ถอดรหัส Backpropagation: คาถาย้อนเวลาที่ทำให้ AI เรียนรู้จากความผิดพลาด

1. 🎯 ตอนที่ 17: ถอดรหัส Backpropagation คาถาย้อนเวลาที่ทำให้ AI เรียนรู้จากความผิดพลาด
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกท่าน! กลับมาล้อมวงจิบกาแฟกันต่อครับ ในบทความก่อนหน้านี้เราได้เห็นภาพรวมของ “ห้องฝึกวิชา” หรือกระบวนการ Training Model กันไปแล้วว่าประกอบด้วย 4 ขั้นตอนหลัก วันนี้พี่จะพามาเจาะลึก “หัวใจ” ที่แท้จริงของการฝึกฝนโมเดล (Model Training) อัลกอริทึมที่เป็นเสมือนคาถาวิเศษที่ช่วยให้โครงข่ายประสาทเทียมสามารถเรียนรู้และปรับปรุงตัวเองได้ อัลกอริทึมระดับตำนานนี้มีชื่อว่า “Backpropagation” (การแพร่กลับ) ครับ
เรามาดูกันว่าในบริบทที่กว้างขึ้นของวงจรการเรียนรู้ (The Training Loop) นั้น Backpropagation เข้ามามีบทบาทอย่างไร ทำไมวงการ AI ถึงขาดมันไม่ได้ และคณิตศาสตร์เบื้องหลังที่ว่ายากๆ นั้น ถ้ามองในมุมของวิศวกร มันคือกลไกที่เรียบง่ายและงดงามขนาดไหน มาลุยกันเลยครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องกำลังหัดโยนลูกบาสเกตบอลให้ลงห่วงดูนะครับ ครั้งแรกที่น้องโยน (นี่คือ Forward Pass) ปรากฏว่าลูกบาสลอยไปชนขอบห่วงด้านหลังแล้วกระดอนออก (นี่คือ Loss หรือความผิดพลาดที่เกิดขึ้น)
คำถามคือ… สมองของน้องรู้ได้อย่างไรว่า ครั้งต่อไปจะต้อง “ลดแรงแขนลงนิดนึง” หรือ “ปรับองศาข้อมือหน่อยนึง”? คำตอบคือ สมองของเรามีกลไกส่ง “สัญญาณตอบกลับ” จากผลลัพธ์ที่ตาเห็น ย้อนกลับไปหาจุดต้นเหตุที่กล้ามเนื้อแต่ละมัด เพื่อบอกว่ากล้ามเนื้อมัดไหนออกแรงมากไปหรือน้อยไป
ในโลกของ Artificial Neural Networks (ANNs) ก็เช่นกันครับ ถ้าเรามีโมเดลที่มีจุดเชื่อมต่อ (Weights) เป็นล้านๆ ตัว เวลาที่โมเดลทายภาพแมวผิดเป็นสุนัข เราจะรู้ได้อย่างไรว่าต้องไปปรับแก้ Weight ตัวไหน ตัวละเท่าไหร่? พระเอกขี่ม้าขาวที่มาแก้ปัญหานี้คือ Backpropagation ครับ ซึ่งถูกนำมาประยุกต์ใช้อย่างแพร่หลายในปี 1986 โดย Rumelhart, Hinton และ Williams อัลกอริทึมนี้เปลี่ยนสิ่งที่เคยเป็นไปไม่ได้ (การคำนวณหาความรับผิดชอบของ Weight ทุกตัว) ให้กลายเป็นการคำนวณที่รวดเร็วและทำได้จริงในคอมพิวเตอร์ครับ!
