ถอดรหัส Activation Functions: ประตูกลแห่งความคิดที่ทำให้ AI ฉลาดล้ำลึก

1. 🎯 ตอนที่ 11: ถอดรหัส Activation Functions ประตูกลแห่งความคิดของ AI
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกคน! จิบกาแฟให้ชุ่มคอกันสักนิด วันนี้พี่จะพาเจาะลึกเข้าไปในชิ้นส่วนที่เล็กที่สุด แต่กลับ “สำคัญที่สุด” ชิ้นหนึ่งในสถาปัตยกรรม Deep Learning ชิ้นส่วนนี้เปรียบเสมือน “ผู้มีอำนาจตัดสินใจ” ในสมองกลของเรา นั่นก็คือ ฟังก์ชันกระตุ้น (Activation Functions) ครับ
เรามาดูกันว่าในบริบทที่กว้างขึ้นของพื้นฐาน Deep Learning นั้น ทำไมเราถึงขาดสมการคณิตศาสตร์เหล่านี้ไม่ได้ และมันช่วยเปลี่ยนสมการเส้นตรงทื่อๆ ให้กลายเป็น AI ที่สามารถตรวจจับรอยร้าวบนชิ้นงาน หรือแยกแยะใบหน้าคนได้อย่างไร!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการว่าโครงข่ายประสาทเทียมของเราคือ “บริษัทนักสืบ” ที่มีพนักงาน (Neurons) หลายร้อยคนเรียงกันเป็นชั้นๆ (Layers) ข้อมูลหลักฐานจะถูกส่งต่อกันไปเรื่อยๆ
ถ้าบริษัทนี้ไม่มีสิ่งที่เรียกว่า Activation Function พนักงานทุกคนก็จะทำงานแบบ “เส้นตรง (Linear Transformation)” ครับ นั่นคือ ได้ข้อมูลอะไรมา ก็แค่จับมาคูณน้ำหนัก (Weights) บวกไบแอส (Bias) แล้วส่งต่อให้คนถัดไปดื้อๆ เลย ปัญหาคือ ในทางคณิตศาสตร์แล้ว ไม่ว่าคุณจะเอาสมการเส้นตรงมาซ้อนกันกี่ร้อยชั้น ผลลัพธ์สุดท้ายมันก็ยุบรวมเหลือแค่สมการเส้นตรงสมการเดียวอยู่ดี! (เช่น $f(g(x)) = 2(5x - 1) + 3 = 10x + 1$)
ถ้าเป็นแบบนั้น AI ของเราจะแยกแยะได้แค่ปัญหาที่ขีดเส้นตรงแบ่งได้ (Linear Separable) ซึ่งในโลกความเป็นจริงของงาน Computer Vision ภาพรอยร้าวบนผิวโลหะ หรือภาพน้องหมาน้องแมว มันไม่มีทางขีดเส้นตรงแบ่งได้หรอกครับ! ด้วยเหตุนี้ Activation Function จึงต้องเข้ามารับบทเป็น “ประตูกล” ที่สร้างความบิดเบี้ยว (Non-linearity) ให้กับระบบ เพื่อให้ AI สามารถโอบกอดและเรียนรู้ความซับซ้อนของโลกใบนี้ได้ครับ
