Data Parallelism: ระเบิดพลัง CPU Multi-core ด้วย Parallel.For และ Parallel.ForEach

1. 🎯 ตอนที่ 11: Data Parallelism: การใช้ Parallel.For และ Parallel.ForEach
2. 📖 เปิดฉาก (The Hook)
สวัสดีครับผู้อ่านทุกท่าน! กลับมาพบกันอีกครั้งในซีรีส์ เจาะลึก C# Concurrency & Multithreading
ลองจินตนาการถึงยุคอดีตที่เรามีข้อมูลลูกค้าต้องประมวลผล 1 ล้านเรกคอร์ด เราเขียนคำสั่ง for หรือ foreach loop ธรรมดา โค้ดของเราก็จะวิ่งวนไปทีละรอบ (Sequential) อย่างขยันขันแข็งบน CPU Core ที่ 1 ในขณะที่ Core ที่ 2 ถึง 8 ในเครื่องเซิร์ฟเวอร์ราคาแพงของคุณกลับนั่งว่างงานจิบกาแฟสบายใจเฉิบ… นี่คือการสูญเสียทรัพยากรอย่างเปล่าประโยชน์ที่สุดครับ!
เพื่อแก้ปัญหานี้ หนังสือ Parallel Programming with Microsoft .NET ได้เจาะลึกถึงรูปแบบที่เรียกว่า Data Parallelism ซึ่งเป็นศิลปะในการนำข้อมูลก้อนใหญ่มาหั่นแบ่ง แล้วโยนให้ CPU ทุก Core ช่วยกันรุมประมวลผลพร้อมๆ กัน และใน .NET Framework เครื่องมือที่เป็นพระเอกสำหรับงานนี้ก็คือคำสั่ง Parallel.For และ Parallel.ForEach จาก Task Parallel Library (TPL) นั่นเอง วันนี้ผมจะพาไปดูวิธีเปลี่ยนลูปเต่าคลานให้เป็นซูเปอร์คาร์ พร้อมกับชี้จุดตายที่มือใหม่มักจะพลาดเมื่อนำลูปแบบขนานไปใช้งานครับ!
3. 🧠 แก่นวิชา (Core Concepts)
คอนเซปต์ของ Data Parallelism ภายใต้ TPL นั้นออกแบบมาให้ใช้งานง่าย แต่มีกลไกเบื้องหลังที่ทรงพลังมากครับ:
- Data Parallelism คืออะไร? มันคือการนำ “ปฏิบัติการเดียวกัน (Same operation)” ไปกระทำกับ “ข้อมูลแต่ละชิ้น (Multiple data elements)” อย่างเป็นอิสระต่อกัน ถ้าเปรียบเทียบคือ แทนที่จะให้พนักงาน 1 คนล้างจาน 1,000 ใบ เราแบ่งจานเป็นกองๆ แล้วเรียกพนักงาน 8 คนมาช่วยกันล้างพร้อมกัน
- การทำงานของ
Parallel.ForและParallel.ForEachเมื่อคุณเรียกใช้คำสั่งเหล่านี้ TPL จะไม่รันงานแบบเรียงลำดับอีกต่อไป แต่มันจะใช้เทคนิค Adaptive Partitioning เพื่อแบ่งช่วงของข้อมูล (Index range หรือ Collection) ออกเป็นก้อนๆ (Chunks) แล้วส่งงานเหล่านั้นไปสร้างเป็น Task เพื่อรันบน ThreadPool แบบอัตโนมัติ โดยระบบจะคำนวณให้เองว่าเครื่องที่รันมีกี่ Core และควรใช้กี่ Thread ถึงจะคุ้มค่าที่สุด - กฎเหล็ก: “ไร้ระเบียบ และ ไม่รับประกันลำดับ” สิ่งสำคัญที่คุณต้องจำไว้ให้ขึ้นใจคือ เมื่อเข้าสู่โลกของ Parallel ลำดับการทำงาน (Order of execution) จะถูกทำลายทิ้งทันที! ลูปอาจจะประมวลผล Index ที่ 999 ก่อน Index ที่ 1 ก็ได้ คุณไม่สามารถคาดเดาหรือบังคับลำดับของมันได้เลย
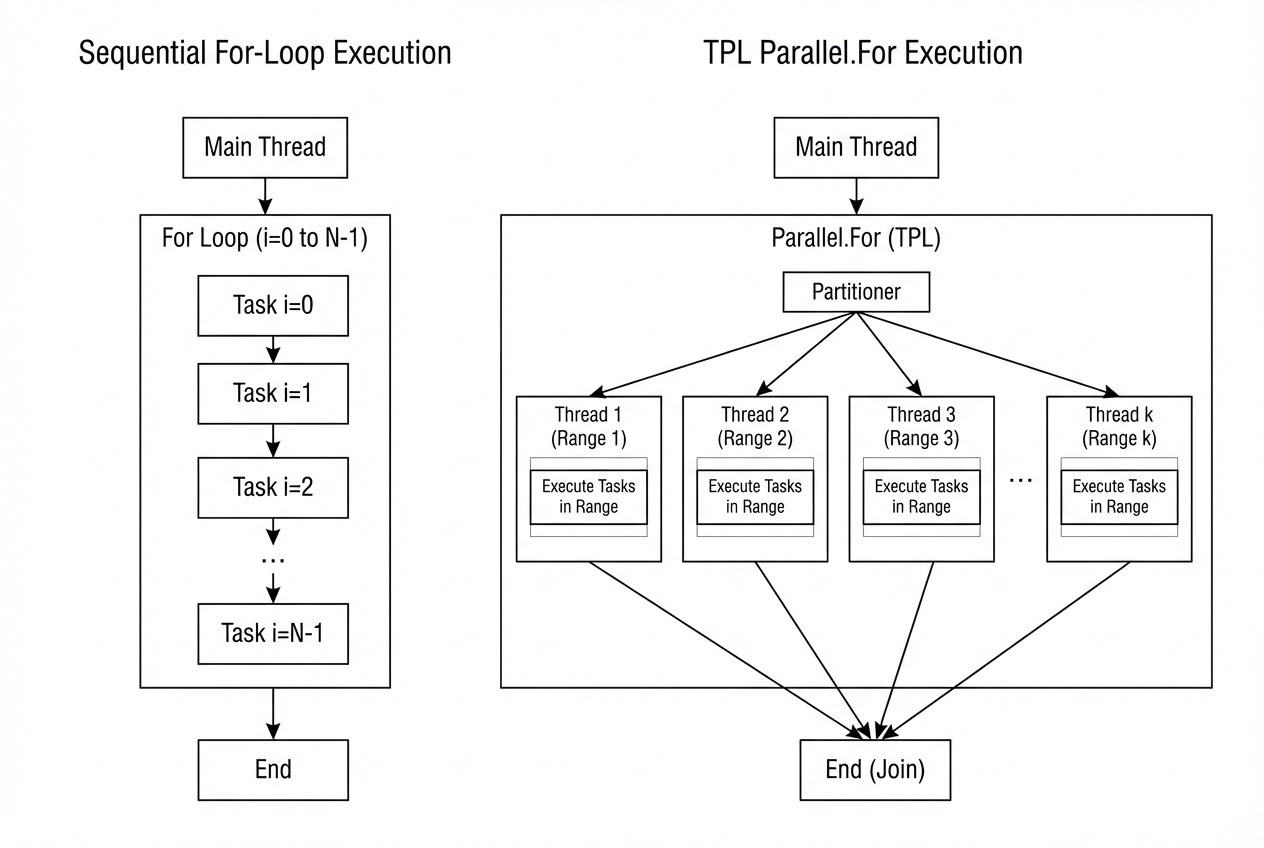
4. 💻 ร่ายมนต์โค้ด (Show me the Code)
ลองมาดูการแปลงร่างลูปแบบดั้งเดิม ให้กลายเป็นลูปประมวลผลแบบขนานกันครับ
แบบที่ 1: การใช้ Parallel.For (เหมาะกับการอ้างอิงด้วย Index)
using System;
using System.Threading.Tasks;
public class ParallelLoopsDemo
{
public static void ProcessArrayParallel()
{
int[] data = new int;
// จำลองการเตรียมข้อมูล...
