ปฐมบทแห่งสมองกล: Perceptron จุดกำเนิดและวิวัฒนาการสู่สถาปัตยกรรมเครือข่ายประสาทเทียม

1. 🎯 ตอนที่ 4: ไขปริศนาเซลล์สมองเทียมก้อนแรก เมื่อ Perceptron ตื่นขึ้น
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกคน! จิบกาแฟให้ชุ่มคอแล้วมาล้อมวงกันตรงนี้เลยครับ วันนี้พี่จะพาขึ้นไทม์แมชชีนย้อนกลับไปในยุค 1950s เพื่อไขปริศนาที่สำคัญที่สุดในวงการ AI เราจะมาเจาะลึกถึง “บรรพบุรุษ” ของสมองกลวิทัศน์อย่าง Perceptron และดูว่าจากเซลล์ประสาทเทียมโง่ๆ เพียงเซลล์เดียว มันวิวัฒนาการ (Evolution) กลายร่างมาเป็น Network Architectures (โครงสร้างเครือข่ายประสาท) ที่ซับซ้อนและขับเคลื่อนโลกอุตสาหกรรมในปัจจุบันได้อย่างไร
2. 📖 เปิดฉาก (The Hook): กำเนิดนักสืบตาเดียว
ย้อนกลับไปในปี 1957 นักจิตวิทยาชื่อ Frank Rosenblatt ได้สร้างโมเดลทางคณิตศาสตร์ที่สั่นสะเทือนวงการ AI โมเดลนั้นมีชื่อว่า Perceptron ลองจินตนาการว่า Perceptron คือ “นักสืบฝึกหัดในโรงงาน” ที่มีหน้าที่ตรวจสอบชิ้นงาน (เช่น น็อต) ว่า “ผ่าน (Pass)” หรือ “ตก (Fail)” โดยดูจากข้อมูลพื้นฐานไม่กี่อย่าง
แนวคิดนี้ได้แรงบันดาลใจมาจากเซลล์ประสาทในสมองมนุษย์ (Biological Neurons) แบบตรงไปตรงมาครับ เซลล์ประสาทของมนุษย์จะมีส่วนรับสัญญาณ ถ้าประจุไฟฟ้ารวมกันแล้วแรงพอ ทะลุขีดจำกัด (Threshold) เซลล์นั้นก็จะ “ยิงสัญญาณ (Fire)” ออกไปยังเซลล์ถัดไป
วงการ AI ในยุคนั้นตื่นเต้นกับ Perceptron มาก เพราะมันสามารถเรียนรู้ได้ด้วยตัวเอง (Automatic training) แต่แล้วในปี 1969 หายนะก็บังเกิด เมื่อ Marvin Minsky และ Seymour Papert ตีพิมพ์หนังสือที่ชี้ให้เห็นข้อจำกัดที่ร้ายแรงที่สุดของ Perceptron ทำให้วงการ AI เข้าสู่ยุคตกต่ำที่เรียกว่า “AI Winter” ไปเกือบสิบปีเต็ม! เกิดอะไรขึ้นกับฮีโร่ของเรา? เรามาเจาะลึกโครงสร้างของมันกันครับ
