ถอดรหัส Sigmoid: ฮีโร่ยุคบุกเบิก และคดีฆาตกรรม Gradient ในโลก Deep Learning

1. 🎯 ตอนที่ 12: ถอดรหัส Sigmoid ฮีโร่ยุคบุกเบิก และคดีฆาตกรรม Gradient
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกคน! มาล้อมวงจิบกาแฟกันต่อครับ ในตอนที่แล้วเราได้เห็นภาพรวมของประตูกลแห่งความคิด หรือ ฟังก์ชันกระตุ้น (Activation Functions) กันไปแล้ว วันนี้พี่จะขอเจาะลึกไปที่ฟังก์ชันระดับ “ตำนาน” ที่เป็นเหมือนอาจารย์ใหญ่ผู้ปูทางให้เกิดการฝึกสอนโครงข่ายประสาทเทียมหลายชั้น (Multilayer Perceptrons) จนสำเร็จ ฟังก์ชันนั้นมีชื่อว่า “Sigmoid” (ซิกมอยด์) หรือบางครั้งเราก็เรียกมันว่า Logistic Function ครับ
ทำไมยุคหนึ่งทุกคนถึงแห่กันใช้แต่ Sigmoid? แล้วทำไมจู่ๆ ในยุค Deep Learning ปัจจุบัน มันถึงถูกปลดระวางจากการเป็นฟังก์ชันกระตุ้นในชั้นซ่อน (Hidden Layers) จนแทบไม่เหลือที่ยืน? วันนี้เราจะมาสืบคดีนี้กันครับ!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าน้องกำลังสร้าง AI เพื่อตรวจจับ “น็อตที่มีรอยร้าว” โดยให้โมเดลทำนายออกมาว่ารูปนี้คือน็อตดี หรือ น็อตเสีย ถ้าเราไม่มี Activation Function เลย สมองกลของเราก็จะเป็นแค่ “สมการเส้นตรง (Linear Transformation)” ทื่อๆ ที่รับค่าพิกเซลมาคูณน้ำหนักแล้วบวกกัน ผลลัพธ์ที่ได้อาจจะพุ่งทะลุไปถึงหลักหมื่น หรือติดลบหลักพัน ซึ่งมันตีความหมายเป็น “ความน่าจะเป็น” ยากมากเลยใช่ไหมครับ?
ในอดีต (ยุค Perceptron) เราพยายามแก้ปัญหานี้ด้วยการใช้ฟังก์ชันขั้นบันได (Step Function) คือสับสวิตช์เลยว่า ถ้ายอดรวมมากกว่า 0 ให้ตอบ 1 (น็อตดี), ถ้าน้อยกว่าให้ตอบ 0 (น็อตเสีย) ฟังดูง่ายและเหมือนเซลล์สมองมนุษย์ดีใช่มั้ยครับ? แต่มันมีจุดตายร้ายแรงคือ “กราฟขั้นบันไดมันมีความชันเป็นศูนย์ (ราบเรียบ) ในทุกๆ จุด และหาอนุพันธ์ (Derivative) ไม่ได้ในจุดที่หักมุม!”
เมื่อความชันเป็นศูนย์ อัลกอริทึมที่จะคอยปรับค่าน้ำหนักให้โมเดลเก่งขึ้นอย่าง Backpropagation (การแพร่กลับ) และ Gradient Descent (การไต่ลงตามความชัน) ก็เหมือนโดนปิดตา มันไม่รู้จะเดินไปทางไหนเพื่อลดข้อผิดพลาด
และนี่คือวินาทีที่ฮีโร่ของเราขี่ม้าขาวเข้ามาช่วยชีวิตวงการ AI… ขอต้อนรับ Sigmoid Function!
