ถอดรหัส ReLU: ร็อกสตาร์แห่งวงการ Activation Functions ผู้กอบกู้โลก Deep Learning

1. 🎯 ตอนที่ 14: ปลุกพลังสมองกลด้วย ReLU ร็อกสตาร์แห่งวงการ Activation Functions
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกคน! จิบกาแฟให้ชุ่มคอกันต่อเลยครับ หลังจากที่เราผจญภัยไปกับประตูกลรุ่นปู่ทวดอย่าง Sigmoid และรุ่นน้าอย่าง Tanh กันมาแล้ว วันนี้พี่จะพามาทำความรู้จักกับ “พระเอกตัวจริง” ที่พลิกโฉมวงการ Deep Learning และทำให้การประมวลผล Computer Vision ก้าวข้ามขีดจำกัดไปได้อย่างก้าวกระโดด ฟังก์ชันนั้นมีชื่อว่า ReLU (Rectified Linear Unit) ครับ
ในบริบทของโครงสร้างเครือข่ายประสาท ทำไมฟังก์ชันหน้าตาซื่อๆ ทื่อๆ ถึงกลายมาเป็นค่าเริ่มต้น (Default) ที่ทุกโมเดลระดับโลกต้องใช้? และมันมาแก้ปัญหาที่ Sigmoid ทำพังไว้ได้อย่างไร? วันนี้เราจะมาชำแหละดูกันครับ!
2. 📖 เปิดฉาก (The Hook)
ลองย้อนกลับไปในยุคดั้งเดิมของ AI ครับ… อย่างที่พี่เคยเล่าไป หากเราไม่ใส่ Activation Function คั่นระหว่าง Hidden Layers เลย เครือข่ายประสาทลึกๆ (Deep Neural Networks) ของเราก็จะเป็นแค่การซ้อนสมการเส้นตรง (Linear Transformation) ธรรมดาๆ ต่อให้ซ้อนกัน 100 ชั้น ผลลัพธ์สุดท้ายมันก็ยุบรวมเหลือเส้นตรงแค่เส้นเดียวอยู่ดี ซึ่งมันแก้ปัญหาซับซ้อน (Non-linear) ในโลกจริงไม่ได้เลย
ในอดีต นักวิจัยจึงพยายามเลียนแบบเซลล์สมองมนุษย์โดยการใช้ฟังก์ชันรูปตัว S อย่าง Sigmoid หรือ Tanh เป็นตัวกระตุ้น แต่อนิจจา… พอนำไปใช้กับโมเดลที่มีความลึกมากๆ มันกลับเจอปัญหาโลกแตกที่เรียกว่า Vanishing Gradients (ความชันจางหาย) คือพอค่าส่งผ่านเข้าไปลึกๆ ความชันมันจะแบนราบกลายเป็นศูนย์ ทำให้อัลกอริทึม Backpropagation ไม่สามารถคำนวณ Error ย้อนกลับไปอัปเดตน้ำหนัก (Weights) ในเลเยอร์แรกๆ ได้ โมเดลก็เลย “หยุดเรียนรู้” ซะงั้น!
จนกระทั่งในปี 2000 มีงานวิจัยที่นำเสนอไอเดียสุดโต่งแต่ง่ายดายที่ชื่อว่า ReLU ซึ่งเปรียบเสมือน “การ์ดเฝ้าผับสุดโหด” ที่ตั้งกฎง่ายๆ ว่า “ถ้านายพกพลังงานลบมา ฉันเตะทิ้งเป็น 0 แต่ถ้านายพกพลังงานบวกมา เชิญเดินผ่านเข้าไปเลยตามสบาย!” กฎง่ายๆ แค่นี้แหละครับที่กอบกู้โลก AI เอาไว้!
