ปูพื้นฐาน Deep Learning: ท่าไม้ตายที่พลิกโฉมวงการ Computer Vision

1. 🎯 ตอนที่ 2: เจาะลึกรากฐาน Deep Learning เมื่อ AI เรียนรู้ที่จะมองเห็นด้วยตัวเอง
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกคน! มานั่งจิบกาแฟพักเบรกกันสักหน่อย วันนี้พี่จะพาถอยหลังกลับมามองภาพใหญ่ (Big Picture) กันบ้าง หลังจากที่เราลุยเรื่องโครงสร้างโมเดลกันมาพอสมควร เราจะมาเจาะแก่นแท้ของ “พื้นฐาน Deep Learning (DL)” ว่าในบริบทของโลก Computer Vision (CV) นั้น DL เข้ามามีบทบาทอย่างไร ทำไมมันถึงเตะโด่งเทคโนโลยีเก่าๆ ตกขอบกระดาน และกลายมาเป็นมาตรฐานใหม่ในโรงงานอุตสาหกรรมทั่วโลกครับ!
2. 📖 เปิดฉาก (The Hook)
ย้อนกลับไปยุคก่อนที่ Deep Learning จะบูม (ช่วงก่อนปี 2012) เวลาพี่จะทำโปรเจกต์ให้กล้องแยกแยะน็อตตัวผู้กับตัวเมีย พี่และทีมวิศวกรต้องมานั่งทำสิ่งที่เรียกว่า “Handcrafted Features” (การสกัดคุณลักษณะด้วยมือ) ครับ เราต้องเขียนอัลกอริทึมคณิตศาสตร์ยาวเหยียด (เช่น SIFT, HOG, หรือ SURF) เพื่อบอกคอมพิวเตอร์ว่า “ตรงนี้คือเส้นขอบนะ ตรงนี้คือมุมนะ” จากนั้นค่อยเอาข้อมูลตัวเลขเหล่านี้ไปเข้าโมเดล Machine Learning แบบดั้งเดิม (เช่น SVM) เพื่อตัดสินใจ
ปัญหาคืออะไรรู้ไหมครับ? พอเอาไปติดหน้างานจริง เจอแสงสะท้อนของแดดตอนบ่าย หรือชิ้นงานวางเอียงนิดเดียว… อัลกอริทึมพังพินาศครับ! เราไม่สามารถเขียนโปรแกรมดักจับทุกสถานการณ์บนโลกได้
จนกระทั่งเวทมนตร์ที่ชื่อว่า Deep Learning ถือกำเนิดขึ้น มันเปลี่ยนกฎของเกมไปตลอดกาล แทนที่เราจะบอกคอมพิวเตอร์ว่าต้องมองหาอะไร เราแค่ “โยนภาพดิบๆ (Raw Pixels)” เข้าไป แล้วบอกผลลัพธ์ว่านี่คืออะไร ที่เหลือ… โครงข่ายประสาทเทียมมันจะไปหาวิธีสกัดจุดเด่นและเรียนรู้ด้วยตัวเองแบบม้วนเดียวจบ (End-to-End Learning) ครับ!
3. 🧠 แก่นวิชา (Core Concepts)
ในบริบทของ Computer Vision แหล่งข้อมูลระดับโลกได้นิยามและอธิบายความสามารถพื้นฐานของ Deep Learning ไว้ดังนี้ครับ:
- 1. แบบจำลองเซลล์ประสาท (Biological Inspiration): พื้นฐานที่สุดของ DL คือ Artificial Neural Networks (ANN) ที่ได้แรงบันดาลใจมาจากสมองมนุษย์ ประกอบด้วยเซลล์ประสาทเทียมเล็กๆ (Neurons) ที่รับสัญญาณภาพเข้ามา ทำการคูณด้วย “ค่าน้ำหนัก (Weights)” และบวก “ค่าไบแอส (Biases)” ก่อนจะส่งผ่าน “ฟังก์ชันกระตุ้น (Activation Function)” เพื่อตัดสินใจว่าจะส่งสัญญาณต่อไปหรือไม่
