ถอดรหัส Softmax: ผู้พิพากษาสูงสุดแห่งโลก AI และศิลปะแห่งความน่าจะเป็น

1. 🎯 ตอนที่ 15: ถอดรหัส Softmax ผู้พิพากษาสูงสุดแห่งโลก AI
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาสาย Vision ทุกคน! มานั่งจิบกาแฟให้ตาสว่างกันครับ หลังจากที่เราได้บุกตะลุยไปในดินแดนของ Hidden Layers และทำความรู้จักกับพระเอกอย่าง ReLU กันไปแล้ว วันนี้พี่จะพามาถึง “ด่านสุดท้าย” ของโครงข่ายประสาทเทียม (Neural Networks) กันครับ
ในบริบทของฟังก์ชันกระตุ้น (Activation Functions) หาก ReLU คือยอดนักสืบที่คอยค้นหาเบาะแส วันนี้เราจะมาทำความรู้จักกับ Softmax Function ซึ่งเปรียบเสมือน “ผู้พิพากษาสูงสุด” ที่จะทำหน้าที่รวบรวมหลักฐานทั้งหมด แล้วเคาะโต๊ะฟันธงว่าท้ายที่สุดแล้ว ชิ้นงานนี้คือ “น็อตตัวผู้”, “น็อตตัวเมีย”, หรือ “แหวนรอง” กันแน่!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องกำลังทำระบบ Machine Vision เพื่อแยกแยะผลไม้ 3 ชนิด: แอปเปิล, ส้ม, และกล้วย
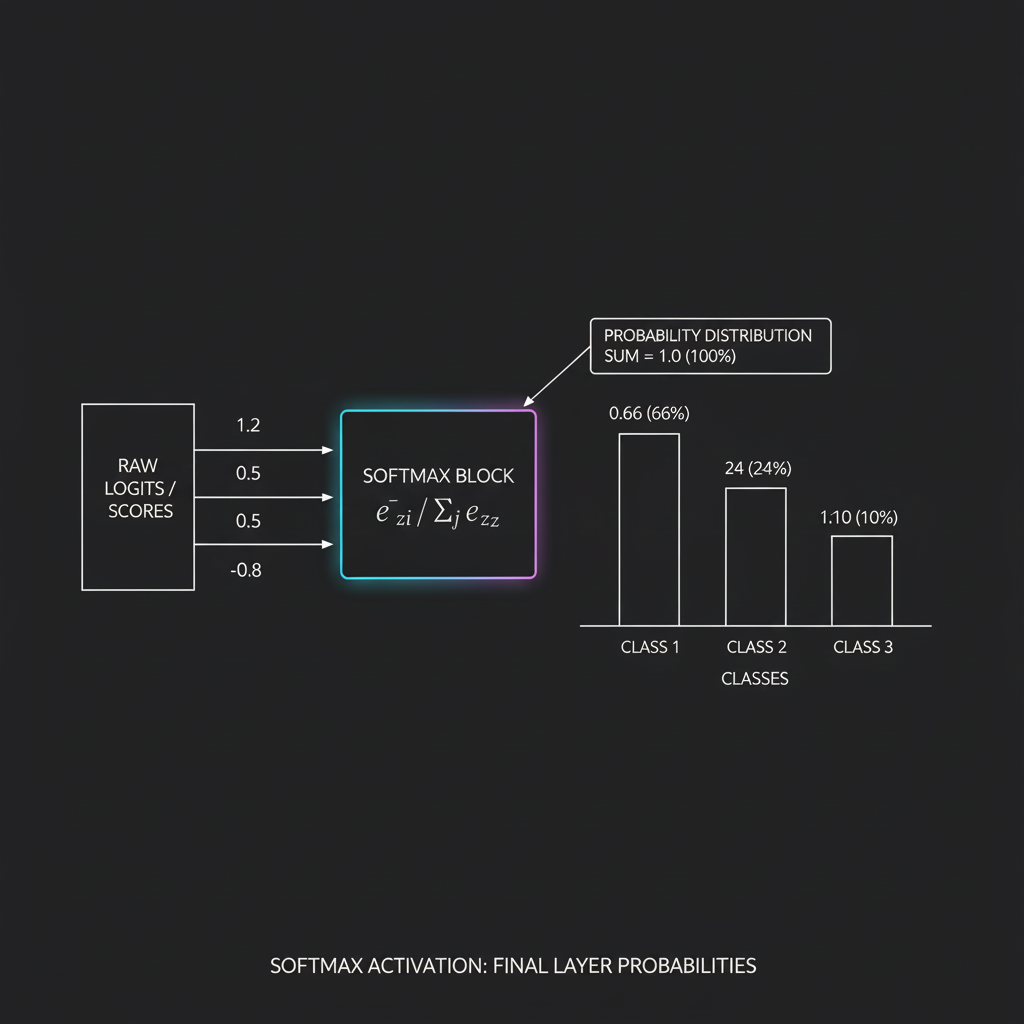
ข้อมูลภาพวิ่งผ่านเลเยอร์ต่างๆ สกัดจุดเด่นสารพัด จนมาถึงเลเยอร์สุดท้าย… คอมพิวเตอร์คายตัวเลขดิบๆ (เราเรียกว่า Logits หรือ Scores) ออกมาเป็น [แอปเปิล: 3.91, ส้ม: 1.16, กล้วย: -3.44]
คำถามคือ ในฐานะมนุษย์ น้องจะเอาตัวเลขพวกนี้ไปโชว์ให้ผู้ใช้งานหน้างานดูไหมครับ? “คุณลูกค้าครับ ระบบเรามั่นใจว่านี่คือแอปเปิลที่คะแนน 3.91 ครับ!”… ลูกค้าคงทำหน้างงแน่นอนครับ เพราะตัวเลขดิบพวกนี้มันตีความหมายยากมาก มันไม่เหมือน “เปอร์เซ็นต์” ที่มนุษย์คุ้นเคย
นี่แหละครับคือเวทีที่ Softmax Function ต้องออกโรง! หน้าที่ของมันคือการเสกตัวเลขดิบๆ ที่ดูไม่รู้เรื่องเหล่านี้ ให้กลายเป็น “ค่าความน่าจะเป็น (Probabilities)” ที่ทุกๆ คลาสรวมกันแล้วได้เท่ากับ 1.0 (หรือ 100%) พอดีเป๊ะ!, พอผ่าน Softmax ปุ๊บ ตัวเลขเมื่อกี้อาจจะกลายเป็น [แอปเปิล: 93.9%, ส้ม: 6.0%, กล้วย: 0.1%] ทีนี้ล่ะ คุยกับลูกค้ารู้เรื่องแน่นอน!