3. 🧠 แก่นวิชา (Core Concepts)
ในจักรวาลของฟังก์ชันกระตุ้น (Activation Functions) แหล่งข้อมูลระดับโลกได้อธิบายสถานะและกลไกของ ReLU (Rectified Linear Unit) ไว้ดังนี้ครับ:
- 1. สมการที่เรียบง่ายแต่ทรงพลัง (The Simple Math): สมการของ ReLU นั้นเรียบง่ายที่สุดในบรรดาฟังก์ชันทั้งหมดครับ คือ $f(x) = \max(0, x)$ ความหมายคือ ถ้าค่า Input ($x$) ติดลบ ผลลัพธ์จะถูกปัดเป็น 0 ทันที แต่ถ้า $x \ge 0$ ผลลัพธ์ก็จะปล่อยผ่านเป็นค่า $x$ ตรงๆ เลย
- 2. ทลายคำสาปความชันจางหาย (Solving Vanishing Gradients): จำได้ไหมครับว่า Sigmoid และ Tanh มีปัญหาเรื่องกราฟแบนราบ (Saturate) เมื่อเจอค่ามากๆ แต่สำหรับ ReLU ในฝั่งที่ค่าเป็นบวก กราฟมันจะพุ่งเป็นเส้นตรงขึ้นไปเรื่อยๆ (Non-saturating) ทำให้ ความชัน (Gradient) มีค่าเป็น 1 เสมอ! ด้วยเหตุนี้ เวลาทำ Backpropagation ส่งค่า Error กลับไป ความชันจึงไม่เลือนหายไประหว่างทาง ทำให้สามารถฝึกสอน (Train) เครือข่ายที่ลึกมากๆ (Deep Networks) ได้สำเร็จอย่างรวดเร็ว
- 3. ความเร็วแสงแห่งการคำนวณ (Computational Efficiency): การคำนวณ Sigmoid หรือ Tanh คอมพิวเตอร์ต้องหาค่า Exponential ($e^x$) ซึ่งกินทรัพยากรมหาศาล แต่สำหรับ ReLU คอมพิวเตอร์แค่เช็กเงื่อนไขว่า “น้อยกว่า 0 หรือเปล่า?” ถ้าใช่ก็เปลี่ยนเป็น 0 แค่นั้นจบ! มันจึงคำนวณได้ไวมากๆ และฮาร์ดแวร์ยุคใหม่ๆ (เช่น GPU/TPU) ก็รองรับการประมวลผลคำสั่งนี้ได้อย่างมีประสิทธิภาพสุดๆ
- 4. สปาร์ซิตี (Sparsity - การทำงานแบบประหยัดพลังงาน): การที่ ReLU ปัดค่าลบให้เป็น 0 หมายความว่าในเวลาใดเวลาหนึ่ง จะมีเซลล์ประสาทบางส่วนที่ไม่ทำงาน (Inactive หรือ 0) การที่เครือข่ายมีความโปร่ง (Sparsity) ไม่ได้ยิงสัญญาณมั่วซั่วทุกเซลล์ ช่วยให้โมเดลเบาขึ้นและสกัดลักษณะเด่น (Features) ได้ดีขึ้น
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ในหน้างานจริง การใช้ ReLU เป็นค่า Default สำหรับ Hidden Layers คือ “กฎทองคำ” ของนักพัฒนา AI เลยครับ ลองดูตัวอย่างการสร้าง CNN สำหรับงานภาพด้วย Keras/TensorFlow กันดูครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
# -------------------------------------------------------------
# ตัวอย่างที่ 1: การเขียนฟังก์ชัน ReLU ด้วย Python แบบดิบๆ (เพื่อความเข้าใจ)
# -------------------------------------------------------------
def simple_relu(x):