3. 🧠 แก่นวิชา (Core Concepts)
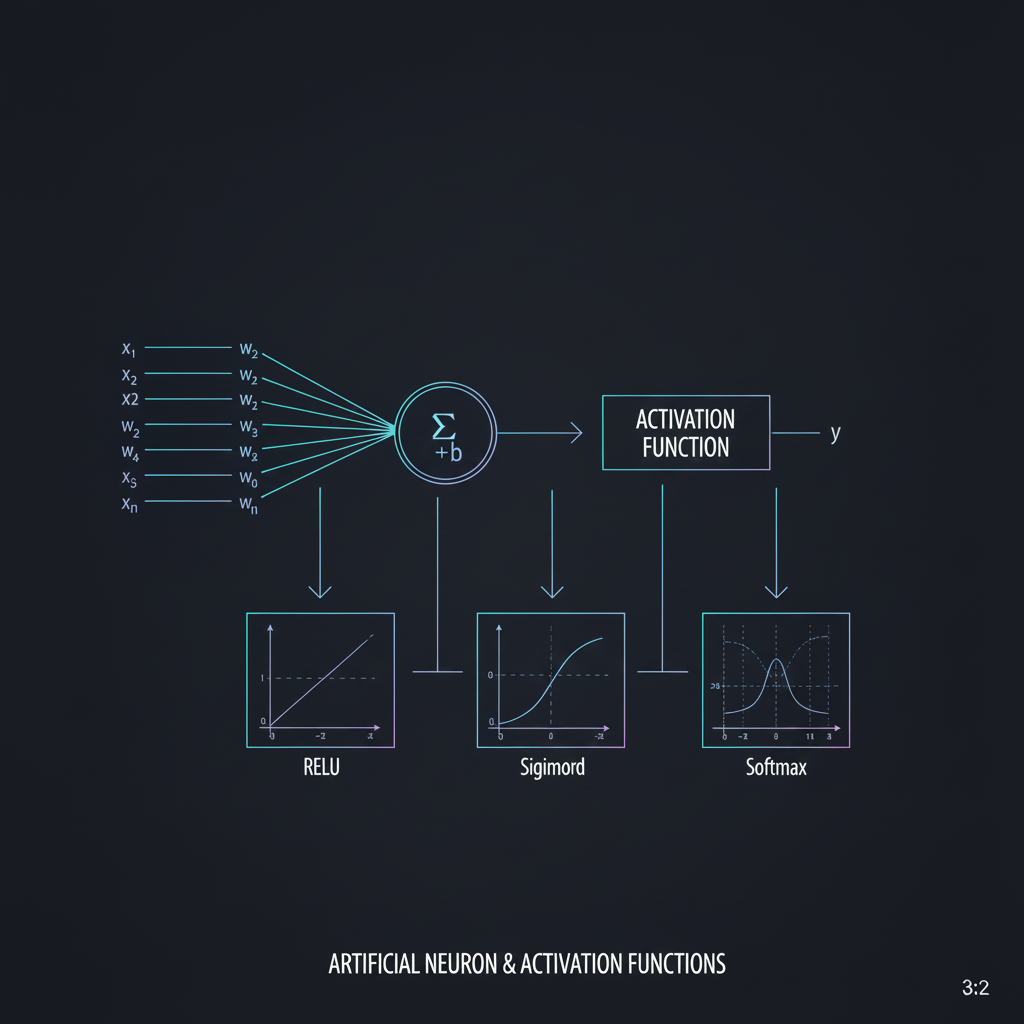
ในโลกของ Deep Learning แหล่งข้อมูลได้อธิบายฟังก์ชันกระตุ้นยอดฮิตที่เป็นมาตรฐานอุตสาหกรรมไว้ดังนี้ครับ:
1. Step Function (ปู่ทวดจอมเถรตรง): ในยุคแรกเริ่มของ Perceptron เราใช้ฟังก์ชันขั้นบันไดครับ กฎคือถ้ายอดรวม $\ge 0$ ให้ตอบ 1 (ยิงสัญญาณ), ถ้า $< 0$ ให้ตอบ 0 (เงียบ) ฟังดูสมเหตุสมผลเหมือนเซลล์สมองเป๊ะ แต่ปัญหาคือ “มันหาอนุพันธ์ (Derivative) ไม่ได้” ในจุดที่หักมุม และความชันเป็นศูนย์ในจุดอื่นๆ ทำให้เราไม่สามารถใช้อัลกอริทึม Backpropagation เพื่อฝึกสอนมันได้ ปัจจุบันจึงสูญพันธุ์ไปแล้วในงาน Deep Learning ครับ
2. Sigmoid / Logistic (นักการทูตผู้ประนีประนอม): เพื่อแก้ปัญหาความชัน ฟังก์ชันนี้จึงถูกคิดค้นขึ้นมา มันมีรูปทรงเป็นตัว S (S-curve) ที่บีบอัดค่าอินพุตที่เข้ามา (ไม่ว่าจะติดลบหรือบวกมหาศาล) ให้อยู่ในช่วง 0 ถึง 1 เสมอ ฟังก์ชันนี้หาอนุพันธ์ได้และเหมาะมากสำหรับชั้น Output ที่ต้องการทำนายผลแบบ “ใช่ หรือ ไม่ใช่” (Binary Classification) แต่มีข้อด้อยร้ายแรงคืออาการ “Gradient หาย (Vanishing Gradient)” เมื่อค่าอินพุตสูงหรือต่ำเกินไป
3. Tanh - Hyperbolic Tangent (นักทูตเวอร์ชันอัปเกรด): ทำงานคล้าย Sigmoid แต่บีบอัดค่าให้อยู่ในช่วง -1 ถึง 1 ทำให้ข้อมูลมีค่าเฉลี่ยอยู่ตรงกลางที่ 0 (Zero-centered) ซึ่งช่วยให้การเทรนใน Hidden Layers มีเสถียรภาพกว่า Sigmoid เล็กน้อย แต่ก็ยังหนีไม่พ้นปัญหา Vanishing Gradient อยู่ดี
4. ReLU - Rectified Linear Unit (ร็อกสตาร์แห่งวงการ): นี่คือ “พระเอก” ของงาน Deep Learning ยุคใหม่ครับ! สมการมันง่ายมาก: $f(x) = max(0, x)$ คือถ้าค่าติดลบ ให้ปัดเป็น 0 ไปเลย แต่ถ้าค่าเป็นบวก ก็ปล่อยผ่านไปดื้อๆ ความเรียบง่ายนี้ทำให้คอมพิวเตอร์คำนวณเร็วมาก และที่สำคัญคือช่วงบวกของมันไม่มีความอิ่มตัว (Non-saturating) ทำให้แก้ปัญหา Vanishing Gradient ได้อย่างชะงัด ปัจจุบัน ReLU คือตัวเลือก Default (ค่าเริ่มต้น) สำหรับ Hidden Layers เกือบทั้งหมดครับ