3. 🧠 แก่นวิชา (Core Concepts): โครงสร้างและรอยร้าวในคัมภีร์
ในบริบทที่กว้างขึ้นของสถาปัตยกรรมเครือข่ายประสาท (Network Architectures) แหล่งข้อมูลได้อธิบายสถานะของ Perceptron และการวิวัฒนาการของมันไว้ดังนี้ครับ:
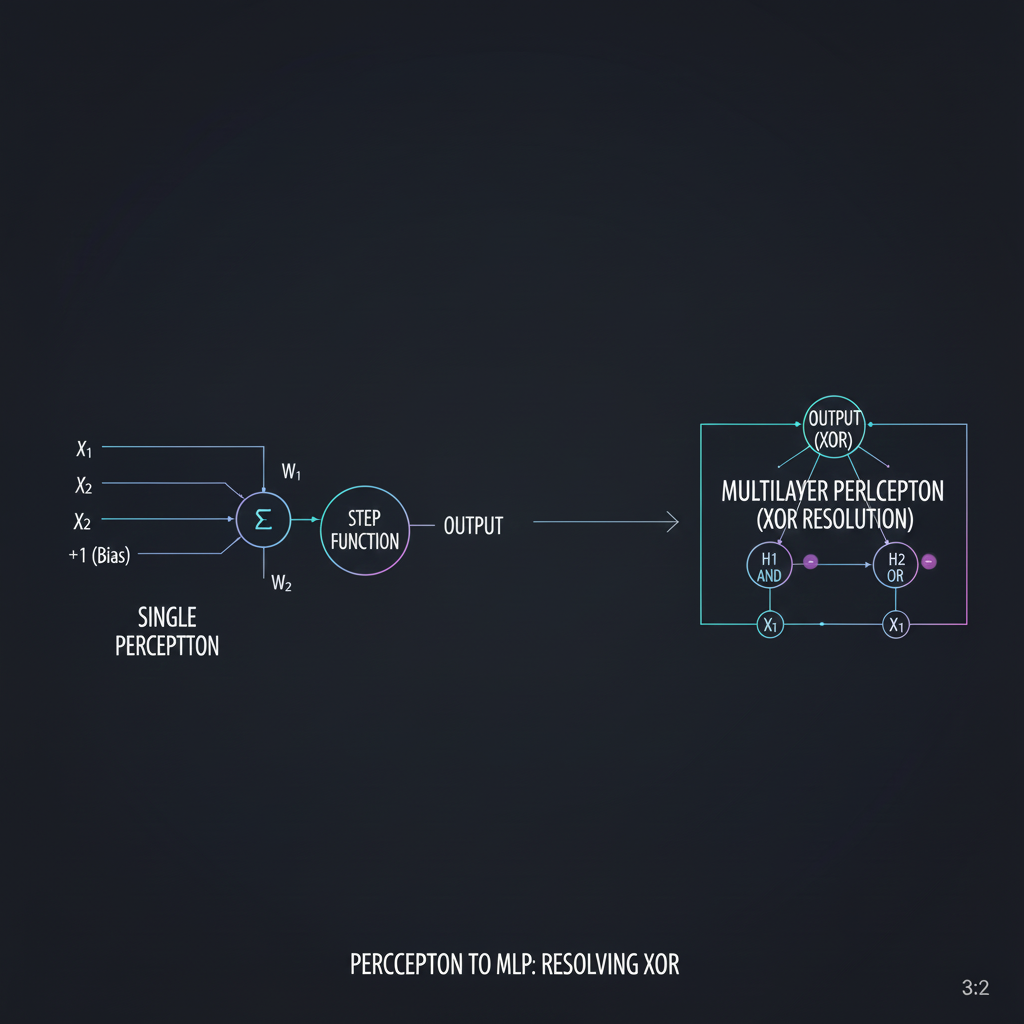
1. สถาปัตยกรรมของ Perceptron (The Anatomy): Rosenblatt ได้แปลงกระบวนการของสมองให้กลายเป็นคณิตศาสตร์ที่เรียกว่า Threshold Logic Unit (TLU) โครงสร้างของมันประกอบด้วย:
- Inputs ($x_i$): รับข้อมูลฟีเจอร์เข้ามา (เช่น ความกว้าง, ความยาว)
- Weights ($w_i$) & Bias ($b$): แต่ละ Input จะถูกคูณด้วยค่าน้ำหนักเพื่อบอกว่าข้อมูลนั้น “สำคัญ” แค่ไหน และมี Bias เป็นตัวปรับค่าความเอนเอียง (Threshold)
- Weighted Sum ($z$): นำผลคูณทั้งหมดมารวมกัน $z = w_1x_1 + w_2x_2 + … + w_nx_n + b$
- Activation Function (ฟังก์ชันตัดสินใจ): สำหรับ Perceptron จะใช้ฟังก์ชันแบบขั้นบันได หรือ Step Function (Sign function) คือถ้ายอดรวม $\ge 0$ จะฟันธงว่า “1 (ใช่)”, ถ้า $< 0$ จะฟันธงว่า “-1 หรือ 0 (ไม่ใช่)”
2. คำสาปของเส้นตรง (Linear Separability): จุดสลบที่ Minsky และ Papert โจมตีคือ Perceptron เป็นเพียง Linear Classifier (ตัวจำแนกเชิงเส้น) เปรียบเสมือนนักสืบที่ขีด “เส้นตรงได้แค่ 1 เส้น” บนกระดานเพื่อแบ่งแยกข้อมูล 2 กลุ่ม ถ้าเป็นตรรกะง่ายๆ อย่าง AND หรือ OR มันทำได้สบายมาก แต่ถ้าเจอปัญหาตรรกะแบบไขว้กันอย่าง XOR (Exclusive OR) มันไม่มีทางขีดเส้นตรงเส้นเดียวเพื่อแยกข้อมูลได้เลย!