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทที่กว้างขึ้นของการฝึกฝนโมเดล (Model Training) แหล่งข้อมูลระดับโลกได้จัดวางตำแหน่งและอธิบายการทำงานของ Backpropagation ไว้ดังนี้ครับ:
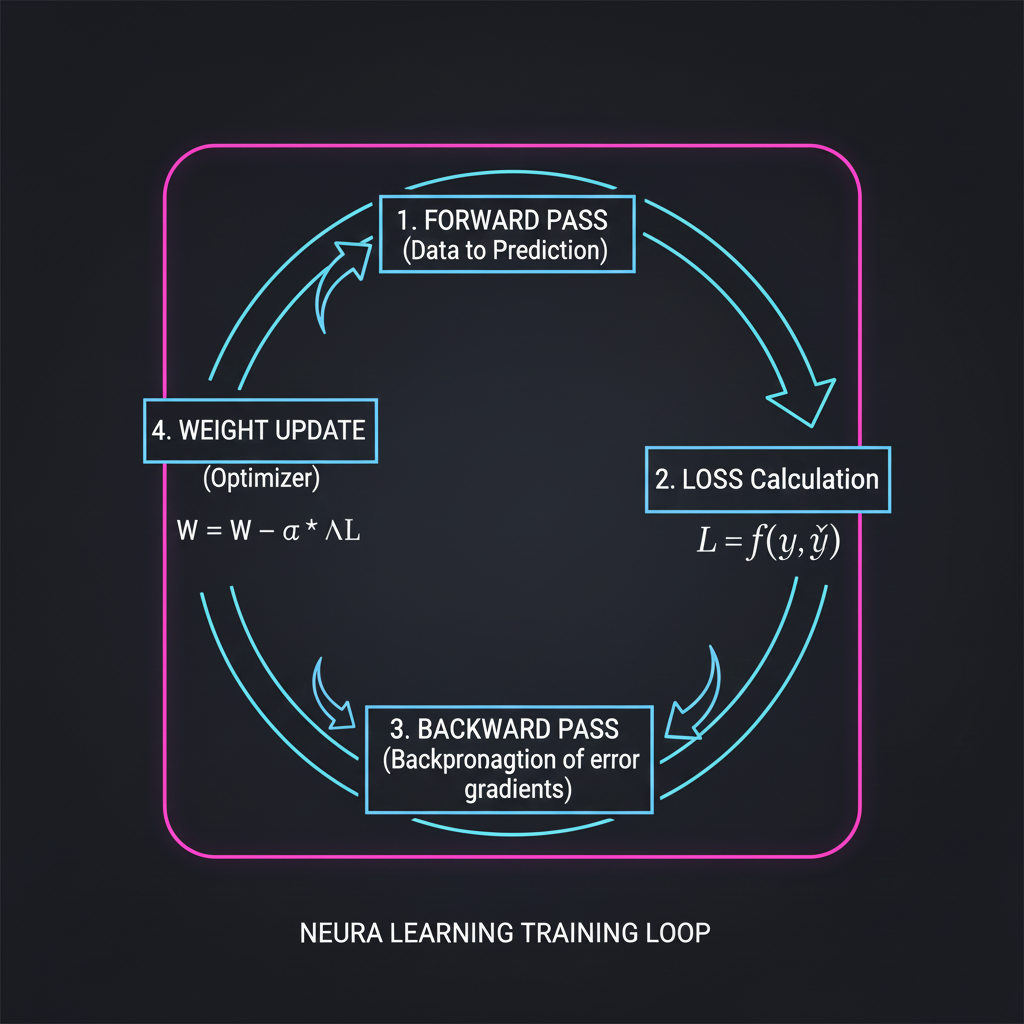
1. จิ๊กซอว์ชิ้นสำคัญใน Training Loop: กระบวนการ Training ประกอบด้วย 4 ขั้นตอนที่ทำซ้ำกันเป็นลูป
- Forward Pass: ป้อนข้อมูลเข้าเครือข่าย คำนวณผลลัพธ์ (Prediction)
- Loss Calculation: ประเมินความผิดพลาด (Error) ว่าคำตอบห่างจากความจริงแค่ไหน
- Backward Pass (Backpropagation): ค่อยๆ ส่งสัญญาณความผิดพลาด “ย้อนกลับ” จากชั้น Output ทะลุผ่าน Hidden Layers ไปจนถึงชั้น Input เพื่อคำนวณ “ความชัน” (Gradient) ของ Error เทียบกับ Weights ทุกตัว
- Weight Update: นำค่า Gradient ที่ได้ ไปใช้อัปเดต Weights ผ่านอัลกอริทึม Optimization เช่น Gradient Descent หรือ Adam
2. พลังแห่งกฎลูกโซ่ (The Chain Rule): วิธีการที่ Backpropagation ใช้คำนวณค่า Gradient เรียกว่า Reverse-mode Automatic Differentiation (Autodiff) ซึ่งอาศัยหลักการทางแคลคูลัสที่เรียกว่า กฎลูกโซ่ (Chain Rule) กฎลูกโซ่บอกว่า ถ้าน้องอยากรู้ว่า Weight ในชั้นแรกๆ ส่งผลต่อ Error สุดท้ายอย่างไร น้องแค่เอา “ความชันที่ถูกส่งต่อมาจากชั้นที่อยู่เหนือกว่า (Upstream gradient)” มาคูณกับ “ความชันของตัวมันเอง (Local gradient)” ไปเรื่อยๆ เป็นทอดๆ การทำเช่นนี้ทำให้คอมพิวเตอร์ไม่ต้องเสียเวลาสุ่มเดาค่าทีละตัว แต่คำนวณรวดเดียวจบทะลุทั้งเครือข่าย!