5. Softmax (ผู้พิพากษาชี้ขาด): ฟังก์ชันนี้คือวิวัฒนาการขั้นสุดของ Sigmoid แต่ออกแบบมาเพื่อสู้กับงานแบบ Multiclass Classification (แยกของหลายประเภท) โดยมันจะถูกวางไว้ที่ชั้น Output Layer เท่านั้น หน้าที่ของมันคือการแปลงค่าคะแนนดิบทั้งหมด ให้กลายเป็น “ความน่าจะเป็น (Probability)” ที่รวมกันแล้วได้ 1 (100%) พอดี ทำให้เรารู้ได้เลยว่า AI มั่นใจกี่เปอร์เซ็นต์ว่านี่คือภาพน็อตตัวผู้ หรือน็อตตัวเมีย
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้เห็นภาพว่าในหน้างานจริง เราเรียกใช้ประตูกลเหล่านี้ง่ายแค่ไหน ลองดูการสร้างโมเดล Keras สำหรับงาน Computer Vision แบบคลาสสิกกันครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential([
# Input จากภาพถูกยืดเป็น 1 มิติ
layers.Flatten(input_shape=(28, 28)),
# 📌 Hidden Layer ที่ 1: เราใช้ ReLU เป็นพระเอกในการสกัด Feature
# เหตุผล: คำนวณไว และป้องกันปัญหา Gradient เลือนหายไปในระหว่างเทรน
layers.Dense(128, activation='relu'),
# 📌 Hidden Layer ที่ 2: ก็ยังคงเชื่อใจ ReLU
layers.Dense(64, activation='relu'),
# 📌 Output Layer: สมมติว่าต้องการแยกประเภทชิ้นงาน 10 คลาส
# ใช้ Softmax เป็นผู้พิพากษา เพื่อให้ผลลัพธ์ออกมาเป็น % ความน่าจะเป็น
layers.Dense(10, activation='softmax')
])
# ถึงเวลาคอมไพล์ เราก็ใช้ Cross-entropy เป็นตัววัดความผิดพลาดที่คู่กับ Softmax
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในฐานะคนทำระบบหน้างานจริง พี่มีเรื่องต้องเตือนน้องๆ เกี่ยวกับ “หลุมพราง” ของ Activation Functions เหล่านี้ครับ:
- คำสาปของ Sigmoid และ Tanh (The Vanishing Gradient Problem): จำไว้เลยว่า อย่าใช้ Sigmoid หรือ Tanh ใน Hidden Layers ที่ซ้อนกันลึกๆ (Deep networks) เด็ดขาด! เพราะเวลาที่มันเจอค่าอินพุตเยอะๆ (บวกมากๆ หรือ ลบมากๆ) กราฟมันจะแบนราบ (Saturate) พอกราฟแบน ความชัน (Gradient) ก็จะเข้าใกล้ศูนย์ เมื่อทำ Backpropagation ส่งค่า Error ย้อนกลับไปเรื่อยๆ ค่า Gradient จะถูกคูณด้วยศูนย์จนเลือนหายไป ทำให้เลเยอร์ต้นๆ “หยุดเรียนรู้ (Stop learning)” ไปเลยครับ!
- โรคซึมเศร้าของเซลล์ประสาท (The Dying ReLU Problem): ถึงพี่จะบอกว่า ReLU คือพระเอก แต่มันก็มีจุดอ่อนครับ ถ้าระหว่างเทรน ค่าน้ำหนัก (Weights) ถูกอัปเดตแรงเกินไปจนทำให้ค่าในวงเล็บติดลบอยู่ตลอดเวลา ReLU จะพ่นค่า 0 ออกมาเสมอ และพอมันพ่นค่า 0 Gradient ก็เป็น 0 ทำให้เซลล์ประสาทตัวนั้น “ตาย (Dead Neuron)” ไปอย่างถาวร ไม่ยอมตื่นมาเรียนรู้อะไรอีกเลย
- ทางแก้ (The Cure): ถ้าพบว่าโมเดลไม่ยอมเก่งขึ้น ให้ลองเปลี่ยนจาก ReLU ธรรมดา ไปใช้ญาติๆ ของมัน เช่น Leaky ReLU หรือ ELU ครับ ฟังก์ชันพวกนี้จะยอมให้กราฟในฝั่งลบมี “ความชันเล็กน้อย” (เช่น 0.01) ปล่อยให้มีน้ำไหลซึมผ่านได้บ้าง (Leak) เพื่อประคองไม่ให้ Gradient หายไปจนนิวรอนตายสนิทนั่นเองครับ
6. 🏁 บทสรุป (To be continued…)
โดยสรุปแล้ว Activation Functions คือกุญแจสำคัญที่ทำให้ “ปัญญาประดิษฐ์” แตกต่างจาก “สมการสถิติเชิงเส้น” ธรรมดาๆ มันคือตัวแปรที่ดัดโค้งจักรวาลตัวเลขให้สามารถห่อหุ้มความซับซ้อนของรูปภาพและเสียงในโลกแห่งความจริงได้
กฎทองคำที่พี่อยากให้จำไปใช้งานคือ: “ซ่อนลึกๆ ให้ใช้ ReLU, ชี้ขาดให้จบ ให้ใช้ Softmax (หรือ Sigmoid สำหรับ 2 คลาส)” ครับ!
ในตอนต่อไป หลังจากที่เรามีโครงสร้างสถาปัตยกรรม และมีฟังก์ชันกระตุ้นแล้ว เราจะมาดูกันว่า แล้วระบบรู้ได้อย่างไรว่ามัน “ทายผิด” พี่จะพาไปเจาะลึกถึง Loss Functions (ฟังก์ชันความสูญเสีย) และกระบวนการ Backpropagation ที่เปรียบเสมือน “แส้” คอยเฆี่ยนตีให้ AI ของเราเก่งขึ้นเรื่อยๆ รอติดตามนะครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p