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทของโครงข่ายประสาทเทียม แหล่งข้อมูลได้อธิบายบทบาทและคุณสมบัติของ Sigmoid ไว้ดังนี้ครับ:
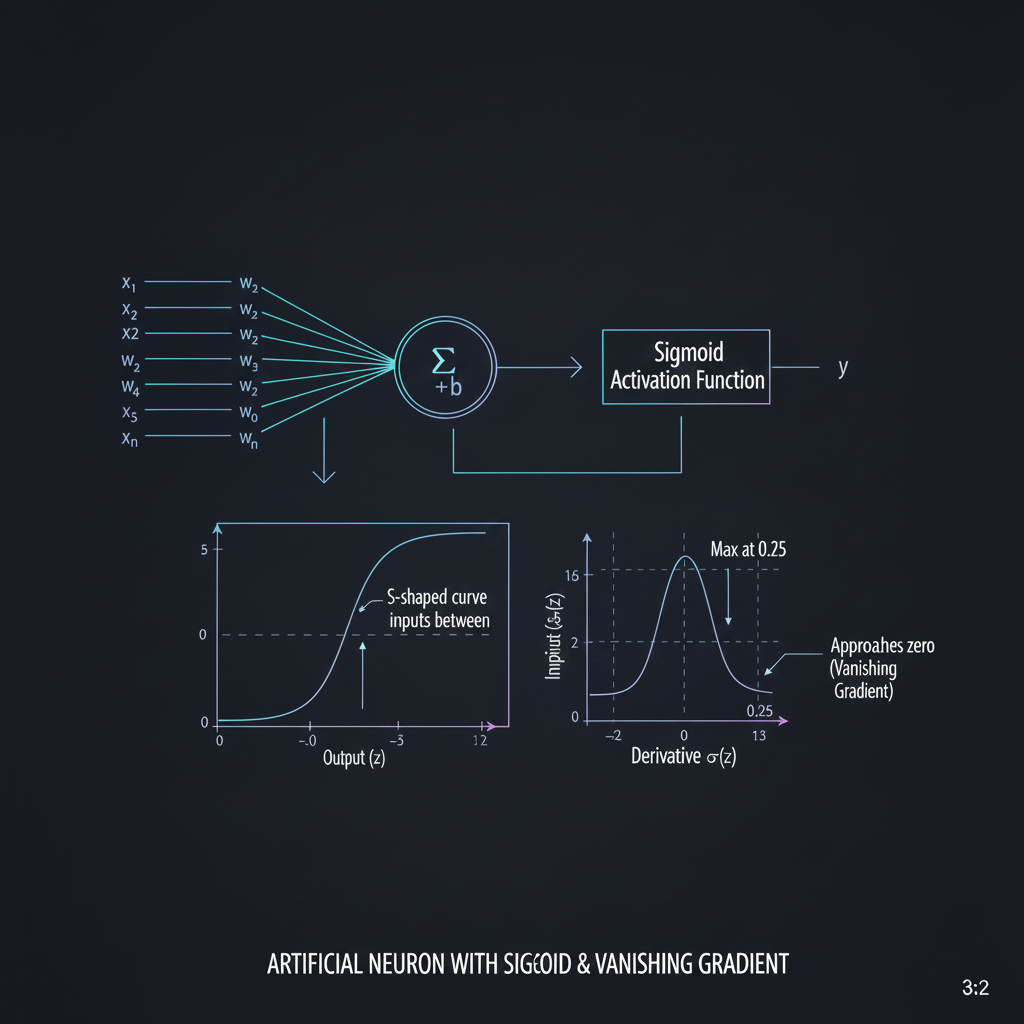
- 1. นักบีบอัดข้อมูล (The Squasher): ฟังก์ชัน Sigmoid (หรือ Logistic Function) มีสมการทางคณิตศาสตร์คือ $\sigma(z) = \frac{1}{1 + e^{-z}}$ หน้าที่หลักของมันคือการ “บีบอัด (Squish)” ค่า Input (z) ไม่ว่ามันจะกว้างใหญ่จาก $-\infty$ ถึง $+\infty$ ให้กลายมาเป็นตัวเลขที่อยู่ในช่วง 0 ถึง 1 เสมอ
- 2. รูปทรงตัว S อันงดงาม (The S-Curve): เมื่อนำไปพล็อตเป็นกราฟ มันจะเกิดเป็นเส้นโค้งรูปตัว S (S-shaped curve) ที่มีความสมูท (Smooth) และต่อเนื่อง ความสมูทนี่แหละครับคือ “หัวใจสำคัญ” เพราะมันทำให้ฟังก์ชันนี้ หาอนุพันธ์ (Differentiable) ได้ทุกจุด เปิดทางให้ Gradient Descent สามารถกลิ้งตัวลงมาตามความชันเพื่อปรับค่าน้ำหนัก (Weights) ได้สำเร็จ
- 3. การตีความเป็นความน่าจะเป็น (Probability Interpretation): เนื่องจากผลลัพธ์ของมันถูกขังไว้ระหว่าง 0 ถึง 1 เสมอ เราจึงสามารถนำตัวเลขที่ได้มาตีความหมายเป็น ความน่าจะเป็น (Probability) ได้อย่างสมบูรณ์แบบ เช่น ถ้า AI คายค่าออกมา 0.85 เราก็มั่นใจได้เลยว่าโมเดลทำนายรูปนี้เป็นน็อตเสียด้วยความมั่นใจ 85% ด้วยเหตุนี้ Sigmoid จึงเป็นที่นิยมอย่างมากสำหรับงาน Binary Classification (การแยกแยะ 2 คลาส)
