ห้องฝึกวิชาสมองกล: แกะรอยกระบวนการ Training Model หัวใจสำคัญของ Deep Learning
1. 🎯 ตอนที่ 16: ห้องฝึกวิชาสมองกล แกะรอยกระบวนการ Training Model
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกท่าน! ชงกาแฟให้พร้อมแล้วมาล้อมวงกันตรงนี้ครับ ตลอดหลายตอนที่ผ่านมา พี่พาน้องๆ ไปรู้จักกับสถาปัตยกรรม (Architectures) โครงสร้างชั้นซ่อน (Hidden Layers) และประตูกล (Activation Functions) กันมาหมดแล้ว
แต่รู้ไหมครับว่า โครงข่ายประสาทเทียมที่เราเขียนโค้ดสร้างขึ้นมาใหม่ๆ มันเป็นเพียง “สมองเปล่าๆ ที่มีเส้นประสาทเชื่อมต่อกันแบบสุ่ม” มันยังแยกหมากับแมวไม่ออกด้วยซ้ำ! วันนี้เราจะมาเจาะลึกกระบวนการที่สำคัญที่สุด ที่เปลี่ยนสมองกลโง่ๆ ให้กลายเป็นยอดอัจฉริยะ กระบวนการนั้นเรียกว่า “การฝึกฝนโมเดล (Model Training)” ครับ เรามาดูกันว่าในบริบทที่กว้างขึ้นของ Deep Learning นั้น การเรียนรู้ของ AI มีกลไกการทำงานอย่างไร!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องๆ เพิ่งรับพนักงานตรวจสอบคุณภาพ (QC) คนใหม่เข้ามาทำงานในโรงงาน วันแรกที่เขามาถึง เขาไม่รู้เลยว่าน็อตแบบไหนคือ “ของดี (Pass)” และแบบไหนคือ “ของเสีย (Fail)”
ถ้าน้องๆ อยากให้เขาเก่งขึ้น น้องก็ต้องเอาตะกร้าใส่น็อตมาให้เขาดูทีละตัว พอเขาหยิบน็อตขึ้นมาแล้วเดาว่า “ดีครับพี่!” ถ้าน็อตตัวนั้นมันเสีย น้องก็ต้องเอาไม้เรียวตีมือเบาๆ พร้อมบอกว่า “ผิด! นี่มันรอยร้าวชัดๆ จำไว้แล้วปรับปรุงตัวด้วย” พนักงานคนนั้นก็จะ “ปรับจูนความคิด” ของตัวเองใหม่ พอทำซ้ำแบบนี้ไปเรื่อยๆ เป็นพันๆ หมื่นๆ ครั้ง พนักงานคนนี้ก็จะกลายเป็นผู้เชี่ยวชาญที่มองปราดเดียวก็รู้ว่าน็อตตัวไหนดีหรือเสีย