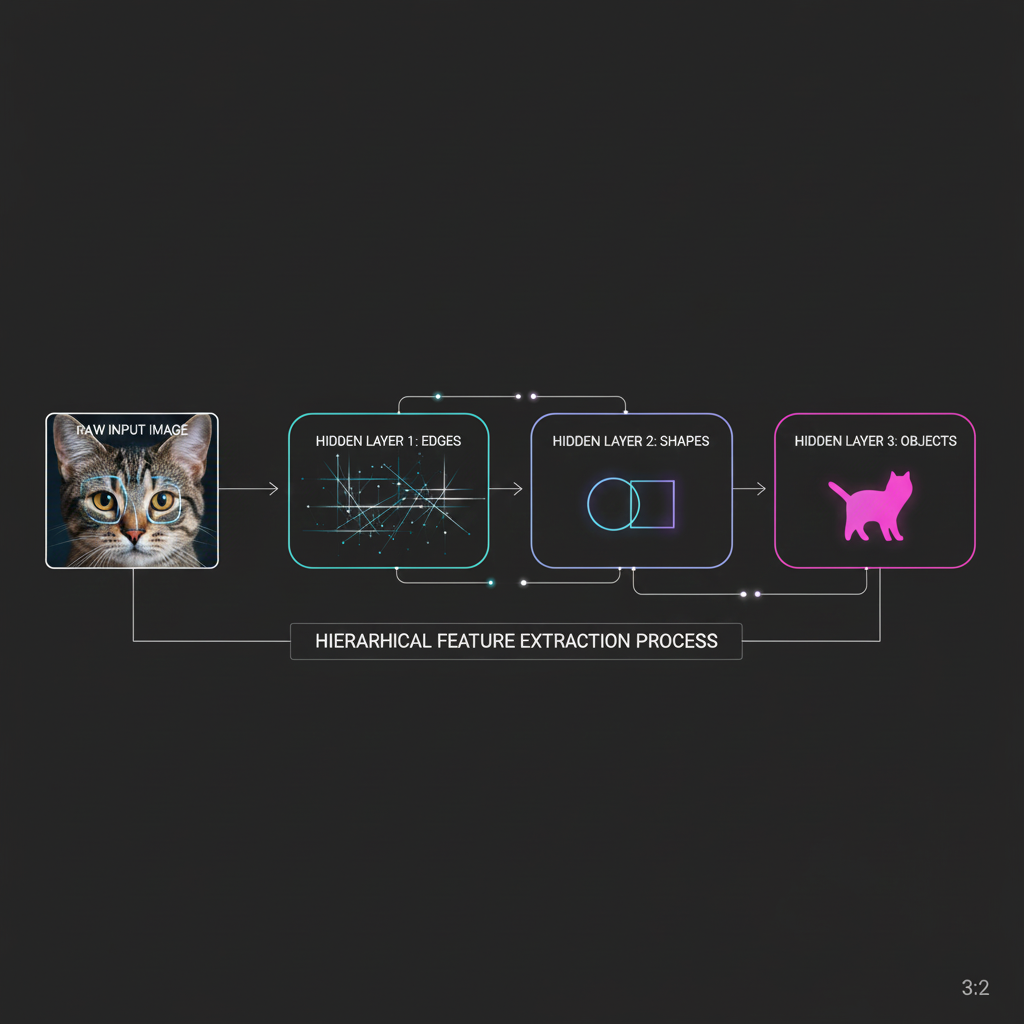
- 2. การเรียนรู้แบบลำดับขั้น (Hierarchical Feature Learning):
นี่คือความเจ๋งที่สุดของคำว่า “Deep” ครับ! โครงข่ายประสาทเทียมที่มีความลึก (หลาย Hidden Layers) จะเรียนรู้การมองเห็นเหมือนมนุษย์เป๊ะๆ โดยแบ่งงานกันทำเป็นลำดับขั้น:
- เลเยอร์แรกๆ (Low-level features): ทำหน้าที่มองหาแค่ เส้นตรง, เส้นโค้ง, ขอบ (Edges) หรือจุดสี
- เลเยอร์กลางๆ (Mid-level features): เอาเส้นขอบพวกนั้นมาประกอบร่างเป็น รูปทรงเรขาคณิต (Shapes) หรือชิ้นส่วนย่อยๆ เช่น น็อต, มุมกล่อง
- เลเยอร์ลึกๆ (High-level features): นำชิ้นส่วนทั้งหมดมารวมกันเป็นวัตถุที่มีความหมายซับซ้อน เช่น ใบหน้าคน, รถยนต์ หรือ รอยร้าวบนชิ้นงาน
- 3. การปรับปรุงตัวเอง (Backpropagation & Gradient Descent): กระบวนการเรียนรู้เกิดขึ้นผ่านอัลกอริทึม Backpropagation (การแพร่กลับ) เมื่อโมเดลทายภาพผิด มันจะคำนวณค่าความผิดพลาด (Loss) และส่งสัญญาณย้อนกลับไปปรับค่าน้ำหนัก (Weights) ทั่วทั้งเครือข่ายทีละนิด ผ่านกระบวนการที่เรียกว่า Gradient Descent จนกว่ามันจะแยกแยะภาพได้อย่างแม่นยำ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้เห็นภาพว่า การสร้างโครงสร้าง “การเรียนรู้แบบลำดับขั้น” หน้าตาเป็นอย่างไรในโค้ด ลองดูการสร้าง Deep Neural Network พื้นฐาน (สำหรับงานภาพที่ถูกแปลงเป็นเวกเตอร์แล้ว) ด้วย Keras กันครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
# สร้างสถาปัตยกรรมแบบตามลำดับ (Sequential)
model = models.Sequential([
# Input Layer: รับภาพขนาด 28x28 พิกเซล เข้ามาและยืดเป็นเส้นตรง (Flatten)
layers.Flatten(input_shape=(28, 28), name="Input_Layer"),
# Hidden Layer 1: ชั้นนี้อาจจะเรียนรู้ Low-level features (เช่น เส้นขอบ)
# ใช้ ReLU activation เพื่อป้องกันปัญหา Gradient หาย และคำนวณไว
layers.Dense(256, activation='relu', name="Low_Level_Features"),
# Hidden Layer 2: ชั้นนี้รับข้อมูลมาประกอบร่างเป็น Mid/High-level features
layers.Dense(128, activation='relu', name="High_Level_Features"),
