เจาะลึก Deep Learning สำหรับ Computer Vision: เมื่อดวงตาจักรกลเรียนรู้ที่จะมองเห็น

1. 🎯 ตอนที่ 1: เจาะลึก Deep Learning สำหรับ Computer Vision
สวัสดีครับน้องๆ วิศวกรและนักพัฒนาทุกท่าน! กลับมาล้อมวงจิบกาแฟกันต่อครับ ในบทความก่อนหน้านี้เราได้ปูพื้นฐานเรื่องโครงข่ายประสาทเทียม (Neural Networks) กันไปแล้ว วันนี้พี่จะพามาดูว่า เมื่อเรานำ Deep Learning มาประยุกต์ใช้กับงาน Computer Vision (CV) หรือการทำให้คอมพิวเตอร์มองเห็น มันสร้างความสั่นสะเทือนและพลิกโฉมวงการอุตสาหกรรมไปอย่างไรบ้าง เตรียมตัวให้พร้อมครับ เรากำลังจะเจาะลึกเข้าไปใน “สมองส่วนการมองเห็น” ของ AI กัน!
2. 📖 เปิดฉาก (The Hook)
ลองจินตนาการย้อนกลับไปในยุคดั้งเดิม (Traditional Computer Vision) เวลาวิศวกรอย่างเราต้องเขียนโปรแกรมตรวจจับรอยร้าวบนชิ้นงาน หรือแยกสุนัขออกจากแมว เราต้องมานั่งทำงานที่เรียกว่า Hand-crafted Feature Extraction (การสกัดคุณลักษณะด้วยมือ) เราต้องเขียนกฎคณิตศาสตร์ยาวเหยียดเพื่อบอกคอมพิวเตอร์ว่า “ขอบ” (Edges) อยู่ตรงไหน “มุม” (Corners) หน้าตาเป็นอย่างไร ปัญหาคือ พอนำไปใช้หน้างานจริง แสงเปลี่ยนนิดเดียว มุมกล้องเอียงหน่อยเดียว กฎที่เราเขียนไว้ก็พังไม่เป็นท่าครับ
แต่แล้ว Deep Learning ก็ก้าวเข้ามาเป็นพระเอกขี่ม้าขาว! มันบอกเราว่า “หยุดเขียนกฎคณิตศาสตร์พวกนั้นซะ! แค่โยนรูปภาพดิบๆ (Raw pixels) มาให้ฉัน แล้วฉันจะเรียนรู้เองว่าอะไรคือจุดเด่นของภาพนี้” การเปลี่ยนผ่านจากยุค Hand-crafted สู่ยุค End-to-End Learning นี่แหละครับ คือจุดเริ่มต้นของเวทมนตร์ที่ทำให้ AI ปัจจุบันสามารถตรวจจับมะเร็งปอดจากภาพ X-ray หรืออ่านป้ายจราจรในรถยนต์ไร้คนขับได้อย่างแม่นยำ
3. 🧠 แก่นวิชา (Core Concepts)
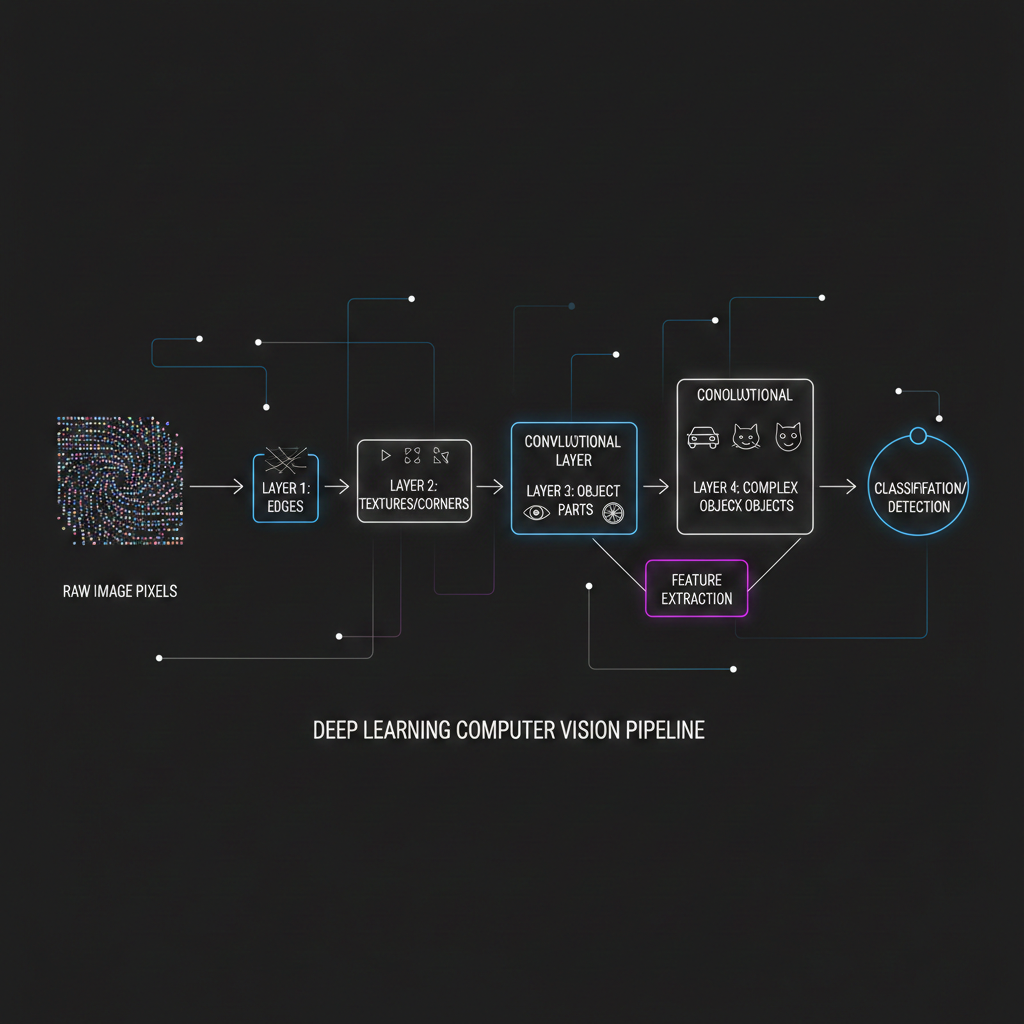
ในบริบทของ Computer Vision แหล่งข้อมูลได้อธิบายการทำงานของ Deep Learning ไว้ผ่าน 2 คอนเซปต์หลักที่ทรงพลังมากๆ ดังนี้ครับ:
1. Hierarchical Feature Learning (การเรียนรู้แบบลำดับขั้น): Deep Learning จะไม่กระโดดจากพิกเซลไปเดาว่าเป็นรูปอะไรในขั้นตอนเดียว แต่มันจะเรียนรู้เป็นลำดับขั้น (Hierarchy) เหมือนสมองมนุษย์
- เลเยอร์แรกๆ (Low-level features): จะเรียนรู้แค่การมองหาเส้นตรง เส้นโค้ง หรือขอบ (Edges)
- เลเยอร์กลางๆ (Mid-level features): นำเส้นเหล่านั้นมาประกอบร่างเป็นรูปทรงเรขาคณิต เช่น วงกลม หรือมุม