ในโลกของ Machine Learning และ Deep Learning เราเรียกกระบวนการเรียนรู้จากความผิดพลาดแบบนี้ว่า Supervised Learning (การเรียนรู้แบบมีผู้สอน) ครับ ซึ่งการที่ AI จะเก่งได้ มันไม่ใช่แค่การร่ายเวทมนตร์ แต่มันคือการผสมผสานระหว่างข้อมูล (Data), การวัดความผิดพลาด (Loss Function), และอัลกอริทึมปรับจูนตัวเอง (Optimization) มารวมกันอย่างลงตัวครับ
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทของพื้นฐาน Deep Learning แหล่งข้อมูลระดับโลกได้แบ่งองค์ประกอบของการ “Training” ออกเป็นเสาหลักดังต่อไปนี้ครับ:
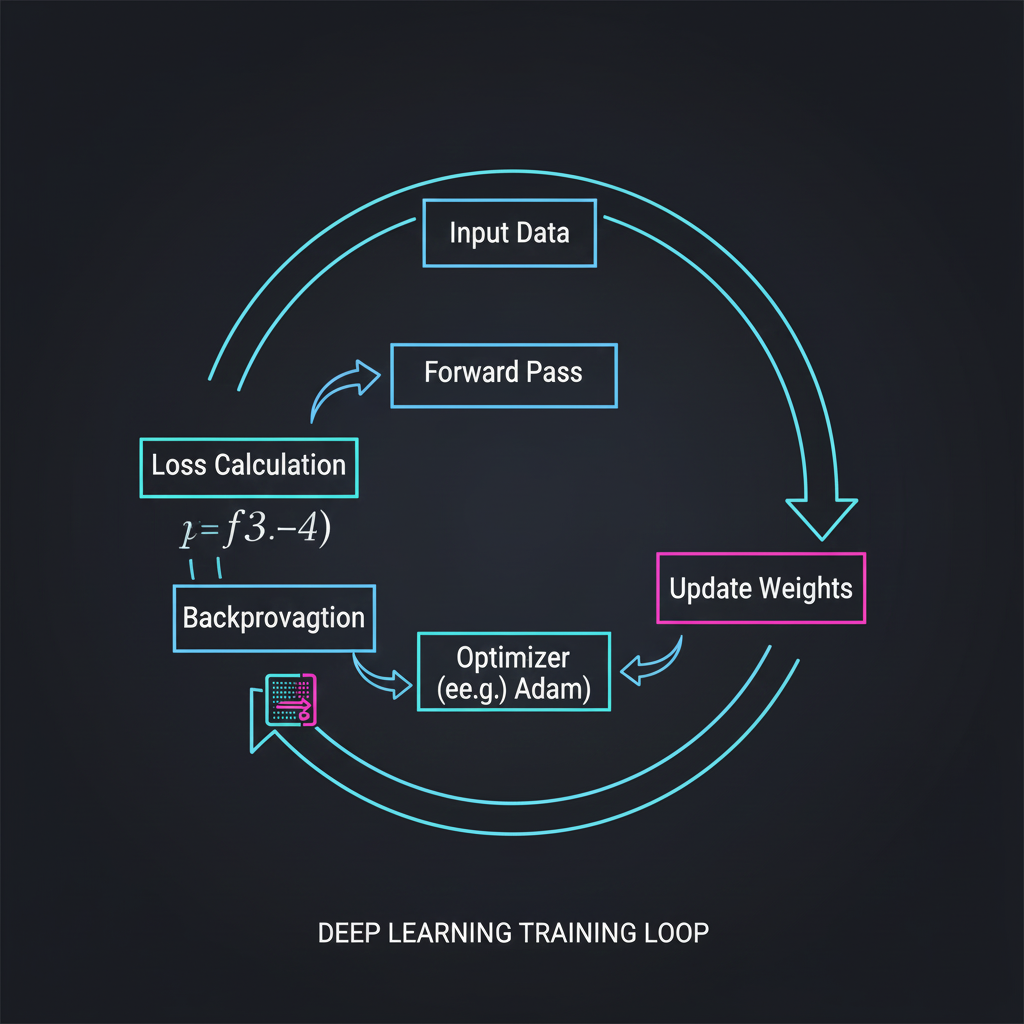
1. วงจรแห่งการเรียนรู้ (The Training Loop): การฝึกฝนโมเดลคือการทำซ้ำ 4 ขั้นตอนอย่างต่อเนื่อง:
- Forward Pass: ป้อนข้อมูลภาพดิบๆ เข้าไป ให้โมเดลลอง “เดา (Predict)” ผลลัพธ์
- Loss Calculation: นำคำตอบที่โมเดลเดา มาเทียบกับ “เฉลย (Ground Truth)” แล้วคำนวณออกมาเป็นตัวเลขความผิดพลาดผ่าน Loss Function (Cost Function) เช่น Cross-Entropy สำหรับงานจัดหมวดหมู่ หรือ Mean Squared Error (MSE) สำหรับงานทายตัวเลข
- Backpropagation: ส่งสัญญาณความผิดพลาดย้อนกลับ (แพร่กลับ) ไปตามเครือข่าย เพื่อหาว่าเส้นเชื่อมต่อ (Weights) เส้นไหนเป็นต้นเหตุของความผิดพลาดนี้
- Weight Update (Optimization): ใช้อัลกอริทึมอย่าง Gradient Descent ปรับเปลี่ยนค่าน้ำหนัก (Weights) ทีละนิดเพื่อให้รอบหน้าทายได้แม่นยำขึ้น
2. พระเอกตัวจริง: อัลกอริทึม Optimization: หนังสือหลายเล่มกล่าวตรงกันว่า “Deep Learning ขับเคลื่อนด้วยอัลกอริทึมที่ชื่อว่า Stochastic Gradient Descent (SGD)” ครับ มันคือวิธีการ “ไต่ลงเขา” เพื่อหาจุดที่ต่ำที่สุดของ Loss Function แต่ในยุคปัจจุบัน เรามี Optimizer ที่ฉลาดและเร็วกว่าเดิมมาก เช่น Adam หรือ RMSProp ซึ่งมีการใส่เทคนิคอย่าง Momentum (ความเฉื่อย) เข้าไปช่วยให้โมเดลไม่ไปติดแหง็กอยู่ในหลุมพราง (Local Minima) ครับ
