพื้นที่ที่ความชันน้อย เราจึงมักบวกค่า Momentum เข้าไปครับ เปรียบเหมือนการกลิ้งก้อนหิมะลงเขา ยิ่งกลิ้งลงทิศทางเดิมนานๆ ก้อนหิมะยิ่งมีความเร็วและแรงเฉื่อยสูงขึ้น ช่วยพุ่งทะลุจุดสะดุดและเข้าสู่เป้าหมายได้เร็วขึ้นมาก
- วิวัฒนาการสู่ Optimizer ยุคใหม่: แม้ SGD จะเป็นตำนาน แต่นักวิจัยก็พัฒนาตัวแปรใหม่ๆ ออกมาต่อยอด เช่น RMSprop และ Adam ที่สามารถ “ปรับขนาดก้าวเดินแบบอัตโนมัติ (Adaptive learning rate)” ตามความชันของแต่ละฟีเจอร์ได้เลย ซึ่งปัจจุบัน Adam ถือเป็น Optimizer ยอดฮิตที่เริ่มต้นใช้งานได้ง่ายที่สุดครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Gradient Descent (SGD) คือเครื่องยนต์ทางคณิตศาสตร์ที่รับข้อมูลความผิดพลาดจาก Backpropagation มาใช้ในการ “ไต่ลงเขา” เพื่อค้นหาค่าชุดน้ำหนัก (Weights) ที่ทำให้โมเดลทำงานผิดพลาดน้อยที่สุด โดยในทางปฏิบัติเรามักจะใช้แบบ Mini-batch ร่วมกับการใส่ Momentum เพื่อให้การประมวลผลบน GPU รวดเร็วและเสถียรที่สุดครับ
หลังจากที่เราเทรนโมเดลให้จำข้อสอบ (Training set) ได้เก่งแล้ว ปัญหาคลาสสิกที่จะตามมาติดๆ คืออาการ “จำข้อสอบเก่งเกินไป แต่เจอของจริงแล้วทายผิด (Overfitting)” ในตอนหน้า พี่จะพาไปงัดเอาคลังแสงอาวุธอย่าง Regularization (L1/L2, Dropout) มาจัดการกับปัญหานี้กันครับ ห้ามพลาดเด็ดขาด!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p