- เลเยอร์ลึกๆ (High-level features): นำรูปทรงมาประกอบกันเป็นวัตถุที่ซับซ้อน เช่น ล้อรถ, ตาของสุนัข หรือรอยเชื่อมบนโลหะ
2. พระเอกตัวจริง: Convolutional Neural Networks (CNNs): ถ้าเราใช้ Neural Network แบบดั้งเดิม (MLP) กับรูปภาพ เราจะต้องยืดภาพ 2 มิติให้กลายเป็นเส้นตรง 1 มิติ (Flatten) ซึ่งทำให้คอมพิวเตอร์สูญเสียข้อมูลความสัมพันธ์ของพิกเซลที่อยู่ติดกัน (Spatial information) และยังต้องใช้ Parameter มหาศาล
วงการ CV จึงหันมาใช้ CNNs แทน! CNN ทำงานผ่าน Convolutional Layers ซึ่งจะใช้ “แว่นขยาย” หรือหน้าต่างเล็กๆ (Sliding windows / Kernels) กวาดไปทั่วภาพเพื่อสกัด Feature Maps กลไกนี้เรียกว่า Local Connectivity คือนิวรอนจะสนใจแค่พิกเซลกลุ่มเล็กๆ ที่อยู่ติดกันเท่านั้น ทำให้รักษาโครงสร้าง 2 มิติของภาพไว้ได้ และยังช่วยลดภาระการคำนวณลงไปได้อย่างมหาศาลครับ
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
เพื่อให้เห็นภาพว่าโครงสร้างของ Deep Learning สำหรับ Computer Vision หน้าตาเป็นอย่างไร ลองดูตัวอย่างการสร้าง CNN ง่ายๆ สำหรับงาน Image Classification ด้วย Keras/TensorFlow ครับ:
import tensorflow as tf
from tensorflow.keras import layers, models
# สร้างสถาปัตยกรรม CNN แบบตามลำดับ (Sequential)
model = models.Sequential()
# -------------------------------------------------------------
# ส่วนที่ 1: Feature Extraction (หน่วยสกัดคุณลักษณะด้วย Convolution)
# -------------------------------------------------------------
# Conv เลเยอร์แรก: สกัด Low-level features ด้วย Filter ขนาด 3x3
# (ไม่สูญเสียมิติ 2D ของรูปภาพ)
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
# ยุบขนาดภาพด้วย Max Pooling เพื่อลดพารามิเตอร์และทำให้โมเดลทนทานต่อการขยับของวัตถุ
model.add(layers.MaxPooling2D((2, 2)))
# Conv เลเยอร์ที่สองและสาม: สกัด Mid/High-level features ที่ซับซ้อนขึ้น
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# -------------------------------------------------------------
# ส่วนที่ 2: Classification (หน่วยตัดสินใจฟันธง)
# -------------------------------------------------------------
# ยืดข้อมูล Feature Maps ที่เข้มข้นแล้วให้เป็น 1 มิติ (Flatten)
model.add(layers.Flatten())
