ศึกประชันสมองกล: CNN vs ANN ใครคือตัวจริงในงาน Machine Vision อุตสาหกรรม?

1. 🎯 ตอนที่ 6: ศึกประชันสมองกล! CNN vs ANN ใครคือตัวจริงบนหน้างานจริง
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกท่าน! ชงกาแฟเข้มๆ แล้วมานั่งคุยกันต่อครับ หลายคนคงเคยได้ยินคำว่า ANN (Artificial Neural Network) และ CNN (Convolutional Neural Network) กันมาบ้างแล้ว แต่พอต้องเอามาใช้กับโปรเจกต์ตรวจจับของเสียในโรงงาน (Defect Detection) หรืออ่านป้ายทะเบียนรถ วิศวกรมือใหม่มักจะสับสนว่า “แล้วผมควรใช้โครงสร้างไหนดี?”
วันนี้พี่จะพาสวมวิญญาณนักสืบ มาไขคดีและชำแหละให้เห็นกันชัดๆ เลยว่า ทำไม ANN ดั้งเดิมถึงมักจะ “ตายสนิท” เมื่อเจอภาพจากกล้องอุตสาหกรรม และทำไม CNN ถึงได้รับการยกย่องให้เป็น “พระเอกตัวจริง” ของวงการ Machine Vision ครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการภาพตามพี่นะครับ วันหนึ่งน้องได้รับมอบหมายให้ทำระบบตรวจจับรอยแตกร้าวบนผิวโลหะ น้องเลือกใช้กล้องอุตสาหกรรมความละเอียด 5 Megapixels ถ่ายภาพมาอย่างคมชัด จากนั้นน้องก็สร้างโมเดล ANN แบบคลาสสิก (หรือ Multilayer Perceptron - MLP) หวังจะให้มันเรียนรู้
ปรากฏว่า… ตู้มมม! ทันทีที่กดปุ่ม Train คอมพิวเตอร์อุตสาหกรรม (IPC) ตัวละแสนของน้องเกิดอาการแรมเต็ม (Out of Memory) หน้าจอค้าง และโมเดลก็ไม่สามารถแยกแยะรอยร้าวได้เลยแม้แต่นิดเดียว! เกิดอะไรขึ้น?
สาเหตุที่เป็นแบบนั้นก็เพราะ ANN มีข้อจำกัดที่ร้ายแรงมากเมื่อต้องทำงานกับ “รูปภาพ 2 มิติ” ครับ มันเหมือนกับน้องจ้างนักสืบมาดูภาพกล้องวงจรปิด แต่นักสืบคนนี้ดันเอาภาพไปเข้า “เครื่องย่อยกระดาษ” ให้กลายเป็นเส้นตรงยาวๆ ก่อนแล้วค่อยดู (Flattening) แบบนี้ใครมันจะไปหาคนร้ายเจอถูกไหมครับ? นี่แหละครับคือจุดที่ CNN ต้องออกโรงมาแก้ไขสถานการณ์!
3. 🧠 แก่นวิชา (Core Concepts)
เพื่อไม่ให้พลาดพลั้งบนหน้างานจริง เรามาเปรียบเทียบความแตกต่างเชิงลึกระหว่าง ANN และ CNN กันครับ:
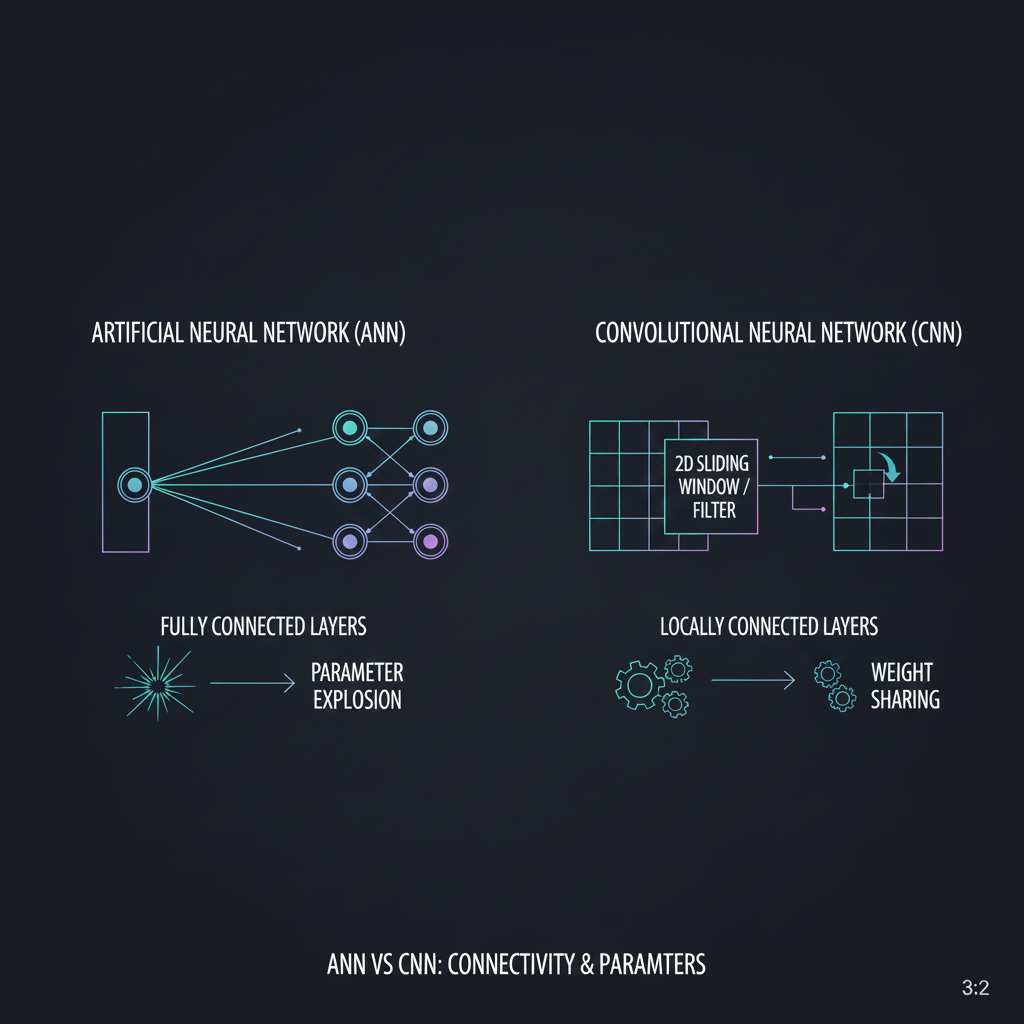
1. วิธีการมองภาพ (Spatial Understanding):
- ANN (นักสืบสายสถิติ): รับข้อมูลแบบ 1 มิติ (1D Vector) เท่านั้น ถ้าน้องมีภาพ 2 มิติ (กว้าง x ยาว) น้องบังคับต้อง “ยืด” ภาพให้เป็นเส้นตรง (Flatten) สิ่งที่เกิดขึ้นคือคอมพิวเตอร์จะสูญเสีย Spatial Features (มิติเชิงพื้นที่) มันจะไม่รู้เลยว่าพิกเซลด้านซ้ายและขวาเคยอยู่ติดกันมาก่อน ทำให้หา “เส้นขอบ” หรือ “รูปทรง” ได้ยากมาก
- CNN (นักสืบตาแว่นขยาย): รับข้อมูลภาพดิบแบบ 2 มิติ (หรือ 3 มิติถ้ารวมสี RGB) เข้าไปประมวลผลได้เลย! มันใช้เทคนิค “แว่นขยาย” หรือหน้าต่างเล็กๆ ที่เรียกว่า Kernel/Filter กวาดไปทั่วภาพ (Sliding Window) ทำให้มันเข้าใจว่าพิกเซลกลุ่มนี้รวมตัวกันเป็น “รอยร้าว” หรือ “ขอบน็อต” ได้อย่างสมบูรณ์
2. รูปแบบการเชื่อมต่อ (Connectivity):
- ANN (Fully Connected): เซลล์ประสาท (Neurons) ทุกตัวในชั้นหนึ่ง จะต้องโยงเส้นเชื่อมต่อไปหาเซลล์ประสาท “ทุกตัว” ในชั้นถัดไป
- CNN (Locally Connected): เซลล์ประสาทจะเชื่อมต่อกับพิกเซลแค่ “กลุ่มเล็กๆ” เฉพาะจุดที่แว่นขยายกวาดผ่านเท่านั้น ไม่ต้องคุยกับทุกคน
3. ภาระการคำนวณ (The Parameter Explosion):
- ANN: ลองคิดภาพกล้อง 1 Megapixel (1000x1000) ถ้าน้องใช้ ANN ที่มี Hidden layer แค่ 1,000 โหนด น้องต้องใช้เส้นเชื่อมต่อ (Weights) ถึง $1,000,000 \times 1,000 = 1$ พันล้านพารามิเตอร์ในชั้นเดียว! กินสเปคเครื่องมหาศาล
- CNN: ใช้เทคนิค Weight Sharing (การใช้ค่าน้ำหนักร่วมกัน) คือแว่นขยาย 1 อัน (เช่น ขนาด 3x3) จะใช้ตัวเลข Weights ชุดเดิมกวาดไปทั่วทั้งภาพ ทำให้พารามิเตอร์ลดลงจากหลักพันล้านเหลือแค่หลัก “ร้อยหรือพัน” ตัวเท่านั้น! ประหยัดแรมแบบสุดๆ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ลองมาดูโค้ด Keras/TensorFlow กันครับ พี่จะเทียบให้ดูว่าการสร้าง Network ทั้ง 2 แบบต่างกันอย่างไร สมมติเรารับภาพชิ้นงานขนาด 256x256 พิกเซลแบบขาวดำ:
from tensorflow.keras import layers, models
# -------------------------------------------------------------
# ❌ แบบที่ 1: การใช้ ANN กับงานภาพ (มักจะพังถ้าภาพใหญ่!)
# -------------------------------------------------------------
ann_model = models.Sequential([
# ต้องสับภาพ 2D ให้แบนราบเป็น 1D ก่อน (มิติภาพพินาศหมด)
layers.Flatten(input_shape=(256, 256, 1)),
# Fully Connected Layer: โหนดเชื่อมหากันหมด
# (ตรงนี้จะเกิด Parameter Explosion มหาศาล!)
layers.Dense(512, activation='relu'),
layers.Dense(256, activation='relu'),
layers.Dense(2, activation='softmax') # Output ผ่าน / ไม่ผ่าน
])
# -------------------------------------------------------------
# ✅ แบบที่ 2: การใช้ CNN ฮีโร่ของงาน Machine Vision
# -------------------------------------------------------------
cnn_model = models.Sequential([
# ไม่ต้อง Flatten! ใช้ Conv2D (แว่นขยาย) สกัด Features ได้เลย
# พิกเซลที่อยู่ติดกันยังคงส่งความหมายร่วมกัน
layers.Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(256, 256, 1)),
# ย่อขนาดภาพให้เล็กลง เพื่อเน้นเฉพาะจุดเด่น
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
# เมื่อสกัดจุดเด่นเสร็จแล้ว ค่อย Flatten ส่งเข้า ANN ในตอนท้ายเพื่อตัดสินใจฟันธง
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(2, activation='softmax') # Output ผ่าน / ไม่ผ่าน
])5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
จากประสบการณ์ทำระบบ Vision ในโรงงาน พี่มีคัมภีร์ลับมาฝากครับ:
- หลุมพราง Overfitting (การจำข้อสอบ): ANN ที่มีพารามิเตอร์เยอะเกินไป ไม่เพียงแต่กินสเปคเครื่องนะครับ แต่มันจะเกิดอาการ Overfitting อย่างหนัก คือมันจะ “จำ” ทุกพิกเซลของรูปที่เราสอนได้เป๊ะๆ แต่พอไปเจอชิ้นงานจริงที่มีแสงเงาเปลี่ยนไปนิดเดียว มันจะทายผิดหมดเลย! ส่วน CNN ด้วยคุณสมบัติที่เรียกว่า Translation Invariance (ความทนทานต่อการเลื่อนตำแหน่ง) ไม่ว่ารอยร้าวจะอยู่มุมซ้ายหรือมุมขวาของภาพ CNN ก็สามารถตรวจจับได้ครับ
- เมื่อไหร่ที่ควรกลับไปใช้ ANN (MLP)?: แล้ว ANN ไร้ประโยชน์เลยหรือเปล่า? ไม่ใช่ครับ! ถ้าน้องทำระบบที่อ่านค่าจากเซนเซอร์ 1 มิติ เช่น ข้อมูลอุณหภูมิ (Temperature), ความชื้น, หรือข้อมูลเชิงสถิติ (Tabular Data) ANN คือราชาในด้านนี้ครับ แต่ถ้าเป็น “รูปภาพและวิดีโอ” ปล่อยให้เป็นหน้าที่ของ CNN จะดีที่สุด
- การผสมผสาน (The Hybrid): ในความจริงแล้ว สังเกตโค้ด CNN ในส่วนท้าย เราก็ยังต้องดึง Dense Layer (ANN) กลับมาใช้อยู่ดีครับ นั่นแปลว่า CNN รับหน้าที่เป็น “ผู้เชี่ยวชาญด้านการแกะรอย (Feature Extractor)” ส่วน ANN รับหน้าที่เป็น “ผู้พิพากษาตัดสิน (Classifier)” ในตอนจบนั่นเอง!
6. 🏁 บทสรุป (To be continued…)
สรุปสั้นๆ ให้จำขึ้นใจเลยครับว่า ในโลกของอุตสาหกรรมที่ต้องใช้กล้องความละเอียดสูง CNN (Convolutional Neural Network) คือคำตอบที่ใช่ที่สุดสำหรับงานภาพ เพราะมันฉลาดในการหาจุดเด่น (Features) ประหยัดทรัพยากรคอมพิวเตอร์ (Weight Sharing) และเข้าใจรูปทรง (Spatial dimensions) ได้อย่างลึกซึ้ง แตกต่างจาก ANN ที่บังคับให้ยืดภาพเป็นเส้นตรงจนสูญเสียความหมายไปหมด
เมื่อเราเข้าใจความต่างนี้แล้ว ในบทความต่อไป พี่จะพาไปดูว่าโครงสร้างของ CNN ระดับโลก (CNN Architectures) อย่าง ResNet หรือ YOLO ที่เขาเอามาจับภาพหน้างานจริงแบบ Real-time นั้น มันมีเคล็ดลับอะไรซ่อนอยู่ อย่าลืมติดตามนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p