3. การตื่นรู้สู่ Multilayer Perceptron (MLP): วิธีล้างคำสาปนี้คือ “ในเมื่อนักสืบคนเดียวขีดเส้นได้แค่เส้นเดียว ทำไมเราไม่จ้างนักสืบหลายคนมาขีดเส้นหลายๆ เส้นช่วยกันล่ะ?” นี่คือที่มาของการนำ Perceptron หลายๆ ตัวมาต่อกันเป็นชั้นๆ (Layers) เรียกว่า Multilayer Perceptron (MLP) หรือ Feedforward Neural Network โดยเพิ่ม Hidden Layers (ชั้นซ่อน) เข้าไปตรงกลาง ทำให้สถาปัตยกรรมนี้สามารถโอบล้อมและแยกแยะพื้นที่ข้อมูลที่ซับซ้อนแบบ Non-linear (เช่น หน้าตาของมนุษย์ หรือ รอยร้าวบนโลหะ) ได้อย่างแม่นยำ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้เห็นภาพว่าโครงสร้างการคำนวณของ Perceptron พื้นฐานทำงานอย่างไร ลองดู Python Code ที่เขียนด้วย NumPy ตามหลักการของ Rosenblatt แบบคลีนๆ ครับ (ดัดแปลงจากโครงสร้างของ Rosebrock):
import numpy as np
class SimplePerceptron:
def __init__(self, N, alpha=0.1):
# 📌 สร้างชุดค่าน้ำหนักเริ่มต้นแบบสุ่ม N คือจำนวน Input
# บวก 1 เข้าไปสำหรับค่า Bias (W_0)
self.W = np.random.randn(N + 1) / np.sqrt(N)
self.alpha = alpha # Learning rate
def step_function(self, x):
# 📌 ฟังก์ชันตัดสินใจ (Activation) แบบขั้นบันได (Step Function)
# ถ้ายอดรวม >= 0 ให้ตอบ 1 ถ้าไม่ใช่ตอบ 0
return 1 if x >= 0 else 0
def predict(self, x):
# 📌 นำเข้าฟีเจอร์ x และแทรกเลข 1.0 เข้าไปที่ตำแหน่งแรกสำหรับคูณกับ Bias
x_with_bias = np.insert(x, 0, 1.0)
# 📌 คำนวณ Weighted Sum ด้วยการทำ Dot Product
z = self.W.T.dot(x_with_bias)
# 📌 ส่งผลลัพธ์ผ่าน Step Function เพื่อตัดสินใจขั้นสุดท้าย
return self.step_function(z)
# -------------------------------------------------------------
# ลองนำไปทดสอบกับตรรกะ AND (มักทำได้ง่ายๆ เพราะใช้เส้นตรงเส้นเดียวตัดได้)
# -------------------------------------------------------------
X = np.array([,])
p = SimplePerceptron(N=2)
print("--- ผลลัพธ์แบบยังไม่ได้เทรน (เดามั่ว) ---")
for x in X:
print(f"Input: {x} -> Predict: {p.predict(x)}")5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในยุคที่เราทำระบบ Machine Vision น้องๆ อาจจะสงสัยว่า “แล้วทุกวันนี้เรายังใช้ Step Function แบบยุคของ Perceptron อยู่ไหมในเครือข่าย MLP ที่ซับซ้อน?” คำตอบคือ ไม่ใช้แล้วครับ! พี่ขอเตือนข้อควรระวังสำคัญไว้ดังนี้:
- อุปสรรคของการฝึกสอน (The Backpropagation Issue): เมื่อเราขยายสถาปัตยกรรมเป็น MLP เราต้องฝึกสอนเครือข่ายด้วยอัลกอริทึมที่ชื่อว่า Backpropagation ซึ่งทำงานร่วมกับ Gradient Descent ปัญหาคือ Gradient Descent ต้องใช้ “การหาอนุพันธ์ (Derivative/Calculus)” ในการคำนวณความผิดพลาด แต่ฟังก์ชันขั้นบันได (Step Function) ของ Perceptron รุ่นปู่ “หาอนุพันธ์ไม่ได้ (Non-differentiable)” ในจุดที่หักมุม และความชันเป็นศูนย์หมดในจุดอื่นๆ
- ทางออกของยุคใหม่ (Modern Activations): ด้วยเหตุนี้ ในโครงสร้างเครือข่ายยุคใหม่ (Deep Learning) เราจึงทิ้ง Step Function และเปลี่ยนมาใช้ Activation Function ที่โค้งมนหรือมีความชันต่อเนื่อง เช่น Sigmoid, Tanh หรือฮีโร่ของงานภาพอย่าง ReLU (Rectified Linear Unit) แทนครับ เพื่อให้โมเดลสามารถส่งผ่านค่า Error ย้อนกลับไปอัปเดตน้ำหนักได้สำเร็จ!
6. 🏁 บทสรุป (To be continued…)
สรุปได้ว่า Perceptron ไม่ใช่แค่สมการทางคณิตศาสตร์เก่าเก็บ แต่มันคือ “รากฐาน (Building Block)” ที่สำคัญที่สุด แนวคิดเรื่อง “Inputs $\times$ Weights + Bias $\rightarrow$ Activation” ของมัน ถูกนำมาต่อยอดและจัดเรียงองค์กรใหม่จนกลายเป็น Multilayer Perceptron (MLP) หรือโครงสร้างระดับ Deep Neural Networks ในปัจจุบัน
เมื่อไหร่ก็ตามที่เราเห็น AI แยกของเสียในโรงงานได้ หรืออ่านป้ายทะเบียนรถได้อย่างแม่นยำ ขอให้จำไว้เสมอครับว่า ทั้งหมดนี้เกิดจากเหล่านักสืบ Perceptron นับล้านตัวที่ร่วมมือกันทำหน้าที่นั่นเอง! ในตอนหน้า เราจะมาดูกันว่า แล้วฝั่งสถาปัตยกรรมตัวท็อปสำหรับงานภาพอย่าง CNN (Convolutional Neural Network) นั้นแตกต่างจาก MLP อย่างไร รอติดตามครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p