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ความสวยงามอีกอย่างของ Sigmoid คือ อนุพันธ์ (Derivative) ของมันสามารถคำนวณได้จากผลลัพธ์ของตัวมันเองเลยครับ! ลองดู Python Code ที่ใช้อธิบายสมการและอนุพันธ์ของมันกัน:
import numpy as np
# 1. ฟังก์ชัน Sigmoid แบบดั้งเดิม
def sigmoid(x):
# คืนค่าผลลัพธ์ที่ถูกบีบให้อยู่ในช่วง (0, 1)
return 1.0 / (1.0 + np.exp(-x))
# 2. ฟังก์ชันหาความชัน (Derivative) ของ Sigmoid
def sigmoid_derivative(x):
# ความเจ๋งคือ อนุพันธ์ของมันคือ: σ(x) * (1 - σ(x))
# เราใช้ความชันนี้แหละ ในการทำ Backpropagation!
s = sigmoid(x)
return s * (1.0 - s)
# ลองทดสอบกับค่าต่างๆ
inputs = np.array([-10, -1, 0, 1, 10])
print("Inputs:", inputs)
print("Sigmoid Outputs:", sigmoid(inputs))
# สังเกตว่าที่ค่า x=0 (ตรงกลาง), Sigmoid จะได้ค่า 0.5 พอดีคอมเมนต์: สังเกตบรรทัดสูตรอนุพันธ์ s * (1.0 - s) ให้ดีนะครับ นี่คือความเรียบง่ายที่ทำให้มันฮิตมากในยุคก่อน แต่สูตรนี้แหละครับ… ที่ซ่อน “ยาพิษ” เอาไว้!