# ชั้น Output: สมมติว่าแยกแยะของเสีย 10 หมวดหมู่
# ใช้ Softmax เพื่อแปลงผลลัพธ์เป็นค่าความน่าจะเป็น (Probability) 0-100%
layers.Dense(10, activation='softmax', name="Output_Layer")
])
# คอมไพล์โมเดล พร้อมระบุ Loss Function และ Optimizer (Gradient Descent)
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# ตรวจสอบโครงสร้าง
model.summary()5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในมุมมองของนักปฏิบัติ (Practitioner) พื้นฐานที่เราพูดถึงด้านบนยังมี “หลุมพราง” ซ่อนอยู่เมื่อนำมาใช้กับงานภาพ (Computer Vision) จริงๆ ครับ:
- คำสาปของการ Flatten (Spatial Loss): การใช้เครือข่ายประสาทแบบดั้งเดิม (MLP / Dense Layers ล้วนๆ) กับรูปภาพ เราบังคับให้มันต้องบีบภาพ 2 มิติให้กลายเป็นเส้นตรง 1 มิติ (Flatten) ผลคือคอมพิวเตอร์จะ “สูญเสียความเข้าใจเรื่องมิติพื้นที่” ไปเลย มันจะไม่รู้ว่าพิกเซลซ้ายกับขวาเคยอยู่ติดกัน
- พารามิเตอร์ระเบิด (Parameter Explosion): ถ้าน้องใช้ภาพขนาดใหญ่ระดับอุตสาหกรรม (เช่น 1000x1000 พิกเซล) เข้าโมเดล Dense Layer จำนวนจุดเชื่อมต่อ (Weights) จะทะลุหลักหลายร้อยล้านตัว ทำให้เครื่องพังและเกิดอาการท่องจำ (Overfitting) อย่างหนัก
- ทางออก (The Solution): นี่คือเหตุผลว่าทำไมในยุคนี้ เมื่อพูดถึง Deep Learning สำหรับ Computer Vision เราจึงไม่ใช้โมเดล MLP ธรรมดา แต่เราอัปเกรดไปใช้ Convolutional Neural Networks (CNNs) แทน! CNN มีกลไกการใช้ “ฟิลเตอร์” กวาดไปบนภาพ 2 มิติ ทำให้รักษาโครงสร้างเชิงพื้นที่ไว้ได้ และลดจำนวนพารามิเตอร์ลงได้อย่างมหาศาลครับ
6. 🏁 บทสรุป (To be continued…)
สรุปง่ายๆ เลยครับ Deep Learning เข้ามาปฏิวัติงาน Computer Vision ด้วยการเปลี่ยนปรัชญาจาก “การพยายามอธิบายภาพด้วยสมการคณิตศาสตร์ (Handcrafted)” มาเป็นการ “ให้เครือข่ายประสาทค่อยๆ เรียนรู้จุดเด่นของภาพแบบเป็นลำดับขั้น (Hierarchical Learning)”
และถึงแม้กลไกพื้นฐานของ Deep Learning อย่างการใช้ Dense Layers หรือ Backpropagation จะทรงพลังแค่ไหน แต่มันก็ยังต้องการสถาปัตยกรรมที่ “เกิดมาเพื่องานภาพโดยเฉพาะ” ในตอนต่อไป เราจะมาเจาะลึกพระเอกตัวจริงที่ชื่อว่า CNN (Convolutional Neural Network) กันแบบหมดเปลือก เตรียมตัวไว้ได้เลยครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p