3. เงื่อนไขสำคัญ: ฟังก์ชันต้องหาอนุพันธ์ได้ (Differentiability): เพื่อให้อัลกอริทึมนี้ทำงานได้ Activation Function (ประตูกล) ที่เราใช้ในเครือข่าย จะต้องสามารถหาอนุพันธ์ได้ (Differentiable) นี่คือเหตุผลว่าทำไมยุค Deep Learning เราถึงทิ้ง Step Function แบบดั้งเดิม (ที่ความชันเป็นศูนย์) แล้วหันมาใช้ฟังก์ชันที่มีความโค้งหรือความชันต่อเนื่องอย่าง Sigmoid, Tanh หรือฮีโร่อย่าง ReLU แทนครับ เพราะถ้าหาความชันไม่ได้ Backpropagation ก็จะมืดบอดทันที
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้เห็นภาพว่า กลไกคณิตศาสตร์ที่ว่านี้ เขียนเป็นโค้ดได้อย่างไร ลองดูตัวอย่างการสร้างโครงสร้างเพื่อคำนวณ Backpropagation แบบแมนนวล (เพื่อให้เข้าใจกลไก) และการใช้ Framework สมัยใหม่ครับ:
import numpy as np
# -------------------------------------------------------------
# ตัวอย่างที่ 1: แกะกล่อง Backpropagation เบื้องหลัง (Math Under the Hood)
# อ้างอิงจากหลักการคำนวณ Gradient ด้วย Chain Rule
# -------------------------------------------------------------
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
s = sigmoid(x)
return s * (1 - s) # นี่คือ Local Gradient ของ Sigmoid!
# สมมติผลลัพธ์ที่โมเดลทายได้ (A) และความจริง (y)
A_output = 0.8
y_true = 1.0
# 📌 1. คำนวณ Error ที่ปลายทาง (Loss Calculation)
error = A_output - y_true
# 📌 2. BACKPROPAGATION (The Backward Pass)
# กฎลูกโซ่: เอา Error ปลายทาง คูณกับ อนุพันธ์ของ Activation Function
delta_output = error * sigmoid_derivative(A_output)
print(f"ค่า Gradient สำหรับเตรียมนำไปปรับ Weight: {delta_output}")
# -------------------------------------------------------------
# ตัวอย่างที่ 2: ชีวิตจริงบน Keras/TensorFlow
# วิศวกรไม่ต้องเขียนสมการหาอนุพันธ์เองเลย! Framework จัดการให้หมด
# -------------------------------------------------------------
import tensorflow as tf
from tensorflow.keras import layers, models, optimizers
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(10,)),
layers.Dense(1, activation='sigmoid')
])