3. 🧠 แก่นวิชา (Core Concepts)
ในจักรวาลของสถาปัตยกรรม Deep Learning แหล่งข้อมูลได้อธิบายบทบาทสำคัญของ Softmax ไว้ดังนี้ครับ:
- 1. ร่างพัฒนาของ Sigmoid (The Generalization): Softmax คือการนำฟังก์ชัน Sigmoid (ที่ใช้ตัดสินใจแค่ 2 คลาสแบบ ใช่/ไม่ใช่) มาอัปเกรดและขยายผลให้รองรับปัญหาแบบ Multiclass Classification (การแยกแยะมากกว่า 2 คลาส),
- 2. สมการแปลงคะแนนเป็นเปอร์เซ็นต์ (The Math): กลไกของมันฉลาดมากครับ สมมติว่า $z$ คือเวกเตอร์ของคะแนนดิบ (Logits) สมการของ Softmax สำหรับคลาสที่ $j$ คือ: $$ \sigma(z)j = \frac{e^{z_j}}{\sum{k=1}^{K} e^{z_k}} $$, การใช้ฟังก์ชัน Exponential ($e^z$) จะช่วยดันคะแนนที่เป็นค่าลบให้กลายเป็นบวกเสมอ และทำให้คะแนนที่สูงอยู่แล้ว “โดดเด่น” ขึ้นมา (นี่คือที่มาของคำว่า “Max”) จากนั้นจึงนำไปหารด้วยผลรวมของ Exponential ทั้งหมดในคลาสนั้นๆ เพื่อบีบให้สัดส่วน (Normalize) ผลรวมของทุกคลาสเท่ากับ 1 เสมอ, (นี่คือที่มาของคำว่า “Soft” เพราะมันไม่ได้เลือกตอบแค่คลาสเดียว 100% แล้วทิ้งคลาสอื่นเป็น 0 หมด แต่มันแบ่งเปอร์เซ็นต์ให้ตามความน่าจะเป็นครับ)
- 3. ตำแหน่งที่ตั้ง (The Placement): ต่างจาก ReLU หรือ Tanh ที่เรามักซุกซ่อนไว้ใน Hidden Layers… Softmax จะถูกวางไว้ที่ Output Layer (ชั้นส่งออก) เสมอ, เพื่อทำหน้าที่ชี้ขาดในขั้นตอนสุดท้ายของโมเดล
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในการทำงานจริง การเรียกใช้ผู้พิพากษา Softmax ใน Keras / TensorFlow นั้นง่ายจนแทบไม่ต้องเขียนสมการเองเลยครับ สมมติว่าเรากำลังสร้างโมเดลตรวจสอบชิ้นงาน 10 ประเภท (10 Classes):