# แค่เช็กเงื่อนไขง่ายๆ นี่แหละครับความลับของความเร็ว!
return max(0, x)
# -------------------------------------------------------------
# ตัวอย่างที่ 2: การใช้ ReLU ในสถาปัตยกรรม CNN ด้วย Keras
# -------------------------------------------------------------
model = models.Sequential([
# Input Layer ดึงภาพเข้ามา
layers.InputLayer(input_shape=(224, 224, 3)),
# 📌 Convolutional Layer ที่ 1 (ใช้ ReLU เพื่อความไวและกัน Gradient หาย)
# การตั้งค่า activation='relu' คือเวทมนตร์มาตรฐานของยุคนี้
layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu', name="Conv_1"),
layers.MaxPooling2D(pool_size=(2, 2)),
# 📌 Convolutional Layer ที่ 2 (ยังคงเชื่อใจ ReLU)
layers.Conv2D(filters=128, kernel_size=(3, 3), activation='relu', name="Conv_2"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
# 📌 Hidden Layer แบบ Fully Connected (ก็ยังใช้ ReLU)
layers.Dense(256, activation='relu', name="Dense_Hidden"),
# Output Layer (งานแยกคลาส แนะนำให้ใช้ Softmax เพื่อเป็นผู้พิพากษาขั้นสุดท้าย)
layers.Dense(10, activation='softmax', name="Output_Layer")
])
model.summary()5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
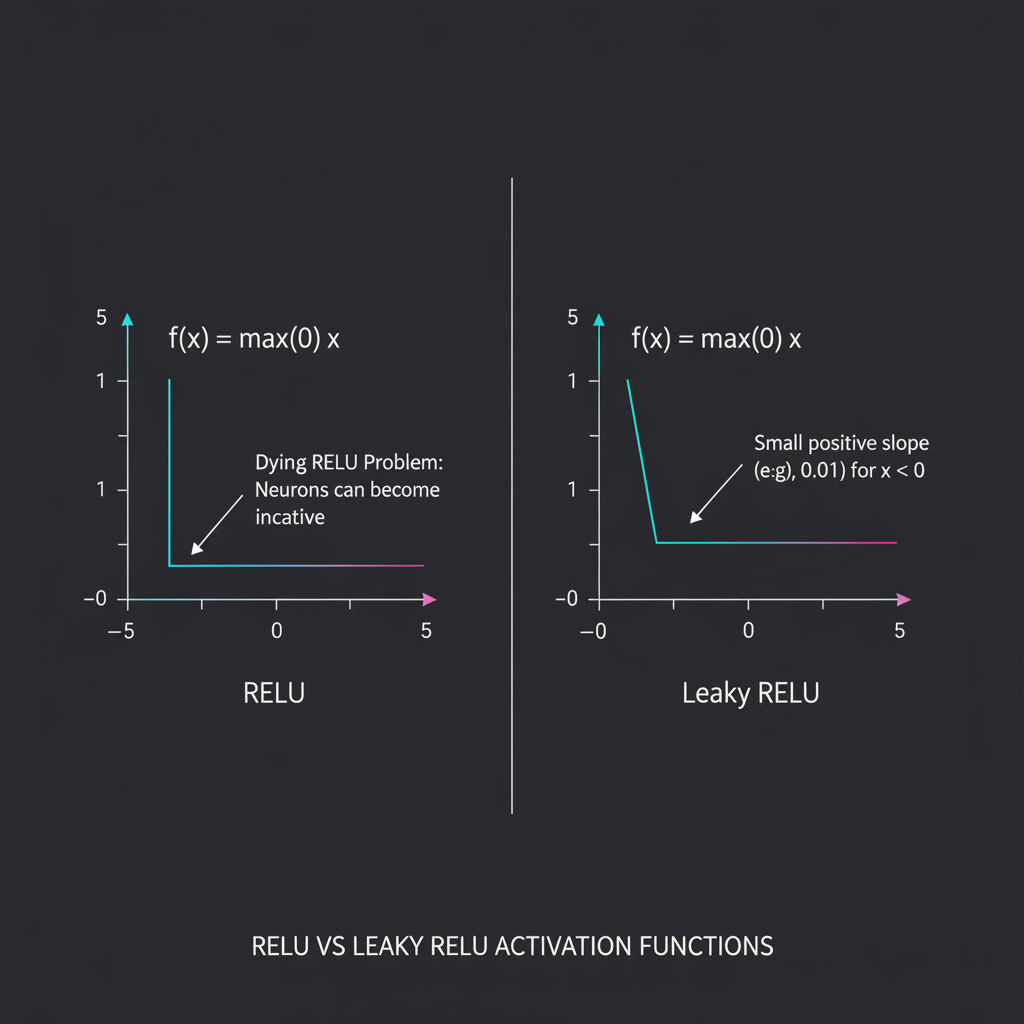
ถึงแม้ ReLU จะเป็นร็อกสตาร์ แต่ถ้าเราเป็นวิศวกรหน้างาน เราต้องรู้จุดอ่อนของมันครับ ซึ่งพี่ขอเตือนให้ระวังปัญหาที่เรียกว่า “โรคซึมเศร้าของเซลล์ประสาท (The Dying ReLU Problem)”
- อาการของโรค: ลองจินตนาการว่าในระหว่างการ Train เราตั้งค่า Learning Rate สูงเกินไป ทำให้น้ำหนัก (Weights) ถูกอัปเดตแกว่งไปมาอย่างรุนแรง หากบังเอิญมีเซลล์ประสาทตัวไหนที่รับผลรวม Weighted Sum ออกมา “ติดลบตลอดเวลา” (ไม่ว่าข้อมูลภาพแบบไหนเข้ามา) สิ่งที่เกิดขึ้นคือ ReLU จะเตะค่าทิ้งเป็น 0 เสมอ… พอมันพ่นค่า 0 ความชัน (Gradient) ก็เป็น 0 ทำให้เซลล์ประสาทตัวนั้น “ตาย (Die)” ไปอย่างถาวร ไม่ยอมตื่นมาเรียนรู้อะไรอีกเลย! บางครั้งเราอาจพบว่าโหนดในเครือข่ายของเราตายไปกว่าครึ่งเลยนะครับ