3. แบ่งข้อมูลเพื่อกันการทุจริต (Train / Validation / Test Splits): เป้าหมายสูงสุดของการเทรน ไม่ใช่การให้โมเดลท่องจำข้อสอบได้ 100% แต่คือการ Generalization (ความสามารถในการนำไปใช้กับของใหม่) เราจึงต้องแบ่งข้อมูลเป็น:
- Training Set: ข้อมูลก้อนใหญ่ที่ให้โมเดลใช้เรียนรู้และปรับน้ำหนัก
- Validation Set: ข้อมูลก้อนเล็กที่เอาไว้ทดสอบระหว่างเทรน เพื่อดูว่าโมเดลเริ่ม “จำข้อสอบ (Overfitting)” หรือยัง
- Test Set: ข้อมูลลับสุดยอด เก็บไว้ทดสอบตอนจบกระบวนการ เพื่อดูความแม่นยำที่แท้จริง
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ความเจ๋งของ Framework อย่าง Keras/TensorFlow คือ น้องๆ ไม่ต้องเขียนสมการหาอนุพันธ์ (Calculus) หรือเขียนลูปอัปเดตน้ำหนักเองเลยครับ โค้ดที่รวบรวมทุกแก่นวิชาด้านบน หน้าตาคลีนๆ แบบนี้เลยครับ:
import tensorflow as tf
from tensorflow.keras import layers, models, optimizers
# 1. นิยามสถาปัตยกรรม (เปรียบเสมือนรับพนักงานใหม่ที่สมองยังว่างเปล่า)
model = models.Sequential([
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax') # ให้คำตอบเป็น 10 คลาส
])
# 2. จัดเตรียมเครื่องมือสำหรับการ Training (สำคัญมาก!)
# - Optimizer: ใช้ Adam เพื่อให้ไต่ลงเขาหาจุดที่ Loss ต่ำสุดได้ไวและเสถียร
# - Loss Function: ใช้ Sparse Categorical Crossentropy สำหรับงาน Classification
# - Metrics: ติดตามค่าความแม่นยำ (Accuracy)
model.compile(optimizer=optimizers.Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 3. เริ่มกระบวนการ Training Loop (เข้าห้องเรียน!)