5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
แล้วทำไมเดี๋ยวนี้เวลาเราเปิดดูโค้ดของสถาปัตยกรรมดังๆ (เช่น ResNet, YOLO หรือ VGG) เราแทบไม่เห็นคนใช้ Sigmoid ใน Hidden Layers เลย? พี่ขอพาน้องๆ ไปเปิดโปง “คดีฆาตกรรม Gradient” ที่เกิดจากฟังก์ชันนี้กันครับ:
- ปัญหาใหญ่อันดับ 1: คดี Vanishing Gradient (ความชันจางหาย): น้องลองย้อนกลับไปดูกราฟของ Sigmoid ครับ เวลาที่ Input มีค่าเยอะมากๆ (เช่น $x=10$) หรือติดลบมากๆ (เช่น $x=-10$) กราฟมันจะเริ่ม “แบนราบ (Saturate)” พอกราฟแบนแปลว่าอะไร? แปลว่าความชัน (Derivative) มีค่าเข้าใกล้ 0 ครับ! เวลาโมเดลทำ Backpropagation มันจะต้องเอาความชันมาคูณกันเรื่อยๆ ถอยหลังกลับไป พอเอาเลขที่เกือบเป็น 0 มาคูณต่อกัน เลเยอร์แรกๆ ของ Network ก็จะได้ค่า Gradient เป็นศูนย์ ทำให้เลเยอร์ต้นๆ “หยุดเรียนรู้ (Stop learning)” ไปเลยสนิท!
- จุดอ่อนด้านคณิตศาสตร์ (Max Derivative = 0.25):
ความลับอีกอย่างที่หลายคนไม่รู้คือ ถ้าเราพลอตสมการอนุพันธ์
s * (1.0 - s)เราจะพบว่า ค่าความชันสูงสุดที่ Sigmoid ทำได้คือ 0.25 เท่านั้น! (เกิดที่จุด x=0) นั่นแปลว่าทุกๆ ครั้งที่ Error ส่งผ่านกลับมาทาง Sigmoid ในแต่ล่ะชั้น พลังของ Error จะถูกลดทอนลงไปอย่างน้อย 75% เสมอ! ลองคิดดูว่าถ้าน้องมีโมเดลลึก 10 ชั้น สัญญาณจะหดหายไปขนาดไหน - ข้อมูลไม่เป็นศูนย์กลาง (Not Zero-Centered): ผลลัพธ์ของ Sigmoid เป็นบวกเสมอ (0 ถึง 1) ทำให้เวลาส่งข้อมูลไปให้เลเยอร์ถัดไป ข้อมูลจะถูกดึงไปทางฝั่งบวกหมด ทำให้การทำ Gradient Descent วิ่งซิกแซกไปมาไร้ทิศทางและเรียนรู้ช้าลงครับ (นี่คือเหตุผลที่ยุคนั้นคนหนีไปใช้ Tanh ที่ออกค่า -1 ถึง 1 แทนเพื่อแก้ปัญหานี้)
6. 🏁 บทสรุป (To be continued…)
สรุปสั้นๆ ให้จำขึ้นใจเลยครับว่า: ถึงแม้ Sigmoid Function จะเป็นอัศวินผู้ปูทางให้เกิดการเรียนรู้แบบ Backpropagation ได้สำเร็จด้วยรูปทรงเส้นโค้งตัว S ที่หาอนุพันธ์ได้ แต่ด้วยจุดอ่อนเรื่องการทำตัวเป็นคอขวดที่บีบอัดจนความชันหายไป (Vanishing Gradient) มันจึงไม่เหมาะที่จะรับบทบาทเป็นด่านหน้าใน Hidden Layers ของ Deep Learning ยุคปัจจุบันอีกต่อไป (ซึ่งปัจจุบันเราหันไปใช้ฮีโร่คนใหม่อย่าง ReLU กันหมดแล้ว)
Best Practice กฎเหล็กประจำวัน: “จงใช้ Sigmoid เก็บไว้เป็นไม้ตายสุดท้าย ในชั้น Output Layer สำหรับงาน Binary Classification (ทายว่า ใช่/ไม่ใช่) เท่านั้นพอครับ!”
ในตอนต่อไป เราจะมาทำความรู้จักกับตัวท็อปที่มาฆ่า Sigmoid ในดง Hidden Layers อย่าง ReLU (Rectified Linear Unit) กัน ว่ามันมาอุดรอยรั่วนี้ได้อย่างไร ห้ามพลาดครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p