# ชั้น Fully Connected สำหรับตัดสินใจ
model.add(layers.Dense(64, activation='relu'))
# Output Layer (สมมติว่าแยกแยะ 10 คลาส)
model.add(layers.Dense(10, activation='softmax'))
model.summary()5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในโลกแห่งความเป็นจริง (โดยเฉพาะในโรงงานอุตสาหกรรม) เราไม่ได้มีภาพของเสียเป็นล้านๆ ภาพให้ AI เรียนรู้เสมอไปครับ พี่จึงขอเตือนน้องๆ ว่าอย่าเริ่มเทรนโมเดลจากศูนย์ (Training from scratch) เด็ดขาดหากข้อมูลน้อย! เรามีอาวุธลับ 2 อย่างครับ:
- วิชาลอกการบ้าน (Transfer Learning): แทนที่จะสอนโมเดลใหม่ ให้เราโหลดโมเดลที่ผ่านการเทรนมาอย่างโชกโชน (Pre-trained models) เช่น VGG16, ResNet หรือ Inception ที่เคยเห็นภาพมาแล้วนับล้านรูปจาก ImageNet จากนั้นเราจะ “แช่แข็ง (Freeze)” เลเยอร์สกัดคุณลักษณะ (Feature Extractor) เอาไว้ แล้วนำมาสอนเพิ่ม (Fine-tuning) เฉพาะ “ชั้นตัดสินใจ” ให้รู้จักแค่ชิ้นงานของเรา วิธีนี้จะทำให้โมเดลเก่งเร็วมากแม้มีภาพสอนแค่ไม่กี่ร้อยภาพครับ!
- วิชาแยกร่าง (Data Augmentation): ถ้ารูปมีน้อย ก็สร้างเพิ่มสิ! เราสามารถหลอก AI ให้คิดว่ามีข้อมูลเยอะขึ้นได้ ด้วยการนำภาพเดิมมา หมุน (Rotate), ย่อขยาย (Zoom), พลิกซ้ายขวา (Flip) หรือปรับความสว่าง วิธีนี้เป็นยาวิเศษในการป้องกัน Overfitting (การที่ AI จำแต่ข้อสอบเก่า) ทำให้โมเดลทนทานต่อสภาพแวดล้อมจริงได้ดีเยี่ยมครับ
6. 🏁 บทสรุป (To be continued…)
สรุปแล้ว Deep Learning สำหรับ Computer Vision คือการใช้ขุมพลังของ CNN ในการสกัดคุณลักษณะของภาพแบบเป็นลำดับขั้น (Hierarchical) จากจุดและเส้นเล็กๆ ไปสู่วัตถุที่ซับซ้อน โดยไม่จำเป็นต้องใช้มนุษย์มานั่งเขียนกฎอีกต่อไป ยิ่งผสานกับเทคนิคอย่าง Transfer Learning และ Data Augmentation ก็ยิ่งทำให้วิศวกรสามารถสร้าง AI สายตาระดับเทพเพื่อใช้งานในโรงงานอุตสาหกรรมได้อย่างรวดเร็ว
ในตอนหน้า เราจะขยับจากโจทย์ “ภาพนี้คืออะไร (Image Classification)” ไปสู่โจทย์ที่หินขึ้นอย่าง “วัตถุอยู่ตรงไหนของภาพ (Object Detection)” ซึ่งเป็นหัวใจสำคัญของการทำระบบ Inspection หน้างานจริงอย่าง YOLO หรือ SSD รอติดตามกันได้เลยครับ!
ต้องการที่ปรึกษาและพัฒนาระบบ Automation & Machine Vision ให้กับโรงงานของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและติดตั้งระบบแบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p