# - epochs: จำนวนรอบที่จะให้โมเดลเห็นข้อมูลครบทั้งกอง (วนซ้ำกี่รอบ)
# - batch_size: หยิบข้อมูลมาให้ดูทีละ 32 ภาพแล้วค่อยอัปเดตน้ำหนักทีนึง
# - validation_split: หักข้อมูล 20% ไว้เป็นตัวเช็กว่าจำข้อสอบ (Overfit) หรือไม่
history = model.fit(X_train, y_train,
epochs=20,
batch_size=32,
validation_split=0.2)คอมเมนต์: สังเกตบรรทัด model.fit() นะครับ นี่แหละคือจุดที่เวทมนตร์เกิดขึ้น การทำ Forward pass, Backpropagation และปรับน้ำหนัก ซ่อนอยู่ในคำสั่งเดียวนี้เลย!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในมุมมองของนักปฏิบัติที่ต้องเอา AI ไปลุยหน้างานโรงงาน พี่อยากบอกว่าการ Training คือ “กึ่งวิทยาศาสตร์ กึ่งศิลปะ (Part Science, Part Art)” ครับ นึ่คือเคล็ดลับที่พี่ใช้ประจำ:
- Learning Rate คือพระเจ้า: ค่า Learning Rate (อัตราการเรียนรู้) คือก้าวเดินของการไต่ลงเขา ถ้าก้าวใหญ่ไป (เช่น 0.1) โมเดลจะกระโดดข้ามจุดที่ดีที่สุดไปมาทำให้ Loss แกว่งกระจุยกระจาย แต่ถ้าก้าวเล็กไป (เช่น 0.000001) มันจะเรียนรู้ช้าเป็นเต่าคลาน การจูนค่านี้คือหัวใจสำคัญอันดับหนึ่งเลยครับ ปัจจุบันเรามักใช้เทคนิค Learning Rate Scheduling (ลดก้าวเดินลงเรื่อยๆ เมื่อใกล้ถึงเป้าหมาย)
- เมื่อ AI ท่องจำข้อสอบ (Overfitting):
ถ้าน้องๆ สังเกตว่า Training Loss ลดลงเรื่อยๆ แต่ Validation Loss กลับเด้งสูงขึ้น แปลว่าพนักงานของเราเริ่ม “ท่องจำพิกเซล” แล้วครับ! (Overfitting) อาวุธประจำกายที่ใช้แก้ปัญหานี้คือ:
- Data Augmentation: ถ้ารูปน้อย ก็พลิกรูป หมุนรูป เพิ่มแสง เพื่อหลอกให้ AI นึกว่ามีข้อมูลเยอะขึ้น
- Dropout Layer: สุ่มปิดเซลล์ประสาทบางตัวระหว่างเทรน เพื่อบังคับให้เซลล์ที่เหลือต้องพึ่งพาตัวเองและหาลักษณะเด่นให้เก่งขึ้น
- Early Stopping: สั่งหยุดการเทรนอัตโนมัติทันทีที่ Validation Loss เริ่มมีค่าแย่ลง เพื่อไม่ให้มันจำข้อสอบไปมากกว่านี้
6. 🏁 บทสรุป (To be continued…)
สรุปสั้นๆ เลยครับ Model Training คือกระบวนการป้อนข้อมูลให้สถาปัตยกรรมโครงข่ายประสาท ปล่อยให้มันทำนาย หาข้อผิดพลาดด้วย Loss Function และส่งข้อผิดพลาดนั้นย้อนกลับไปปรับปรุงแก้ไขตัวแปร (Weights) หลายล้านตัวผ่าน Backpropagation และ Optimizer จนกระทั่งโมเดลมีความสามารถที่จะแยกแยะสิ่งที่มันไม่เคยเห็นมาก่อน (Generalization) ได้สำเร็จ
การฝึกฝนโมเดลให้ออกมาดีต้องใช้เวลา การทดลอง (Empirical process) และความเข้าใจในข้อมูลครับ ในบทความต่อไป พี่จะพาไปดูเทคนิคทางลัดที่เรียกว่า Transfer Learning ที่เราสามารถเอา “สมองที่ผ่านการฝึกฝนมาแล้วอย่างโชกโชน (Pre-trained Model)” มาสานต่อยอดกับงานของเราโดยไม่ต้องเริ่มนับศูนย์ใหม่ รับรองว่าทุ่นเวลาไปได้มหาศาล ห้ามพลาดนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p