ถอดรหัส Tanh: นักทูตสายสมดุล ผู้ยกระดับการเรียนรู้ของสมองกล (Activation Functions)
1. 🎯 ตอนที่ 13: ถอดรหัส Tanh นักทูตสายสมดุล ผู้ยกระดับการเรียนรู้ของสมองกล
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกคน! มานั่งล้อมวงจิบกาแฟกันต่อครับ หลังจากตอนที่แล้วเราได้พูดถึงปู่ทวดอย่าง Sigmoid กันไปแล้ว วันนี้พี่จะพามาทำความรู้จักกับลูกพี่ลูกน้องของมันที่ถูกสร้างมาเพื่อ “อุดรอยรั่ว” ของ Sigmoid โดยเฉพาะ ฟังก์ชันนี้มีชื่อว่า Hyperbolic Tangent หรือที่เราเรียกกันติดปากว่า Tanh (แทน-เอช) ครับ
ในบริบทที่กว้างขึ้นของโลก Deep Learning ฟังก์ชัน Tanh เคยเป็นตัวท็อปที่ฮิตสุดๆ ในยุคก่อนที่ฮีโร่อย่าง ReLU จะถือกำเนิดขึ้นมา เรามาเจาะลึกกันดีกว่าว่า Tanh มีทีเด็ดอะไร ทำไมมันถึงทำให้ AI เรียนรู้ได้เร็วกว่าเดิม และทำไมสุดท้ายมันถึง (เกือบ) โดนปลดระวางจาก Hidden Layers ทั่วไป แต่กลับไปเกิดใหม่เป็นซูเปอร์สตาร์ในวงการ AI สายภาษาและเวลา (RNN/LSTM) แทน!
2. 📖 เปิดฉาก (The Hook)
ลองนึกภาพตามพี่นะครับ สมมติว่าเรามีสายพานลำเลียงในโรงงานที่กำลังส่งข้อมูล (ตัวเลข) จากเซลล์ประสาทชั้นหนึ่งไปยังอีกชั้นหนึ่ง ถ้าเราใช้ Sigmoid (ที่มีค่าตั้งแต่ 0 ถึง 1) เป็นตัวคัดกรอง ข้อมูลทั้งหมดที่ถูกส่งต่อไปจะเป็น “ค่าบวก” เสมอครับ พอข้อมูลเทไปทางฝั่งบวกฝั่งเดียว (Not zero-centered) เวลาที่อัลกอริทึม Backpropagation ต้องปรับค่าน้ำหนัก (Weights) มันจะเกิดอาการ “วิ่งซิกแซก” ไร้ทิศทาง ทำให้โมเดลของเราปรับตัวได้ช้าและหาจุดสมดุลได้ยากมากๆ
นักวิจัยเลยคิดว่า “ทำไมเราไม่จับกราฟรูปตัว S ของ Sigmoid มากดให้มันตกลงมาอยู่ตรงกลาง (Zero-centered) ซะเลยล่ะ?” และนั่นแหละครับคือที่มาของ Tanh ฟังก์ชันที่เปรียบเสมือนนักทูตผู้รักความสมดุล มันช่วยดึงข้อมูลให้มีค่าเฉลี่ยอยู่ใกล้ศูนย์ ทำให้เลเยอร์ถัดไปทำงานได้ง่ายขึ้น และฝึกสอน (Train) ได้ไวขึ้นอย่างเห็นได้ชัดเลยล่ะครับ!
3. 🧠 แก่นวิชา (Core Concepts)
ในจักรวาลของฟังก์ชันกระตุ้น (Activation Functions) แหล่งข้อมูลได้อธิบายคุณสมบัติเด่นของ Tanh ไว้ดังนี้ครับ:
- 1. กำเนิดจากตระกูล S-Curve (The S-Shape): ฟังก์ชัน Tanh เป็นหนึ่งในฟังก์ชันตระกูล Sigmoidal (รูปตัว S) เช่นเดียวกับ Logistic Sigmoid มันมีความต่อเนื่องและหาอนุพันธ์ (Differentiable) ได้ในทุกๆ จุด ซึ่งเป็นคุณสมบัติที่จำเป็นอย่างยิ่งสำหรับการใช้ Gradient Descent ในการปรับน้ำหนัก สมการของมันคือ $tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$
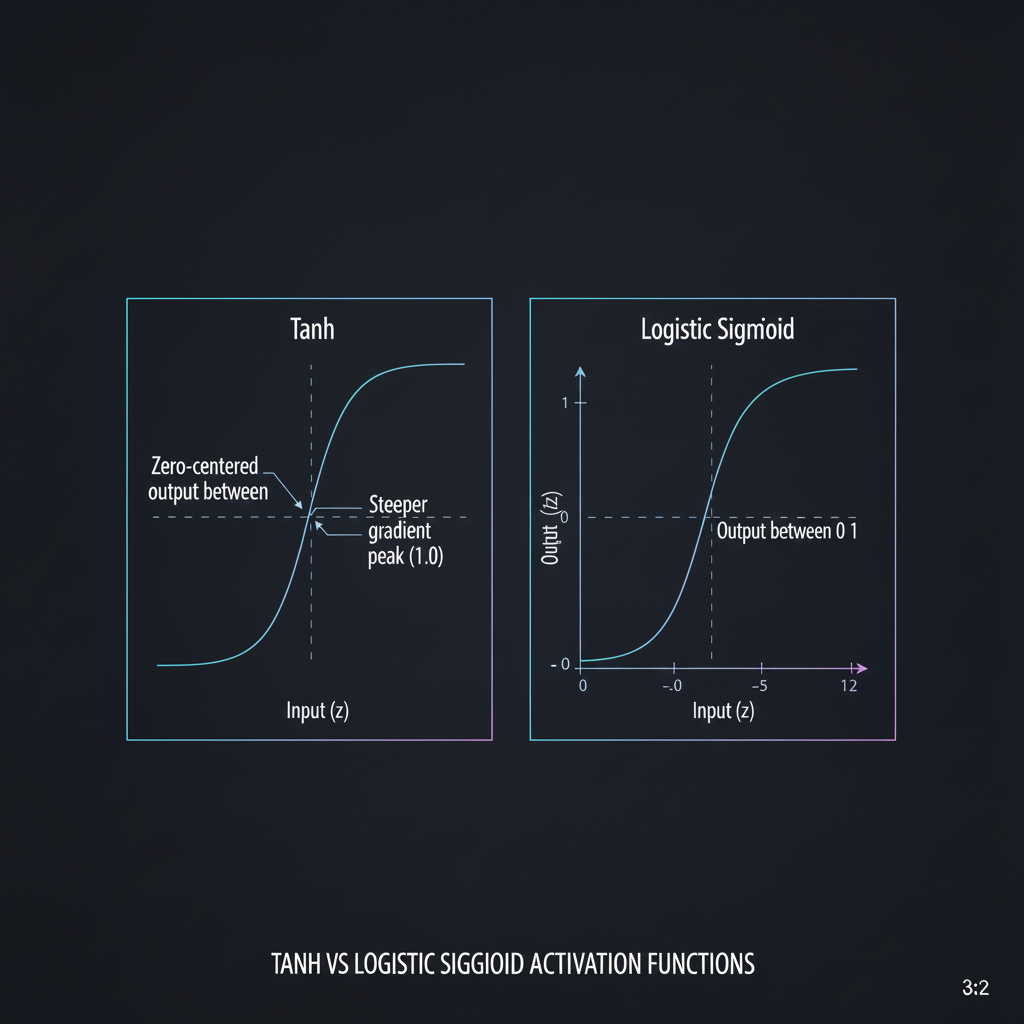
- 2. คุณสมบัติ Zero-Centered (จุดกึ่งกลางที่ศูนย์): จุดเด่นที่สุดที่เหนือกว่า Sigmoid คือ Tanh จะ “บีบอัด” ข้อมูล (Squish) ให้ไปอยู่ในช่วง -1 ถึง 1 เสมอ (ในขณะที่ Sigmoid บีบให้อยู่ในช่วง 0 ถึง 1) การที่มันสมมาตร (Symmetric) รอบจุดกำเนิด ทำให้ผลลัพธ์ของมันมีค่าเฉลี่ยเข้าใกล้ 0 ซึ่งช่วยให้การเรียนรู้ของเลเยอร์ถัดไปมีเสถียรภาพและคอนเวิร์จ (Converge) เร็วขึ้นมากครับ
- 3. ความชันที่เหนือกว่า (Steeper Gradient): หากเราเอาอนุพันธ์ (Derivative) ของทั้งสองฟังก์ชันมาพล็อตดูกราฟ จะพบว่าค่าความชันสูงสุดของ Tanh จะอยู่ที่ 1.0 (ที่จุด x=0) ในขณะที่ของ Sigmoid จะมีค่าสูงสุดแค่ 0.25 เท่านั้น! การมีความชันที่มากกว่า แปลว่าเวลาทำ Backpropagation สัญญาณความผิดพลาด (Error) จะถูกลดทอนน้อยกว่า ทำให้การฝึกสอนโมเดลทำได้ดีกว่า Sigmoid อย่างชัดเจนครับ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้เห็นภาพว่าการทำงานของ Tanh และการหาอนุพันธ์ของมันง่ายแค่ไหน (ในมุมของคณิตศาสตร์เบื้องหลัง) และการเรียกใช้งานใน Keras ทำอย่างไร ดูโค้ดด้านล่างนี้เลยครับ:
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
# -------------------------------------------------------------
# ส่วนที่ 1: คณิตศาสตร์เบื้องหลัง (Under the hood)
# -------------------------------------------------------------
def tanh_function(x):
# สมการของ Hyperbolic Tangent
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
def tanh_derivative(x):
# ความเจ๋งคือ อนุพันธ์ของมันสามารถคำนวณจากผลลัพธ์ตัวมันเองได้เลย
# สูตรคือ: 1 - tanh(x)^2 (แหล่งข้อมูลหน้า 654, 667)
y = tanh_function(x)
return 1.0 - np.square(y)