- ทางรอดที่ 1 (Leaky ReLU): หากเจอปัญหานี้ เราสามารถเปลี่ยนไปใช้ Leaky ReLU ได้ครับ ฟังก์ชันนี้จะยอมให้กราฟในฝั่งลบมี “ความชันเล็กน้อย” (เช่น $f(x) = \max(0.01x, x)$) เพื่อประคองน้ำให้ไหลซึมผ่านได้บ้าง (Leak) นิวรอนก็จะมีโอกาสฟื้นคืนชีพกลับมาได้ครับ
- ทางรอดตระกูลอื่นๆ: ปัจจุบันยังมีวิวัฒนาการต่อยอดอีกมากมาย เช่น PReLU (ให้ AI เรียนรู้ค่า Leak เองเลย) หรือ ELU / SELU ที่ผสมผสานความโค้งแบบ Exponential เข้าไปในฝั่งลบ เพื่อให้ความชันลื่นไหล (Smooth) ยิ่งขึ้น
- ข้อแนะนำ: โดยทั่วไปพี่แนะนำให้ “เริ่มที่ ReLU เสมอ” เพื่อความไวและเป็นบรรทัดฐาน แต่ถ้าจูนแล้วโมเดลมันตื้อ ทายมั่ว หรือเหมือนเซลล์มันตาย ค่อยขยับไปเปลี่ยนกระบวนท่าเป็น Leaky ReLU หรือ ELU ครับ
6. 🏁 บทสรุป (To be continued…)
สรุปให้เห็นภาพใหญ่เลยนะครับ ReLU (Rectified Linear Unit) คือฟังก์ชันกระตุ้นที่ก้าวเข้ามาปฏิวัติสถาปัตยกรรมโครงข่ายประสาท (Network Architectures) อย่างแท้จริง มันเปลี่ยนยุคสมัยจากสมการรูปตัว S ที่คำนวณช้าและมีปัญหา Gradient หาย มาเป็นสวิตช์เปิด-ปิดง่ายๆ $\max(0, x)$ ที่ทรงประสิทธิภาพ จนกลายมาเป็น ค่าเริ่มต้น (Default) สำหรับ Hidden Layers ในทุกๆ โครงสร้างระดับ Deep Learning ในปัจจุบัน
กฎทองคำประจำวันสำหรับน้องๆ ที่ออกแบบเน็ตเวิร์ก คือ: “ซ่อนลึกๆ ให้ใช้ ReLU (ใน Hidden Layers) ชี้ขาดให้จบให้ใช้ Softmax/Sigmoid (ใน Output Layer)” ครับ!
ในตอนถัดไป เราจะขยับจากส่วนประกอบเล็กๆ ไปสู่การดูพฤติกรรมภาพรวมกันบ้าง ว่า AI ของเรามันรู้ตัวได้อย่างไรว่ามัน “ทายผิด” พี่จะพาไปเจาะลึก Loss Functions (ฟังก์ชันความสูญเสีย) ที่เป็นเหมือนแส้คอยเฆี่ยนให้โมเดลเก่งขึ้น ห้ามพลาดนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p