// แบบเก่า (Sequential): ทำทีละรอบ
// for (int i = 0; i < data.Length; i++) { data[i] = DoHeavyMath(data[i]); }
// แบบใหม่ (Parallel): ให้ TPL จัดการดึงทุก Core มารุมทำ
Console.WriteLine("Starting Parallel.For...");
Parallel.For(0, data.Length, i =>
{
// โค้ดตรงนี้จะถูกแบ่งไปรันบนหลายๆ Thread พร้อมกัน
data[i] = DoHeavyMath(data[i]);
});
Console.WriteLine("Done!");
}
static int DoHeavyMath(int input) { /* จำลองการคำนวณหนักๆ */ return input * 2; }
}แบบที่ 2: การใช้ Parallel.ForEach (เหมาะกับ Collection เช่น List, IEnumerable)
public static void ProcessImagesParallel(List<Image> images)
{
// สมมติว่าเรามีรูปภาพที่ต้องใส่ Filter 1,000 รูป
Parallel.ForEach(images, img =>
{
// แต่ละรูปจะถูกส่งไปให้ CPU ช่วยกันประมวลผลอย่างอิสระ
ApplyFilter(img);
SaveImage(img);
// เราสามารถเช็คได้ว่ารูปนี้ถูกรันบน Thread ไหน
// Console.WriteLine($"Processed on Thread ID: {Thread.CurrentThread.ManagedThreadId}");
});
}5. 🛡️ เคล็ดลับจากคัมภีร์ลับ (Under the Hood / Pro-Tips)
ในฐานะสถาปนิกซอฟต์แวร์ นี่คือ “จุดตาย” ที่ผมมักจะเจอรุ่นน้องพลาดเวลาใช้งาน Parallel Loops ซึ่งอ้างอิงจากคัมภีร์ Parallel Programming with Microsoft .NET โดยตรงครับ:
- กฎแห่งความเป็นอิสระ (Rule of Independence): ขั้นตอนการทำงานในลูป (Loop body) ต้องเป็นอิสระต่อกัน 100% ห้ามมีการเขียนข้อมูลลงในตำแหน่งหน่วยความจำที่ Thread อื่นกำลังอ่านหรือเขียนอยู่เด็ดขาด!
- หายนะจากการใช้ตัวแปรร่วม (Shared State & Race Conditions):
หากคุณประกาศตัวแปรไว้นอกลูป แล้วเข้าไปอัปเดตค่ามันในลูป (เช่น
sum += data[i];) สิ่งที่เกิดขึ้นคือหลาย Thread จะแย่งกันเขียนค่าลงตัวแปรเดียวกัน (Race condition) ทำให้ผลลัพธ์ผิดเพี้ยนไปหมด! หากต้องการหาผลรวม คุณต้องใช้เทคนิค Thread-Local State หรือเปลี่ยนไปใช้ท่า Parallel Aggregation แทน - ห้ามพึ่งพาผลลัพธ์รอบก่อนหน้า (Loop-Carried Dependence):
อย่าเขียนโค้ดแบบนี้:
data[i] = data[i] + data[i - 1];เด็ดขาด! เพราะในโลกของ Parallel ระบบอาจจะรันรอบที่iก่อนรอบที่i - 1ก็ได้ ทำให้ค่าที่ได้ออกมาเละเทะไม่เป็นท่า - อย่าใช้กับงานที่เล็กเกินไป (Overhead with Small Loop Bodies):
การจัดการคิว การแบ่งข้อมูล และการสลับ Thread (Context Switch) มีราคา (Overhead) ที่ต้องจ่าย หากโค้ดในลูปของคุณมีแค่งานเบาๆ เช่น
data[i] = i * 2;การใช้Parallel.Forอาจจะ “ช้ากว่า”forธรรมดาด้วยซ้ำ! (คุณอาจต้องไปศึกษาการใช้Partitionerเพิ่มเติมเพื่อจัดกลุ่มงานให้ใหญ่ขึ้น)
6. 🏁 บทสรุป (To be continued…)
Data Parallelism ผ่าน Parallel.For และ Parallel.ForEach คืออาวุธที่ทรงพลังที่สุดในการปลดแอกประสิทธิภาพของ CPU ยุคใหม่ แต่มันก็เหมือนดาบสองคม หากคุณลืมตรวจสอบความสัมพันธ์ (Dependencies) ของตัวแปรภายในลูป มันก็พร้อมจะสร้างบั๊กที่หาตัวจับยากที่สุดให้คุณปวดหัวได้เช่นกันครับ
ในบทต่อไป เราจะมาเจาะลึกปัญหาสุดคลาสสิกที่ผมเกริ่นไว้ นั่นคือ “ถ้าเราต้องการเอา Parallel Loop มาหาผลรวม (Sum) หรือรวบรวมข้อมูล โดยไม่ให้เกิด Race Condition เราจะต้องทำอย่างไร?” เตรียมพบกับวิชา Parallel Aggregation กันได้เลยครับ!
ต้องการที่ปรึกษาด้านการออกแบบสถาปัตยกรรมซอฟต์แวร์และการจัดการระบบ Concurrency ประสิทธิภาพสูงให้กับองค์กรของคุณ? ทีมงาน WP Solution พร้อมให้บริการออกแบบและพัฒนาซอฟต์แวร์แบบครบวงจร ดูรายละเอียดบริการของเราได้ที่: www.wpsolution2017.com หรือพูดคุยปรึกษาเบื้องต้นได้ที่ Line: wisit.p