# -------------------------------------------------------------
# ส่วนที่ 2: การเรียกใช้ใน Keras แบบวิศวกรตัวจริง
# -------------------------------------------------------------
model = models.Sequential([
# สมมติรับภาพเข้ามา
layers.Flatten(input_shape=(28, 28)),
# 📌 การใช้ Tanh ใน Keras ทำได้ง่ายๆ แค่ระบุ activation='tanh'
# ในอดีตโครงสร้างคลาสสิกอย่าง LeNet-5 ก็ใช้ Tanh สำหรับ Hidden Layers นะครับ!
layers.Dense(128, activation='tanh'),
layers.Dense(64, activation='tanh'),
# Layer สุดท้ายใช้ Softmax สำหรับแยกคลาส
layers.Dense(10, activation='softmax')
])คอมเมนต์: สังเกตสูตรหาอนุพันธ์ 1.0 - np.square(y) ให้ดีนะครับ นี่คือความเรียบง่ายที่ทำให้คอมพิวเตอร์คำนวณย้อนกลับ (Backpropagation) ได้อย่างรวดเร็ว!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในฐานะวิศวกรที่ลุยงานหน้างาน พี่มีข้อควรระวังเกี่ยวกับการใช้ Tanh ที่อยากจะเตือนน้องๆ ไว้ครับ:
- คำสาปที่หนีไม่พ้น (The Vanishing Gradient Problem): ถึงแม้ Tanh จะทำตัวเลขให้มีศูนย์เป็นศูนย์กลางและมี Gradient ที่ดีกว่า Sigmoid แต่สุดท้ายมันก็หนีไม่พ้นปัญหา “Gradient หาย” อยู่ดีครับ! เพราะถ้า Input ($z$) มีค่าบวกมากๆ หรือลบมากๆ กราฟมันจะอิ่มตัว (Saturate) จนแบนราบ และความชันจะกลายเป็น 0 พอความชันเป็น 0 ปุ๊บ เซลล์ประสาทของเราก็จะหยุดเรียนรู้ทันที! (นี่คือเหตุผลหลักที่ใน Hidden layer ของโมเดลยุคใหม่ เราถึงอพยพไปใช้ ReLU กันหมดครับ)
- ทางรอดของ Tanh (Batch Normalization): หากน้องๆ จำเป็นต้องใช้ Tanh จริงๆ (เพราะสมการบางอย่างต้องการให้ออกมาเป็น -1 ถึง 1) พี่แนะนำให้ใช้ร่วมกับการทำ Batch Normalization ครับ การทำ Batch Norm ก่อนเข้า Activation จะช่วยดึงข้อมูลไม่ให้มันหลุดไปอยู่ในโซนอิ่มตัว (Saturating region) ทำให้ Tanh ยังคงส่งผ่าน Gradient ได้ดีอยู่ครับ
- สรวงสวรรค์ของ Tanh (RNN & LSTM): ปัจจุบันเราอาจจะไม่ค่อยเห็น Tanh ในดงของ Convolutional Neural Networks (CNN) แล้ว แต่มันยังมีบทบาทสำคัญและเป็นพระเอกอยู่ในโมเดลสายลำดับเวลาอย่าง Recurrent Neural Networks (RNN) และโดยเฉพาะในเซลล์ LSTM (Long Short-Term Memory) ครับ! ใน LSTM เราใช้ Tanh เพื่อควบคุมและสร้างข้อมูลใหม่ให้อยู่ในขอบเขต -1 ถึง 1 เพื่อควบคุมสถานะ (Cell State) ไม่ให้มันขยายตัวจนระเบิดนั่นเองครับ
6. 🏁 บทสรุป (To be continued…)
สรุปสั้นๆ ครับ Tanh คือวิวัฒนาการที่ยอดเยี่ยมของ Sigmoid โดยมันช่วยแก้ปัญหาเรื่องข้อมูลที่ไม่สมดุล (Zero-centered) ทำให้การ Train ทำได้รวดเร็วและมีเสถียรภาพมากขึ้น แต่ทว่า มันก็ยังมีจุดอ่อนใหญ่คือปัญหา Vanishing Gradients ที่ทำให้มันไม่เหมาะกับการนำไปเรียงซ้อนกันเป็น Deep Network ลึกๆ ในยุคปัจจุบัน
กฎเหล็กที่ควรจำคือ: “สำหรับ Hidden Layers ให้หนีไปใช้ ReLU ก่อน แต่ถ้าต้องทำระบบ LSTM หรือต้องการกด Output ให้อยู่ในช่วง -1 ถึง 1 เมื่อไหร่… Tanh คือเพื่อนแท้ของคุณครับ!”
ในตอนต่อไป เราจะมาพบกับร็อกสตาร์ตัวจริงที่เข้ามาพลิกโฉมวงการ Computer Vision และแก้ปัญหา Vanishing Gradient ใน Hidden Layers ได้อย่างเด็ดขาด นั่นก็คือ ReLU (Rectified Linear Unit) ห้ามพลาดนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p