import tensorflow as tf
from tensorflow.keras import layers, models
# สร้างโมเดล CNN สำหรับงาน Computer Vision
model = models.Sequential([
# ... ซ่อน Hidden Layers ไว้ตรงนี้ (ใช้ ReLU เป็นฟังก์ชันกระตุ้น) ...
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
# 📌 ด่านสุดท้าย (Output Layer): ใช้ Dense เท่ากับจำนวนคลาส (เช่น 10 คลาส)
# และประกาศใช้ activation='softmax' เพื่อให้มันคำนวณความน่าจะเป็น!
layers.Dense(10, activation='softmax', name='Output_Softmax')
])
# เมื่อโมเดลคอมไพล์ เรามักจะจับคู่ Softmax กับ Loss Function ที่เหมาะสม
model.compile(optimizer='adam',
loss='categorical_crossentropy', # คู่หูของ Softmax
metrics=['accuracy'])
model.summary()5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในโลกของวิศวกรหน้างาน พี่มีกฎเหล็กที่ต้องจำให้ขึ้นใจเมื่อต้องใช้งาน Softmax มาฝากครับ:
- Softmax + Cross-Entropy คือเนื้อคู่กัน (The Dynamic Duo):
เมื่อน้องใช้ Softmax ในชั้น Output น้อง ต้อง ใช้ Loss Function เป็น Cross-Entropy (เช่น
categorical_crossentropyหรือsparse_categorical_crossentropy) เสมอ!, เพราะคณิตศาสตร์เบื้องหลังของมันถูกออกแบบมาให้หักล้างกับฟังก์ชัน Exponential ของ Softmax ได้อย่างสวยงาม ทำให้การคำนวณ Gradient ย้อนกลับ (Backpropagation) มีความเสถียรและโมเดลเรียนรู้ได้เร็วมากครับ อย่าเผลอเอา Mean Squared Error (MSE) มาจับคู่กับ Softmax เชียวนะครับ ไม่งั้นโมเดลจะเรียนรู้ช้าจนแทบคลานเลยล่ะ! - เมื่อไหร่ไม่ควรใช้ Softmax? (Mutually Exclusive Rule): Softmax ถูกออกแบบมาเพื่อปัญหาที่ “คลาสแยกขาดจากกัน (Mutually Exclusive)” เท่านั้นครับ หมายความว่า รูป 1 รูป ต้องเป็นคำตอบเดียว เช่น ถ้าเป็นสุนัข ก็ต้องไม่ใช่แมว (เปอร์เซ็นต์รวมต้องได้ 100%) แต่ถ้าน้องทำระบบ Multilabel Classification เช่น รูป 1 รูป มีทั้ง “คน”, “รถยนต์”, และ “สุนัข” โผล่มาพร้อมกันแบบนี้ ห้ามใช้ Softmax เด็ดขาด เพราะมันจะไปกดเปอร์เซ็นต์ของคลาสอื่นลง! ในกรณีนี้ให้เปลี่ยนไปใช้ Sigmoid แยกอิสระที่ output node แต่ละตัวแทนครับ
6. 🏁 บทสรุป (To be continued…)
สรุปสั้นๆ ให้เห็นภาพใหญ่เลยนะครับ: ในขณะที่ ReLU รับบทเป็นฮีโร่สายสกัด Feature ที่ทำงานว่องไวในชั้น Hidden Layers, Softmax คือ ผู้พิพากษาผู้ทรงคุณวุฒิในชั้น Output Layer ที่คอยแปลงคะแนนดิบทั้งหมดให้กลายเป็น “ความน่าจะเป็น (Probabilities)”
ด้วยคุณสมบัติของการบีบผลรวมให้เท่ากับ 1 เสมอ มันจึงเป็น Activation Function ที่ขาดไม่ได้เลยในงาน Multiclass Classification ไม่ว่าจะเป็นการอ่านป้ายทะเบียนรถ, การแยกประเภทของเสียในโรงงาน หรือแม้แต่ระบบแยกใบหน้าคน!
ในตอนต่อไป เราจะขยับจากเรื่องของ “ตัวกระตุ้น” ไปสู่เรื่องของ “ไม้เรียว” ที่ใช้สั่งสอนให้ AI ฉลาดขึ้น อย่างเจาะลึกในเรื่องของ Loss Functions แบบต่างๆ (เช่น Cross-Entropy ที่เราเกริ่นไป) ว่ามันทำงานอย่างไร รอติดตามกันนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p