# เมื่อเราเรียก model.compile และ .fit()
# TensorFlow จะทำการรันกระบวนการ Autodiff และ Backpropagation ให้แบบอัตโนมัติ!
model.compile(optimizer=optimizers.SGD(learning_rate=0.01),
loss='binary_crossentropy')คอมเมนต์: ในชีวิตจริง ถ้าน้องไม่ได้ทำงานวิจัยคิดค้นสมการใหม่ๆ พี่ไม่แนะนำให้เขียนลูป Backprop เองจากศูนย์นะครับ ปล่อยให้ระบบ Autodiff ของ TensorFlow หรือ PyTorch จัดการให้ เพราะมันทำมาให้เสถียรและรีดพลังของ GPU ออกมาได้ดีที่สุดแล้วครับ!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
แม้ว่า Backpropagation จะเป็นอัลกอริทึมที่ทรงพลัง แต่เมื่อนำไปใช้กับโครงสร้างเครือข่ายที่ซับซ้อน มันก็มี “หลุมพราง” ที่วิศวกรต้องระวังครับ:
- โรคความชันจางหาย (The Vanishing Gradient Problem): ถ้าน้องมี Network ที่ “ลึก (Deep)” มากๆ เช่นมี 50 เลเยอร์ การคูณเศษส่วนที่น้อยกว่า 1 (จากค่าความชันของ Sigmoid) ซ้ำๆ กัน 50 ครั้งด้วยกฎลูกโซ่ จะทำให้สัญญาณ Error หดเล็กลงเรื่อยๆ จนเข้าใกล้ 0 เมื่อไปถึงเลเยอร์แรกๆ ผลคือเลเยอร์ต้นๆ จะ “หยุดเรียนรู้” สนิทเลยครับ! (วิธีแก้คืออพยพไปใช้ ReLU และทำ Batch Normalization)
- โรคความชันระเบิด (The Exploding Gradient Problem): ในทางกลับกัน ถ้าค่าน้ำหนักมีค่ามากๆ การคูณทบกันย้อนกลับจะทำให้ค่า Gradient ขยายตัวแบบก้าวกระโดดจนพารามิเตอร์ระเบิด (NaN) พี่แนะนำให้ใช้เทคนิค Gradient Clipping (การตัดยอดความชันไม่ให้เกินลิมิต) เพื่อสกัดดาวรุ่งปัญหานี้ครับ
- นักเดินทางข้ามเวลา (BPTT - Backpropagation Through Time): หากน้องๆ นำ Backprop ไปใช้กับข้อมูลที่เป็นลำดับเวลา (Sequence) อย่างโมเดลประเภท RNNs โครงข่ายจะต้องถูก “คลี่ (Unroll)” ออกไปตามแกนเวลา กระบวนการส่งค่า Error ย้อนกลับไปในอดีตนี้เราเรียกว่า BPTT ซึ่งกินทรัพยากรมหาศาลและเจอปัญหา Vanishing Gradient ได้ง่ายสุดๆ (นี่คือเหตุผลที่ต้องมีสถาปัตยกรรมอย่าง LSTM มาช่วยแก้ปัญหาครับ)
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Backpropagation คือ “เส้นประสาทสั่งการย้อนกลับ” ที่คอยส่งข้อมูลความผิดพลาด (Error) ไปบอกเซลล์ประสาทเทียมทุกตัวในโมเดล ว่าใครต้องรับผิดชอบเท่าไหร่ และต้องปรับค่าน้ำหนัก (Weights) ตัวเองไปในทิศทางไหน
มันเป็นเครื่องมือสำคัญที่ขับเคลื่อน Optimization (การไต่ลงเขาหาจุดที่ Error ต่ำสุด) และทำให้ AI ทุกตัวบนโลก ตั้งแต่โมเดลแยกรูปหมาแมว ไปจนถึงแชทบอทอัจฉริยะ สามารถ “เรียนรู้จากข้อผิดพลาด” และเก่งขึ้นได้อย่างน่าอัศจรรย์ครับ!
ในตอนต่อไป หลังจากที่เราเห็นแล้วว่าโมเดลปรับตัวให้ “จำข้อสอบ (Training Data)” ได้เก่งแค่ไหน เราจะมาทำความรู้จักกับเทคนิคที่จะช่วยให้โมเดลไม่เผลอท่องจำข้อสอบจนเกินไป ซึ่งก็คือเทคนิค Regularization (การลด Overfitting) อย่าง L1/L2 และ Dropout รับรองว่าเข้มข้นแน่นอน รอติดตามครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p